




Shantarius
Members
-
Joined
-
Last visited
Everything posted by Shantarius
-
Great, it worked. I can log into Steam again. Thank you!
-
Hello @ich777 my LanCache-Prefill Docker Container does not connect to Steam anymore: [12:54:37 PM] Already disconnected from Steam SteamPrefill.Models.Exceptions.SteamConnectionException: Timeout connecting to Steam... Try again in a few moments at void SteamPrefill.Handlers.Steam.Steam3Session.ConnectToSteam() at void SteamPrefill.Handlers.Steam.Steam3Session.<>c__DisplayClass16_0.<<LoginToSteamAsync>b__0>d.MoveNext() at void Spectre.Console.Status.<>c__DisplayClass16_0.<<StartAsync>b__0>d.MoveNext() in Status.cs:79 at void Spectre.Console.Status.<>c__DisplayClass17_0`1.<<StartAsync>b__0>d.MoveNext() in Status.cs:120 at void Spectre.Console.Progress.<>c__DisplayClass28_0`1.<<StartAsync>b__0>d.MoveNext() in Progress.cs:133 at async Task<T> Spectre.Console.Internal.DefaultExclusivityMode.RunAsync<T>(Func<Task<T>> func) in DefaultExclusivityMode.cs:40 at async Task<T> Spectre.Console.Progress.StartAsync<T>(Func<ProgressContext, Task<T>> action) in Progress.cs:116 at async Task<T> Spectre.Console.Status.StartAsync<T>(string status, Func<StatusContext, Task<T>> func) in Status.cs:117 at async Task Spectre.Console.Status.StartAsync(string status, Func<StatusContext, Task> action) in Status.cs:77 at async Task SteamPrefill.Handlers.Steam.Steam3Session.LoginToSteamAsync() at async Task SteamPrefill.SteamManager.InitializeAsync() at async ValueTask SteamPrefill.CliCommands.SelectAppsCommand.ExecuteAsync(IConsole console) at async ValueTask<int> CliFx.CliApplication.RunAsync(ApplicationSchema applicationSchema, CommandInput commandInput) in CliApplication.cs:148 at async ValueTask<int> CliFx.CliApplication.RunAsync(IReadOnlyList<string> commandLineArguments, IReadOnlyDictionary<string, string> environmentVariables) in CliApplication.cs:190 at async ValueTask<int> CliFx.CliApplication.RunAsync(IReadOnlyList<string> commandLineArguments) in CliApplication.cs:202 at async Task<int> SteamPrefill.Program.Main() The Version in this Docker is 2.5 but the official version ist newer (2.7.). Can this be a reason for connecting problems? Best regards, Chris
-
Hello, since a few days mover logs some errors to the syslog: Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjE5Y2NiODUyZmI5NmQzMmQxMTk1OWE1OTMxZTUxMDEwNjYwZDNjZmE2MjIzZTU1MDk5Mzc1MTFmMzg5YjM0Y2YiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjVmNzNjYWFmMjNlZjY5Y2UxODZmZDk2MzJmNjBhZTBmMjRkNmFiYmRmNTllMTc4MDE4ZTI0NzRjN2M4NTdjOTYiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImMwYzZkMzBmMzE1NjUwNzAzOWE1OWU0ZmViYTZhMDJkZjg1MzI5YmM1MTllM2FmZDlmZjQ2N2QyYjI4NTVjMzYiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImVhZTVjMzUzNDgxZGZlNDNkNTg3ODhkZWVmNGNkYmIwY2YyNTgwMDA2ZWYwY2Q1YTYxOTk4Y2NhYmNiOWRiY2MiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImYwNzdiMzEwYTA2OTEzZTFkOWI4NjJiYjk2MDgwNzU5NDJiZjZlMzViYjY4MzA4MjI3NWM2YWI3MjVhMjBkNmYiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjI2NGRkZGRlMjUyMjJhYTBkZGNkNTQ4NWQ3MDI1NTU1N2NiMDlkYzkxNzQzOTc1NDczMDQ3NjQzNmU1MzkxZDUiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImY4NjA0NjliZjA2YzhhZjA3MmUzNmY2OWQ3OWJhMjUwNjdjZmIyOWU5MGViMzJmMjJlNzhiZWIyNDQwNGMyZTIiLCJ3Ijo2MDAsImgiOjMwMCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjNkNjNkOTYwYTA2M2E0NTc2ZjFiZGNlNTY3MDZmOTQxNmI5MTkyNTk3ZWZjODA2ODM5YTA1YmMzMTkyNmYyYWMiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjRjYWI0ZmNmYmE0OTQ4MWQzNTI3MGRlMDEwYWNkOTUwM2E1NjIyNjA2YzZiYzE1MTk2YzFlOTE1MGI4NjljNTIiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImMxZmI4NDc2MzYwMDFhOWEyYjZjNzI3NTU3ZDc2MzgyOTRjMmRiNGZhZmI3OTFiZjljZjUzYzc4MmQzMmFmZTUiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImQ2OGYyZGVjZTk0ZmIyOTUwZjczODQ0MzFiODNlN2FjZTlhNTYwYzk4Zjc2MGVkNThjYjU2Yzk1MWYyZDIwZTQiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 698CE5D95430B9436F0978533BDA592567988C92C2932B1F451E9415C515418CD9EEE167A9ADDFB367A373FA810E2AB3B330B8C7DF498C563B6F874C9CFDD5F5 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjJmMGUwYjkwNWI3ZjNlNTcyYjJiM2Y0ZTRhMTA4ODM1NmMzOTY3ODQzYzM1OWY5YTA3MjI0ZjY2YjhmYjQ3NjUiLCJ3Ijo2MDAsImgiOjMwMCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjRkOWI5YTBkOGIzNWI1YTY1NmJkMDJmMjhjZGNjZWRmMGRlMGRjN2FkZDIwZmU2ZDNmYjc4YTc0ZDc3YTdlOWMiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjU3YzY2ZWNjZDRjZTljYWU3ZDllMzBiZGI3OTNkOGY2M2M5NWI4NTMzM2NiOTUxZDljODI2ODAwMDkzOGRlNzkiLCJ3IjozMDAsImgiOjE3MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjEyNDljNmQ5OWYwODBmMTFhNjlhMmM4MDQzOWU4YTQ3M2UwNjhlMTg3ZDkyYTBkYWQzZDdjNDNhZTJjODc0ZjAiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjdmNzE5ZWU0NmM0MDZmOWIyMDQ4NjdmZTY5YzE4YmMyZWQ1ODY4ZmVjMGY5MzlhYmRmNGIwOTEyZDgzMTNjODQiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6IjJjZjIyYTdiYjA2ZDc1MGRmYmQ2NDAxMzJjNTQ5NWVlY2EyMmJlNWE2NzY0NDUwNzg1NjEwYjk0NTJjYTZiZGUiLCJ3Ijo2MDAsImgiOjMwMCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: eyJpdSI6ImRmNDNmNDA2ZjljOTNlOGNmNTliODBkNTNiYjlmNDcyOTllNWFhMDAyMzFhZWU5MGM2MWEzNGMwYjllYzRmMWMiLCJ3IjozMDAsImgiOjE1MCwiZCI6MS41LCJjcyI6MCwiZiI6MH0.jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .jpg Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f7472617669732d63692e6f72672f6b6d706d2f6e6f64656d63752d75706c6f616465722e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f7472617669732d63692e6f72672f6176656e6461656c2f61746f6d69632d656d6163732e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f7472617669732d63692e6f72672f6b6d706d2f6e6f64656d63752d75706c6f616465722e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f7472617669732d63692e6f72672f7468656d6164696e76656e746f722f657370746f6f6c2e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f636f6465636f762e696f2f6769746875622f657370383236362f41726475696e6f2f636f7665726167652e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: 68747470733a2f2f636f6465636f762e696f2f6769746875622f657370383236362f41726475696e6f2f636f7665726167652e7376673f6272616e63683d6d6173746572 Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .dms Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: UnkPcAIhUm5TawMwACFSP1diB2VRYAU1V2cAaFRvCTQJa1YzUikBeQBgC3RXOlBeAHdVdQxmUGJWJQcSXjMAclM_VXgKI1h6DmcCYVIpD2FSOg9rAmBSNFM-A3kAMlJYVy4undefined.gif Dec 28 04:00:34 Avalon move: error: move, 392: No such file or directory (2): lstat: .gif Can anyone please help me to solve this problem? Thank you! Chris
-
Hello, in my syslog I have >15000 Entries like this: Oct 17 05:52:51 Avalon bunker: error: BLAKE3 hash key mismatch, /mnt/disk1/Backup_zpool/zpool/nextcloud_data/20231007_031906/nextcloud_data/christian/files/Obsidian_Vault/.git/objects/ba/edc24a7db2d2f8cc372d12a6cfaa5a7b3b9206 is corrupted At 10th Oktober the same for disk3. What is happened here and how can I solve this? Thanks!
-
Works this only with Unpaid >=6.12?
-
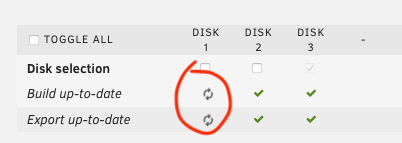
Hello, what is with this spinning symbol meant?
-
I think the Problem was that the Unraid Samba Service and the Timemachine Samba Service had the same workgroup name. I have changed the workgroup name for the Container and now it is all ok.
-
Bei Hetzner bekommt man 1TB Cloud Speicher für 3,81€ Da kannst Du Deine Daten per WEBDAV, SFTP, SSH usw hochladen. Je nach verwendeter Software auch verschlüsselt. Hetzner hostet in Deutschland und Finnland, kannst Du Dir aussuchen. Also in Deutschland. Ich nutze dann für das Backup meiner Daten den Duplicati Docker. Damit kannst Du die Daten auch vollverschlüsselt hochladen. Duplicati gibt es auch für Windows, MacOS und separat für Linux. Das heisst im Notfall kannst Du die hochgeladenen Daten mit jedem OS und dem entsprechenden Duplicati Binary wieder herunterladen. Dazu hast Du mit Duplicati eine ordentliche (Web)Gui und musst nicht mit Scripten rummachen. 7TB Daten in der Cloud zu sichern halte ich aber nicht für sinnvoll. Ich sichere in der Cloud nur das allerwichtigste, wie mein DMS und andere Dokumente. Andere Nutzdaten landen auf zwei externen Festplatten die regelmäßig rotiert und im Keller in einer wasserdichten und feuerfesten Box gelagert werden.
