VelcroBP
Members
-
Joined
-
Last visited
Everything posted by VelcroBP
-
I used SpaceInvaderOne's tutorial and Macinabox to spin up a Big Sur VM. I want to shrink the vDisk but am not sure how. Right now the vDisk is designated 100GB and 29GB shows as allocated. I'm not familiar with macOS or how the Disk Utility manages the volumes, so I don't know what work needs done there before editing the VM image in unRaid.
-
Ok after backing up AppData and documenting all my current container and client settings I decided to try the :libtorrentv1 tag direct from v4.3.9. Now here's where I feel real dumb. I remembered that I was using a custom webUI and thought, "hey I bet that's not compatible or something". Sure enough, I revert to the default webUI, restart the container, then update it, and voila! Now it nuked my settings but they were easy enough to revert. It also nuked any empty categories, but I just recreated them with all their paths. Now I just hope it keeps running stable while I look for a new dark theme.
-
Bumping , please advise on upgrade path. i.e.: What versions between 4.3.9 and latest have major changes that need applied it configured before advancing versions. I want to get this container current before upgrading unRAID. Sent from my Pixel 5 using Tapatalk *Edited because I had the wrong version listed. I'm on 4.3.9 and looking for a safe upgrade path. I'm the meantime I'm reading up on qt6 and libtorrent 1.2 to see if either caused the issues I had trying to upgrade directly.
-
Is there a step-stone approach I need to take to safely upgrade to :latest from v3.3.9? What is the proper way to get current from this old release? I tried to go directly but it blew up my Category/Folder config. Sent from my Pixel 5 using Tapatalk
-
I'm bumping this looking for info on best practice upgrade path to :latest from v3.3.9
-
I'm still looking for info on this. Can a script maybe run on the SLSK download folder to change ownership of all subfolders & files at once?
-
I found this in the support thread and it fixed it for me.
-
Same here. I'm trying to isolate anything unique about Komga. I don't know when it started for me since I was away from home for 3.5 weeks and just tried Komga today.
-
Downloading Wireguard on router and unRAID container using other VPN causing issues? I set up Wireguard on my router to access my server while traveling and so far it is working as expected. however nothing seems to be downloading with qbt-VPN. the container is set up using AirVPN config. it is running and the AirVPN ip is showing with ifconfig. It has Internet access when testing with speedtest-cli. However all downloads added since I setup the Wireguard and left are immediately stalling with no connections. A test of the port forward on AirVPN shows "Connection Refused: 111". Is there something I'm missing that would prevent traffic to or from the container because of the router's Wireguard? Sent from my Pixel 5 using Tapatalk
-
I just installed a Slsk (Nicotine+) container from a Dockerhub pull. It's working great, but it's defaulting all newly created folders & files to 755 so I can't delete or move them when browsing the SMB from my Win11 PC. Can I force the container to apply 775 or 777 instead? Or will I have to manually CHGRP or CHMOD all downloads?
-
Ok my density continues. It was my Diagnostic-Utilities container hung up trying to "rebuild". I had set it to run through the Nicotine container for testing and forgot to update it when I shortened the container name. Derp.
-
As the titles says. This just started this afternoon after I installed a new container (Nicotine+), and configured it to route through a Binhex-qbt-VPN container. I did have to go through serval botched attempts because I was being dense and overlooking the VPN_INPUT_PORTS field so I couldn't get the new webUI up. No they seem to be running as expected but my Docker tab won't stop refreshing and is quite laggy. I've tried rebooting the server with no luck, as well as stopping those individual containers. Here is the issue docker tab.mp4
-
[SOLVED] I found the resolution in another thread pointing to the github instructions, question #24, instruction to add the webUI port to VPN container's VPN_INPUT_PORTS variable. I have another container (Nicotine+} routed through binhexQBT. The logs indicate it is successfully connecting to the web and logging in fine. However I'm unable to access the webui using SERVERIP:PORT. I have the port added to the BinhexVPN container and removed from the Nicotine template. Sent from my Pixel 5 using Tapatalk
-
Now I feel dumb. I had both in the config on the wireguard side and completely overlooked adding on this end! Thanks that did the trick!
-
qbt - docker_compose.txt
-
I have both LANs defined in allowed-ips already. i can hit other services using IP:PORT just not the qbtVPN container. from other devices on the same LAN as the server i can bring it up by IP:PORT. I can also access the smb shares via SolidExplorer when I'm in via wireguard. Sent from my Pixel 5 using Tapatalk
-
I'm trying to do the same. In my case when I connect to my home router via WireGuard (on the router not unRaid) I am able to access any other local service icontainers except this one running behind it's own VPN. I don't know how to configure so it's also available to the wireguard connection.
