Leaderboard


.thumb.jpg.0c644260dacbdbc011d7ad8ba9a1c10a.jpg)
Popular Content
Showing content with the highest reputation on 03/27/20 in all areas
-
EDIT (March 9th 2021): Solved in 6.9 and up. Reformatting the cache to new partition alignment and hosting docker directly on a cache-only directory brought writes down to a bare minimum. ### Hey Guys, First of all, I know that you're all very busy on getting version 6.8 out there, something I'm very much waiting on as well. I'm seeing great progress, so thanks so much for that! Furthermore I won't be expecting this to be on top of the priority list, but I'm hoping someone of the developers team is willing to invest (perhaps after the release). Hardware and software involved: 2 x 1TB Samsung EVO 860, setup with LUKS encryption in BTRFS RAID1 pool. ### TLDR (but I'd suggest to read on anyway 😀) The image file mounted as a loop device is causing massive writes on the cache, potentially wearing out SSD's quite rapidly. This appears to be only happening on encrypted caches formatted with BTRFS (maybe only in RAID1 setup, but not sure). Hosting the Docker files directory on /mnt/cache instead of using the loopdevice seems to fix this problem. Possible idea for implementation proposed on the bottom. Grateful for any help provided! ### I have written a topic in the general support section (see link below), but I have done a lot of research lately and think I have gathered enough evidence pointing to a bug, I also was able to build (kind of) a workaround for my situation. More details below. So to see what was actually hammering on the cache I started doing all the obvious, like using a lot of find commands to trace files that were written to every few minutes and also used the fileactivity plugin. Neither was able trace down any writes that would explain 400 GBs worth of writes a day for just a few containers that aren't even that active. Digging further I moved the docker.img to /mnt/cach/system/docker/docker.img, so directly on the BTRFS RAID1 mountpoint. I wanted to check whether the unRAID FS layer was causing the loop2 device to write this heavy. No luck either. This gave me a situation I was able to reproduce on a virtual machine though, so I started with a recent Debian install (I know, it's not Slackware, but I had to start somewhere ☺️). I create some vDisks, encrypted them with LUKS, bundled them in a BTRFS RAID1 setup, created the loopdevice on the BTRFS mountpoint (same of /dev/cache) en mounted it on /var/lib/docker. I made sure I had to NoCow flags set on the IMG file like unRAID does. Strangely this did not show any excessive writes, iotop shows really healthy values for the same workload (I migrated the docker content over to the VM). After my Debian troubleshooting I went back over to the unRAID server, wondering whether the loopdevice is created weirdly, so I took the exact same steps to create a new image and pointed the settings from the GUI there. Still same write issues. Finally I decided to put the whole image out of the equation and took the following steps: - Stopped docker from the WebGUI so unRAID would properly unmount the loop device. - Modified /etc/rc.d/rc.docker to not check whether /var/lib/docker was a mountpoint - Created a share on the cache for the docker files - Created a softlink from /mnt/cache/docker to /var/lib/docker - Started docker using "/etc/rd.d/rc.docker start" - Started my BItwarden containers. Looking into the stats with "iotstat -ao" I did not see any excessive writing taking place anymore. I had the containers running for like 3 hours and maybe got 1GB of writes total (note that on the loopdevice this gave me 2.5GB every 10 minutes!) Now don't get me wrong, I understand why the loopdevice was implemented. Dockerd is started with options to make it run with the BTRFS driver, and since the image file is formatted with the BTRFS filesystem this works at every setup, it doesn't even matter whether it runs on XFS, EXT4 or BTRFS and it will just work. I my case I had to point the softlink to /mnt/cache because pointing it /mnt/user would not allow me to start using the BTRFS driver (obviously the unRAID filesystem isn't BTRFS). Also the WebGUI has commands to scrub to filesystem inside the container, all is based on the assumption everyone is using