-
Hi, the Timemachine docker spams into my unraid syslog. How can I prevent for this? Which log level can I use for the container settings (now it is set to 1)? Feb 25 16:05:49 Avalon nmbd[64984]: ***** Feb 25 16:05:49 Avalon nmbd[64984]: Feb 25 16:05:49 Avalon nmbd[64984]: Samba name server AVALON is now a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:05:49 Avalon nmbd[64984]: Feb 25 16:05:49 Avalon nmbd[64984]: ***** Feb 25 16:17:27 Avalon nmbd[64984]: [2023/02/25 16:17:27.047518, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:302(process_local_master_announce) Feb 25 16:17:27 Avalon nmbd[64984]: process_local_master_announce: Server TIMEMACHINE at IP 192.168.2.139 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Feb 25 16:17:27 Avalon nmbd[64984]: [2023/02/25 16:17:27.047676, 0] ../../source3/nmbd/nmbd_become_lmb.c:150(unbecome_local_master_success) Feb 25 16:17:27 Avalon nmbd[64984]: ***** Feb 25 16:17:27 Avalon nmbd[64984]: Feb 25 16:17:27 Avalon nmbd[64984]: Samba name server AVALON has stopped being a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:17:27 Avalon nmbd[64984]: Feb 25 16:17:27 Avalon nmbd[64984]: ***** Feb 25 16:17:47 Avalon nmbd[64984]: [2023/02/25 16:17:47.344230, 0] ../../source3/nmbd/nmbd_become_lmb.c:397(become_local_master_stage2) Feb 25 16:17:47 Avalon nmbd[64984]: ***** Feb 25 16:17:47 Avalon nmbd[64984]: Feb 25 16:17:47 Avalon nmbd[64984]: Samba name server AVALON is now a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:17:47 Avalon nmbd[64984]: Feb 25 16:17:47 Avalon nmbd[64984]: ***** Feb 25 16:29:28 Avalon nmbd[64984]: [2023/02/25 16:29:28.202819, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:302(process_local_master_announce) Feb 25 16:29:28 Avalon nmbd[64984]: process_local_master_announce: Server TIMEMACHINE at IP 192.168.2.139 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Feb 25 16:29:28 Avalon nmbd[64984]: [2023/02/25 16:29:28.202973, 0] ../../source3/nmbd/nmbd_become_lmb.c:150(unbecome_local_master_success) Feb 25 16:29:28 Avalon nmbd[64984]: ***** Feb 25 16:29:28 Avalon nmbd[64984]: Feb 25 16:29:28 Avalon nmbd[64984]: Samba name server AVALON has stopped being a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:29:28 Avalon nmbd[64984]: Feb 25 16:29:28 Avalon nmbd[64984]: ***** Feb 25 16:29:48 Avalon nmbd[64984]: [2023/02/25 16:29:48.037595, 0] ../../source3/nmbd/nmbd_become_lmb.c:397(become_local_master_stage2) Feb 25 16:29:48 Avalon nmbd[64984]: ***** Feb 25 16:29:48 Avalon nmbd[64984]: Feb 25 16:29:48 Avalon nmbd[64984]: Samba name server AVALON is now a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:29:48 Avalon nmbd[64984]: Feb 25 16:29:48 Avalon nmbd[64984]: ***** Feb 25 16:41:30 Avalon nmbd[64984]: [2023/02/25 16:41:30.678485, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:302(process_local_master_announce) Feb 25 16:41:30 Avalon nmbd[64984]: process_local_master_announce: Server TIMEMACHINE at IP 192.168.2.139 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Feb 25 16:41:30 Avalon nmbd[64984]: [2023/02/25 16:41:30.678645, 0] ../../source3/nmbd/nmbd_become_lmb.c:150(unbecome_local_master_success) Feb 25 16:41:30 Avalon nmbd[64984]: ***** Feb 25 16:41:30 Avalon nmbd[64984]: Feb 25 16:41:30 Avalon nmbd[64984]: Samba name server AVALON has stopped being a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:41:30 Avalon nmbd[64984]: Feb 25 16:41:30 Avalon nmbd[64984]: ***** Feb 25 16:41:48 Avalon nmbd[64984]: [2023/02/25 16:41:48.997249, 0] ../../source3/nmbd/nmbd_become_lmb.c:397(become_local_master_stage2) Feb 25 16:41:48 Avalon nmbd[64984]: ***** Feb 25 16:41:48 Avalon nmbd[64984]: Feb 25 16:41:48 Avalon nmbd[64984]: Samba name server AVALON is now a local master browser for workgroup WORKGROUP on subnet 192.168.2.126 Feb 25 16:41:48 Avalon nmbd[64984]: Feb 25 16:41:48 Avalon nmbd[64984]: ***** Thank you!
-
Question about LanCache Prefill I have deselected one Game in SteamPrefill select-apps. Does Lancache Profil deletes automatically the cached Data for this game? What happened if the Drive where the Lancache Cache save the Data is full? Thank You!
-
Dazu benötigt man eine Bitcoin Wallet und die muss dann im Miner konfiguriert werden, oder? Oder wo kommen die Bitcoins dann hin? Kenne mich damit null aus 😱
-
Wow, cool. Thank you! When will the next release coming out? Can you explain what the php warning means? 🙂
-
Hi, since a few days UA Preclear produces php warnings in the syslog. My Unraid Version is 6.9.2 and the UA Preclear Plugin is the newest version. Dec 22 19:45:00 Avalon rc.diskinfo[22433]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 Dec 22 19:45:00 Avalon rc.diskinfo[22433]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 Dec 22 19:45:00 Avalon rc.diskinfo[22433]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 Dec 22 19:45:15 Avalon rc.diskinfo[28229]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 Dec 22 19:45:15 Avalon rc.diskinfo[28229]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 Dec 22 19:45:15 Avalon rc.diskinfo[28229]: PHP Warning: strpos(): Empty needle in /usr/local/emhttp/plugins/unassigned.devices.preclear/scripts/rc.diskinfo on line 413 What mean this php warnings? Thank you! Christian
-
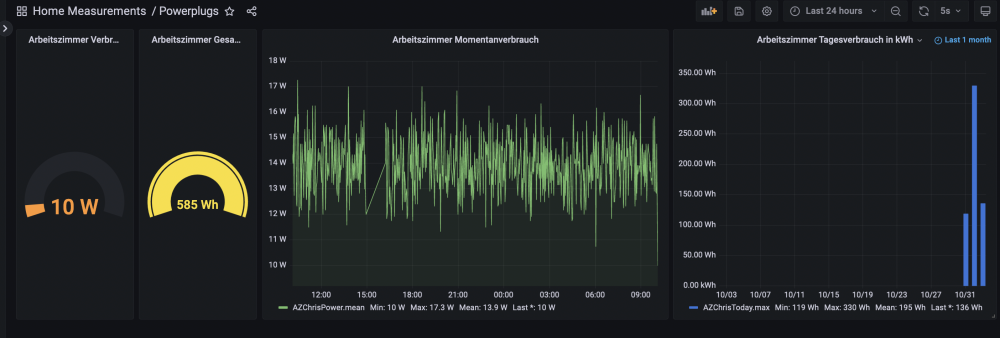
Hi, ich habe mir eine Eaton Ellipse Pro 650 gekauft. Gemessen ohne Verbraucher im eingeschalteten Zustand mit einem Shelly mit Tasmota Firmware. Der Verbrauch schwankt stark, aber im Schnitt Verbraucht das Gerät 14Watt, in 24h insgesamt 330Watt. Das wären bei 30cent/kWh im Jahr 36Euro Leerlaufkosten für die Eaton. Grüße Chris
-
Hi, since a few days i have per day one segfault error in libvirt.so: Oct 9 01:16:16 Avalon kernel: unraid-api[31635]: segfault at 30 ip 00001463a22bb059 sp 000014639bd1de10 error 4 in libvirt.so.0.6005.0[1463a2248000+1f6000] Oct 8 22:47:50 Avalon kernel: unraid-api[46409]: segfault at 30 ip 000014f389aa8059 sp 000014f3732cde10 error 4 in libvirt.so.0.6005.0[14f389a35000+1f6000] Oct 7 12:25:50 Avalon kernel: unraid-api[61384]: segfault at 30 ip 0000152d07c16059 sp 0000152d05523e10 error 4 in libvirt.so.0.6005.0[152d07ba3000+1f6000] Oct 6 05:27:40 Avalon kernel: unraid-api[25216]: segfault at 14eb14023e ip 000014eb2e2bb061 sp 000014eb1fb1ce10 error 4 in libvirt.so.0.6005.0[14eb2e248000+1f6000] Oct 5 09:04:43 Avalon kernel: unraid-api[21661]: segfault at 30 ip 000014e961a94059 sp 000014e95b2b9e10 error 4 in libvirt.so.0.6005.0[14e961a21000+1f6000] Oct 4 22:13:27 Avalon kernel: unraid-api[55478]: segfault at 60 ip 0000148e26601059 sp 0000148e1fbfce10 error 4 in libvirt.so.0.6005.0[148e2658e000+1f6000] Actually i use Unraid version 6.9.2. Has anyone a idea what this error mean? Than You!
-
Hi, after a looooong time without errors today i found this error (only one message) in the syslog: Jul 10 07:56:18 Avalon kernel: unraid-api[45682]: segfault at 371fed7016 ip 000014b5cc11a73c sp 000014b5b60d2e58 error 4 in libgobject-2.0.so.0.6600.2[14b5cc0ef000+33000] Can anyone say what is it and if is it critical? I use Unraid Version 6.9.2 2021-04-07 Thank You!
-
No, 6.9.2 Is this the reason?
-
Hi, i cannot find the LXC Plugin in the CA App. 😞
-
Kannst Du die Ubuntu VM nicht nach Unraid migrieren?
-
Servus, habt Ihr es geschafft Unraid-Docker Container mit dem Checkmk-Raw-Docker bzw dem checkmk-Agent zu überwachen wie hier beschrieben? Ich habe zwar unter /usr/lib/check_mk_agent/plugins das Script mk_docker.py installiert, aber ich kann das nicht mit chmod +x ausführbar machen und in checkmk wird mir für den Unraid-Host keine Docker Überwachung angezeigt. Python2 und Python3 (3.9) sind über die NerdTools installiert. Kann mir da jemand den nötigen Anstoss geben damit das funktioniert? Danke & Gruß
-
Hi mgutt, thank you for your answer. This workes for me! source_paths=( "/mnt/zpool/Docker" "/mnt/zpool/VMs" "/mnt/zpool/nextcloud_data" ) backup_path="/mnt/user/Backup_zpool" ... rsync -av --exclude-from="/boot/config/scripts/exclude.list" --stats --delete --link-dest="${backup_path}/${last_backup}" "${source_path}" "${backup_path}/.${new_backup}" excludes.list Debian11_105/ Ubuntu21_102/ Win10_106/
-
Hi mgutt, i have changed the rsync command in the script (V0.6) to rsync -av --stats --exclude-from="/boot/config/scripts/exclude.list" --delete --link-dest="${backup_path}/${last_backup}" "${source_path}" "${backup_path}/.${new_backup}" The file exclude.list contains this: /mnt/zpool/VMs/Debian11_105/ /mnt/zpool/VMs/Ubuntu21_102/ /mnt/zpool/VMs/Win10_106/ /mnt/zpool/Docker/Dockerimage/ But the script don't ignore the directorys in the exclude.list Can you say why? Thanks!
-
Hi mgutt, thank you for the superb script. I have a feature request: Is it possible to have an option for excluding files or paths? Best regards Chris
-
Wow this is great and exactly what i need. Now i can use a Debian VM use as a (AirPrint)Printserver. If the Printer is off, the printjob is waiting in the cups-scheduler until i have turned on the printer and the printer auto connects to the VM 🙂 Very nice!
-
Hi, i passthrough a USB Printer to a Debian VM with this Plugin. I have checked the Box in the VM Setting to passtrhough the printer and the printer is available in the VM: root@debian11-103:~# lsusb Bus 001 Device 004: ID 03f0:132a HP, Inc HP LaserJet 200 color M251n Bus 001 Device 002: ID 0627:0001 Adomax Technology Co., Ltd QEMU USB Tablet Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub Bus 003 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub root@debian11-103:~# If i turn off the printer, the printer i not more available in the VM. If then i turn on the printer, the printer does not connect automatically to the VM. I must manually add the printer to the VM in the VM-Tab. How can i passthrough automatically to the VM after turning on the Printer? Thx Chris