-
I need help with an upgrade path. I am running a container on unRaid v6.11.5. For quite a while I was holding at QBT v4.3.9 due to an error with one of the early 4.4.x builds. I don't even recall what it was specifically. Today I read that a site I use will possibly be removing 4.3.x from their whitelist. So, having read that 4.5.2-x has resolved the webUI exploit, I went ahead and removed the version tag from the template's docker pull. This was a mistake, as the resulting webUI was unreadable (see screenshot). I panicked, and tried rolled back to 4.4.5-2-02. This displays correctly, but many of my Categories were missing. All custom save paths for the remaining Categories are missing or wrong also. I replaced the categories.json from my original 4.3.9 install, but no change. Privoxy was also not accepting connections with this version running. I have rolled back to v4.3.9-2-01 and everything seems to have reverted to the way I had it. All Categories and custom paths are restored. So, is there a step-stone approach I need to take to safely upgrade to :latest from v3.3.9? What is the proper way to get current and not blow up my Category/Folder config? **Side note: I first tried to replicate the missing Categories on v4.4.5. But I realized I don't remember how I set it up so it functions as follows: Files added to QBT from the *ARR apps are given a Category based on the app. They are downloaded into that Category's folder (/downloads/*ARR/ When finished and imported by the *ARR, the hard-linked /downloads/ files are moved into a new folder, /downloads/*ARR-imported/. It is step 3 I can't recall, nor find the guide I followed to set it up. below is the display problem when I tried :latest
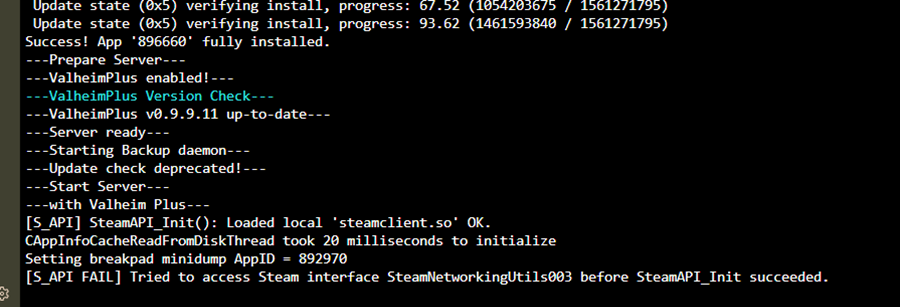
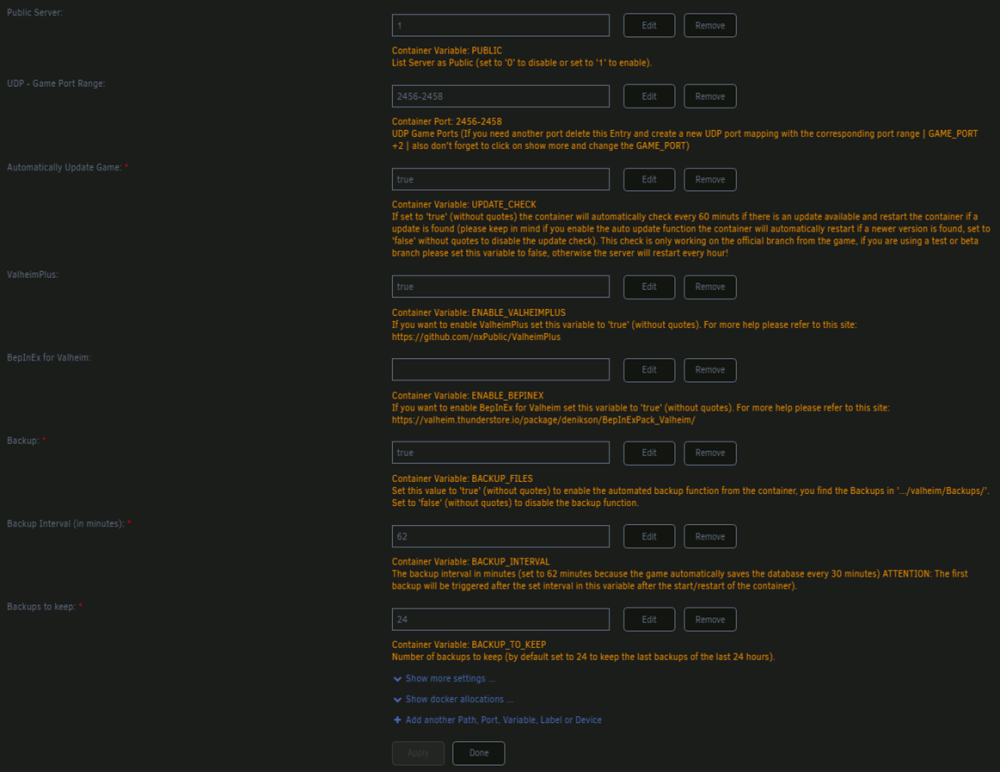
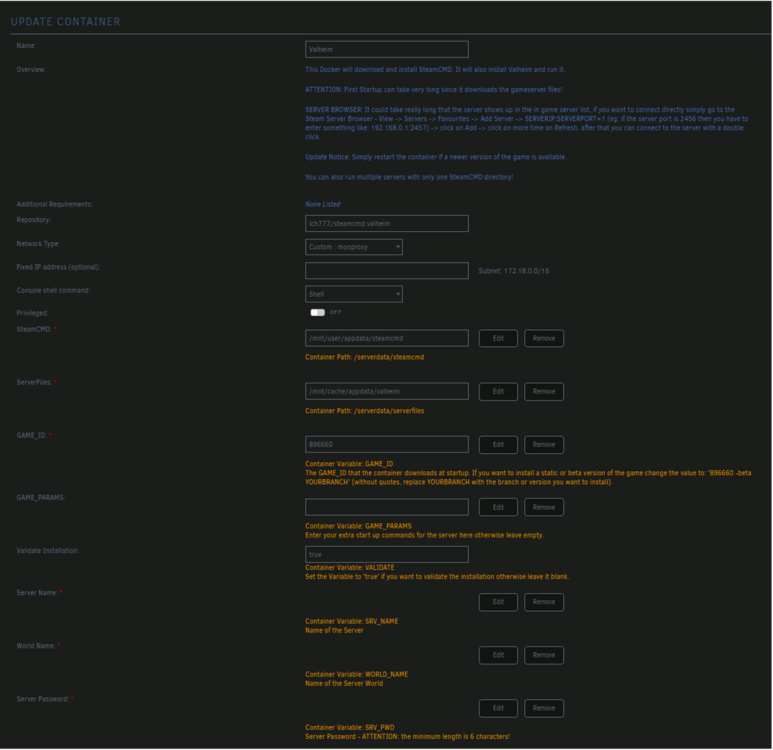
I'm looking to add a script in a container that needs to pull the current size of the cache disk. The example I'm working from assumes it's pointing at the space available to the /downloads/ folder. But in this case wouldn't that return the whole array? Can I instead somehow pass through a mapping to reference that would return the available space of the cache disk instead? Would pointing to the /appdata/ folder or the specific applications /appdata/config/ work, since it is already mapped in the container? Here is the example I'm working from: #!