docker on BTRFS (which of course they are because of the container 😁) I must say that my approach also broke when I changed something in the shares, certain services get a restart causing docker to be turned off for some reason. No big issue since it wasn't meant to be a long term solution, just to see whether the loopdevice was causing the issue, which I think my tests did point out. Now I'm at the point where I would definitely need some developer help, I'm currently keeping nearly all docker container off all day because 300/400GB worth of writes a day is just a BIG waste of expensive flash storage. Especially since I've pointed out that it's not needed at all. It does defeat the purpose of my NAS and SSD cache though since it's main purpose was hosting docker containers while allowing the HD's to spin down. Again, I'm hoping someone in the dev team acknowledges this problem and is willing to invest. I did got quite a few hits on the forums and reddit without someone actually pointed out the root cause of issue. I missing the technical know-how to troubleshoot the loopdevice issues on a lower level, but have been thinking on possible ways to implement a workaround. Like adjusting the Docker Settings page to switch off the use of a vDisk and if all requirements are met (pointing to /mnt/cache and BTRFS formatted) start docker on a share on the /mnt/cache partition instead of using the vDisk. In this way you would still keep all advantages of the docker.img file (cross filesystem type) and users who don't care about writes could still use it, but you'd be massively helping out others that are concerned over these writes. I'm not attaching diagnostic files since they would probably not point out the needed. Also if this should have been in feature requests, I'm sorry. But I feel that, since the solution is misbehaving in terms of writes, this could also be placed in the bugreport section. Thanks though for this great product, have been using it so far with a lot of joy! I'm just hoping we can solve this one so I can keep all my dockers running without the cache wearing out quick, Cheers!1 point
-
Yoiu can have 1x 500GB as cache and mount the other as unassigned device. That way you can separate write-heavy data (e.g. your download temp files). That will improve the lifespan of both SSDs.1 point
-
Thanks to @bonienl this is coming in 6.9 release!1 point
-
Probably more than enough if you're careful how you use it. Many people seem to not give any thought to how they use cache, and just try to cache everything all the time. Don't cache the initial data load since cache won't have the capacity to hold it all, and it is impossible to move from cache to the slower array as fast as you can write to cache. Mover is intended for idle time. Your appdata, domains, and system shares belong on cache and should stay there (and will unless you change their settings or fill cache up). This is so your dockers and VMs won't have their performance impacted by the slower parity writes, and so they won't keep array disks spinning. I have a similar capacity in my cache pool. I cache very little. My dockers as noted, and my plex DVR since there is some benefit to SSD speed when trying to record and playback at the same time. Most of my other writes are scheduled backups and queued downloads, so I don't care if they take a little longer to write since I am not waiting on them. They go directly to the array where they are already protected by parity. Other people will have other use cases, but the main point is, think about it instead of caching everything all the time.1 point
-
@fr05ty @glennv I update the git repo(add MCEDisabler) and tested it in 10.15.4, it's all fine. Did you add Lilu/WEG/AppleALC to your kexts folder and enable it in config.plist? Did you put all others things under repo EFI to your EFI folder?(Because from your logging, the ACPI staffs is missing)1 point
-
I tested with 2 gpus and it works There's a screenshot of it in this article: https://blog.linuxserver.io/2020/03/21/covid-19-a-quick-update/ By the way, you don't need to edit the config at all (in fact, don't). If you allow both gpus via nvidia arguments, they'll both be used automatically.1 point
-
You forgot "--runtime=nvidia"1 point
-
1. Audio feedback from motherboards buzzer. Example when a hardrive fails, parity-check fail. Or when someone loges into the systems etc. 2. Automatic server shutdown. Example if the system have no VMs or dockers running for longer than 15min the server shuts off by itself. 3. Consider trying to implement the “Looking Glass” vm-technology. If I have understood correctly…. Looking Glass makes it possible to retrieve frame-buffer from a vm’s dedicated gpu and display it in on the host machine with almost no overhead or delay.1 point
-
Doesn't pgadmin listen on port 80?1 point
-
There is not (and never will be) any guarantee for a drive to be assigned a particular sdX name at boot time. It's all dependent upon the order in which the drives enumerate themselves. They do tend to not change if you don't add / remove drives though (but no guarantee) If you're scripting all this then you would have to extract the appropriate designation for the drive from /var/local/emhttp/disks.ini1 point
-
Kinda interesting since this morning my large server with dual 2GHz processors has been at an idle while connected to the Rosettta@home client. I restarted the docker to make sure nothing broke and after it connected again it is still not being utilized. My faster machines are still hard at work leading me to believe that they now have so much surplus of available machines they now may be utilizing only the faster equipment in the pool. This is a good thing and more than enough in this effort is a blessing. If I don't see activity by tomorrow I may assign the slower server to another service so it too will be getting used in a productive way. Either way I'm tickled that our group has shown so much compassion and human spirit in this crisis.1 point
-
Rock solid. No instability to speak of. I'm running an older F12e BIOS due to issues I reported on page 3 about F12i BIOS. There is the latest F12 (no "e" nor "i") BIOS which I can't be bothered to update to since as mentioned, everything is rock solid. For a primarily gaming build, I would recommend you also consider Intel single-die CPU offering too. While having lower maximum performance, Intel single-die design means you get more consistent gaming performance (e.g. lower latency, less fps variability aka stuttering etc.). My VM is workstation-first, gaming-second (and I can't tell the diff with fps variability but I know someone who can) so TR is perfect for me.1 point
-
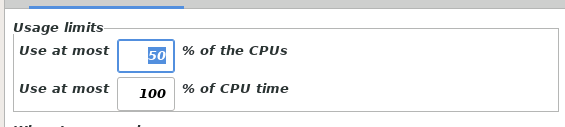
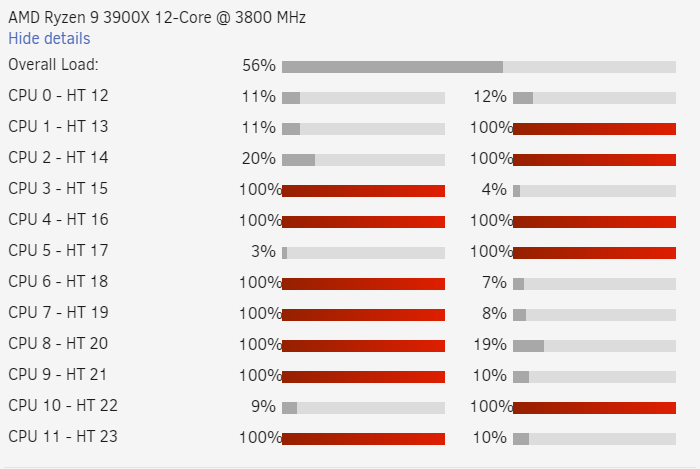
Some considerations on using the BOINC docker for Rosetta@Home. Performance and Memory concerns. BOINC defaults to using 100% of the CPUs. Also, by default, Rosetta will process 1 task per cpu core/thread. So if you have an 8 core machine (16 with HT) it will attempt to process 16 tasks at once. Even if you set docker pinning to specific cores, the docker image will see all available cores and begin 1 task per core/thread. If you want to limit the number of tasks being processed, change the setting for using % of CPUs. So using the 8 core machine example above, setting it to 50% would process 8 tasks at a time. Regardless of how you set up CPU pinning. RAM and out of memory errors. Some of the Rosetta jobs can consume a lot of RAM. I have noticed individual tasks consuming anywhere between 500Mb-1.5Gb of RAM. You can find the memory a task is using by selecting the task, and clicking the properties button. If the task runs out of memory, it may get killed, wasting the work done or delaying it. It is helpful to balance the number of tasks you have running to the amount of RAM you have available. In the example machine above, if I am processing 8 tasks, I might expect the RAM usage to be anywhere from 4Gb to 10Gb. The docker FAQ has instructions on limiting the amount of memory the docker container uses, but be aware that processing too many tasks and running out of memory will just kill them and delay processing. My real world example. CPU: 3900X 12-core (24 w/ Hyperthreading) RAM 32GB Usage limit set to 50%, so processing only 12 tasks at a time. RAM limited to 14G, I could go a little higher, but havent needed to. Most tasks stay under 1Gb CPU pinning to almost all available cores Actual CPU usage looks like Since putting those restrictions on, I have had very stable processing and no out of memory errors.


 1 point
1 point -
Hi, sorry forgot to reply. I used all M.2 slots, all PCIe slots and all SATA ports at one point in the past so I can confirm. M.2 NVMe does not disable SATA ports. M.2 NVMe also does not disable any PCIe slot (and vice versa). The whole point of getting Threadripper is the number of PCIe lanes so whether I would recommend the board or not depends on how many PCIe lanes you need. For example, I have a rather unusual number of NVMe drives compared to a typical user so I do need all of those lanes.1 point
-
Absolutely fantastic! Thank you very much!1 point
-
Hey man, If you reboot your server everything will be reset to default and unRaid will mount the normal docker image upon boot. Assuming you've created the share which I've mentioned, then docker won't be able to see those, since they work created on the path targeted by the symlink and not inside the docker.img file. So it will see/start whatever container you have created into the docker image, or nothing if you created a new one before starting to work with the symlink approach. I've read though my posts real quick and noticed I have not yet provided my final solution, so let me share that. Basically what I did was: Create a share named docker (which has to be cache only or this will break after the mover kicks in!) Created a directory "docker-service-mod" at /boot/config/, which will obviously survive a reboot since it's on flash. --> command: mkdir /boot/config/docker-service-mod Copied the original rc.docker file to flash also (this allows me to easily check if the unRaid devs have made a change in a later version if my docker service fails all of a sudden). --> command: cp /etc/rc.d/rc.docker /boot/config/docker-service-mod/rc.docker.original Remove the rc.docker file --> command: rm /etc/rc.d/rc.docker Create a new /etc/rc.d/rc.docker file with everything that was in the other one, but replace the docker_start() function with a custom one (as defined code block below). To get this on unRaid you have multiple ways. You could use vi to edit the function directly the file at /etc/rc.d/rc.docker (vi has funky syntax though if you're not a regular vi user, I believe unRAID also has nano installed which is more user friendly for non-vi users) . You can also create a file named rc.docker locally (on Windows for example), copy the content of the original rc.docker file in it, make the changes to the start_docker() function and use WinSCP to copy it to /etc/rc.d/. If you copy it from Windows, make it executable with "chmod +x /etc/rc.d/rc.docker" (not sure if it's needed, but setting the execute bit on there won't hurt for sure here, since it's a script) # Start docker start_docker(){ if is_docker_running; then echo "$DOCKER is already running" return 1 fi if mountpoint $DOCKER_ROOT &>/dev/null; then echo "Image is mounted, will attempt to unmount it next." umount $DOCKER_ROOT 1>/dev/null 2>&1 if [[ $? -ne 0 ]]; then echo "Image still mounted at $DOCKER_ROOT, cancelling cause this needs to be a symlink!" exit 1 else echo "Image unmounted succesfully." fi fi # In order to have a soft link created, we need to remove the /var/lib/docker directory or creating a soft link will fail if [[ -d $DOCKER_ROOT ]]; then echo "Docker directory still exists, removing it so we can use it for the soft link." rm -rf $DOCKER_ROOT if [[ -d $DOCKER_ROOT ]]; then echo "$DOCKER_ROOT still exists! Creating a soft link will fail thus refusing to start docker." exit 1 else echo "Removed $DOCKER_ROOT. Moving on." fi fi # Now that we know that the docker image isn't mounted, we want to make sure the symlink is active if [[ -L $DOCKER_ROOT && -d $DOCKER_ROOT ]]; then echo "$DOCKER_ROOT is a soft link, docker is allowed to start" else echo "$DOCKER_ROOT is not a soft link, will try to create it." ln -s /mnt/cache/docker /var/lib 1>/dev/null 2>&1 if [[ $? -ne 0 ]]; then echo "Soft link could not be created, refusing to start docker!" exit 1 else echo "Soft link created." fi fi echo "starting $BASE ..." if [[ -x $DOCKER ]]; then # If there is an old PID file (no docker running), clean it up: if [[ -r $DOCKER_PIDFILE ]]; then if ! ps axc|grep docker 1>/dev/null 2>&1; then echo "Cleaning up old $DOCKER_PIDFILE." rm -f $DOCKER_PIDFILE fi fi nohup $UNSHARE --propagation slave -- $DOCKER -p $DOCKER_PIDFILE $DOCKER_OPTS >>$DOCKER_LOG 2>&1 & fi } Copy the new rc.docker file to flash. --> command: cp /etc/rc.d/rc.docker /boot/config/docker-service-mod/rc.docker Modify the /boot/config/go file, so that unRaid injects the modified version of the rc.docker file into the /etc/rc.d/ directory before starting emhttp (which will also start docker). I used vi for that. My go file has several other things in it, but the relevant part is below. The chmod +x command might not be necessary cause it worked also before I used it, however I feel more comfortable knowing it explicitly sets the execution bit: #!/bin/bash # Put the modified docker service file over the original one to make it not use the docker.img cp /boot/config/docker-service-mod/rc.docker /etc/rc.d/rc.docker chmod +x /etc/rc.d/rc.docker # Start the Management Utility /usr/local/sbin/emhttp & I've been using this for a while and have been very happy with it so far. Be aware though that this might break one day if Limetech decides that the rc.docker script should be modified (which is why I keep a copy of the original one like mentioned). It could also break if Limetech steps away from the Go file. Simple thing you can do is recreate the docker.img file from the GUI before you take the steps above (this will destroy each container and also any data that you have not made persistent!), then if a future update breaks this, you'll have no docker container running (since docker is started on a blank image). You should be aware of this pretty quick. Only one side effect of this approach I was able to determine is that opening the docker settings page takes a while to load, cause the GUI tries to run some commands on the BTRFS filesystem of the image (which is not there anymore). This will freeze up the settings page for a bit and push some resource usage in one CPU core until that command times out. Not a deal breaker for me, if you want to turn off docker, then simple wait until the command times out and reveals the rest of the page (without BTRFS status info). Good luck!1 point
-
I use ln. Let's say you want to point /mnt/cache/personal/doc to /mnt/disks/ssd/documents then do: ln -sv /mnt/disks/ssd/documents /mnt/cache/personal/doc Unlike mount, it's important that you don't have a folder called "doc" at /mnt/cache/personal or the command will create a documents symlink under /mnt/cache/personal/doc (i.e. it would become /mnt/cache/personal/doc/documents). I like symlinks for simple stuff since I just have to do it once and it persists across reboots. I think bind mount needs to be redone after reboot. But then Plex db has a lot of links too (if I remember correctly) so you might not be able to use symlink with it. With dockers though, I just point the path directly to the location in the docker config. I find that even more straightforward.1 point
-
Update; I switched to the AIO container and things seem to be working again. I didn't make any changes to the standalone container configs, so I am not sure why it started having issues, but the AIO is operating fine! Great Job @HaveAGitGat !1 point
-
I believe I solved my issue - I had forgotten to set the transcoder cache folder in the tdarr webui.1 point
-
Any advice as to how to get this working with mullvad VPN would be really appreciated. Edit: I figured it out. Select custom for the VPN Username and password are both your user number. Put unzip the files you generate on the Mullvad site and put them in \appdata\binhex-qbittorrentvpn\openvpn Rename the .conf file as .opvn That got me up and running.1 point
-
Hi, How do I go about adding the above to my Wireguard config? Same question with a killswitch. I'm using Mullvad which provides a killswitch in their config file but when I import the config the parser removes it. The Mulvad config looks like this [Interface] PrivateKey = -hidden- Address = 10.64.246.232/32,fc00:bbbb:bbbb:bb01::1:f6e7/128 DNS = 193.138.218.74 PostUp = iptables -I OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT && ip6tables -I OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT PreDown = iptables -D OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT && ip6tables -D OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT [Peer] PublicKey = -hidden- AllowedIPs = 0.0.0.0/0,::0/0 Endpoint = 103.231.88.2:51820 Once imported it looks like this [Interface] PrivateKey= -hidden- Address=10.64.246.232 PostUp=logger -t wireguard 'Tunnel WireGuard-wg0 started' PostDown=logger -t wireguard 'Tunnel WireGuard-wg0 stopped' [Peer] PublicKey= -hidden- Endpoint=103.231.88.2:51820 AllowedIPs=0.0.0.0/0,::0/0 Also note that unless I manually remove ,::0/0 from the allowed IPs the tunnel will not connect1 point
-
Ok so I just added a path in the Krusader container settings (attached), restarted the container, and that seemed to solve the issue.
.png.63ff8d13d4e97ace36c2682f089fdfe3.png) 1 point
1 point -
i found changing the memory allocation resolved this1 point
-
I had to stop and pop some corn and continued reading...1 point















.png.63ff8d13d4e97ace36c2682f089fdfe3.png)