/bin/sh set -e reqSpace=250000000 # 250GB SPACE=$(df "/torrents" | awk 'END{print $4}') if [ "$SPACE" -le $reqSpace ] then echo "not enough space" echo "free $SPACE" exit 1 fi echo "got space" echo "free $SPACE" exit 0Ok I realize now why I can't proxy the game traffic through the CF tunnel like I do with HTTP/HTTPS traffic. That said, what is the best way to allow access via the domain name rather than my IP directly via CF free tier? Is it ok to add an A record pointing to my public IP, then forward those ports on my router to unRaid? Is this too exposed?I am planning on having friends connect once I get it working. I've been running everything through the domain that I access on my server externally. I did a fresh, vanilla install as suggested and can verify I am able to connect from the client PC when launched via Steam directly. I will do further testing with the mods now that I know it's working properly vanilla. Thank you!Though it is no longer in a restart loop, I am unable to connect from my gaming PC. I get "Failed to connect". I've tried: 1. using the local network IP (192.168.1.175:2456) 2. connecting via domain -- I've created a CNAME at my domain (via cloudflare) and a matching proxy host in the NPM container on unRaid. 3. Disconnected VPN on my gaming PC 4. I am using R2ModMan on the gaming PC, and I have tried launching both Vanilla and Modded (with only BepInEx enabled)Confirmed! It is no longer restarting when ValheimPlus is disabled. I enabled just BepInEx instead and it seems to be working also. Thanks!Valheim container in a restart loop every 10 seconds or so. I just installed with mostly default settings. My AppData share is already set to: Prefer: Cache. I was able to capture the log output just before it closes and restarts. Is this the relevant bit? [S_API FAIL] Tried to access Steam interface SteamNetworkingUtils003 before SteamAPI_Init succeeded Here is the screenshot of the log just before it restarts: And here is my template: