




bombz
Members
-
Joined
-
Last visited
Everything posted by bombz
-
Hello, Appreciate you looking into this. I was doing my best to skim the diagnostics. Yesterday I moved the flash to a USB 3.0 port, as I have been using the 2.0 port(s) since my inception of UnRAID over 10 years ago. As I saw in the kb's over the years that 2.0 is the preferred port, I will take a gander at the 3.0 for the sake of testing. The flash drive was replaced 2 days ago, as a heads up. Who knows, it may come down to a whole system board, CPU, RAM replacement. Hope the port resolves it, but I should prepare to start looking into new hardware. If you have any hardware suggestions let me know. Thank you.
-
unraid-diagnostics-20230425-1730.zip Here you are sir. Thank you kindly :-)

-
Hello, Been recently noticing after my last flash drive started to toss corruption errors that even when replacing the drive for a brand new flash drive the corruption reoccurs after 1 to 2 days. I am attempting to determine if this is a motherboard USB port error, or if the USB flash is taking on more writes than normal. Took approx. 1d 22h for the corruption to reoccur Rebooting the server seems to fix the issue, but I am sure it will reoccur again. I suppose I will wait to see if the I/O port swap helps the situation, or if it is software. I am open to suggestions. Thanks :-)
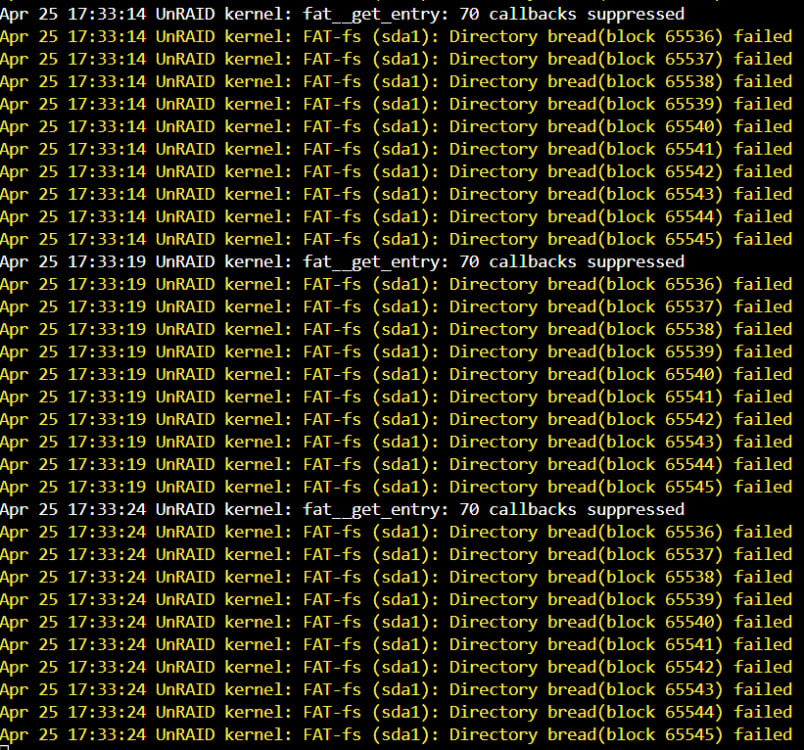
-
Well I am sad now. The new flash drive seems to be doing the same thing. I wonder what is causing the corruption or if the motherboard is failing ? Took approx. 1d 22h for the corruption to reoccur Rebooting the server seems to fix the issue, but I am sure it will reoccur again.
-
Hello. I was wiped out from my Friday work day, and cannot recall my order of operations. I was referencing my previous USB flash drive file structure which did have 'EFI' If I am correct I did run makebootable.bat when the folder was set as 'EFI' without success. I want to say for some reason this USB 3.0 drive paired with this older Asus motherboard may be the concern with the BIOS is on it (I am not 100%). The reason I say this is because I took that same USB 3.0 flash and tossed it into the Dell laptop for kick to see if the flash would boot, which had success (there was one time it didn't). Then again my Windows Server 3.0 USB (UFEI) created with Rufus booted with no issues... blah who knows :-) Regardless, going back to the good old trusted manual method seems to be tried and true. Flash drive replacement happens so rarely, clearly forgot some of the little nuances that come with it. I do apologize that I was a little frantic last night after a long day. (I laugh at myself because the simplest of things can be so hard somedays) As always; the community comes though time and time again, and really makes this product even better overall! The developers, support personnel, and end-users all coming together. Really appreciate the back and forth here. Sorry to be posting on a [SOLVED] thread, but I suppose we can add this to the 'solved' discussion :-)
-
Hello, Yes I did read that, and followed that guide. However it made no difference. When the USB was created with UFEI enabled or renaming the folder itself, The device would not boot. Attempting the manual method Format 'UNRAID' Copy .zip to flash (which had the EFI-) Run the makebootable.bat Ran with success. I then shut down the server copied my backup from the old flash Powered on & booted server. Performed the GUID swap for the new key Tested all services (docker, etc.) Ran Parity Sync When I did attempt to rename the EFI- to EFI (for kicks) there was no success with the boot process (no bootable device found) As it stands the system & flash is operational again. Was able to marry the GUID to the key and things seem good to go. In mid swing on a parity sync for sanity at this time. All services seem to be up and running 100% I do appreciate the assist here, not sure why I had forgotten this process (in a sense). I believe I will stick with the manual method moving forward over the USB Creator. Thank you again!
-
Seems to be back up and running... I won't know 100% until unraid support gets back to me with the new key for the new GUID. I can report back once everything is 100% Seems to not be booting via UEFI anymore, and back to a legacy boot on this USB 3.0 disk UFI- folder = does not show a UFEI boot device in the boot POST list anymore I suppose moving forward, the manual method is the method that is to be used when moving from an old flash drive to a new flash drive. Thank you for your help, I was looking at some of this the wrong way.
-
I will give it a go. I noticed many .notify files within my backup when copying the data. Can these be deleted ?
-
I suppose the next question is maybe revolving around my backup USB 2.0 drive. What files and folders should be copied back to the new flash drive, and what should be left untouched when creating a new USB boot device?
-
The system booted another Kingston USB 3.0 G4 @ 32GB with Windows OS without issue seems the concern revolves around when I create a Unraid USB with the USB creator , it wont boot on the NAS (Asus board) Boots fine on a Dell laptop without issue. I am very puzzled by this right now.
-
Hello, It is a Kingston DataTraveler G4 32GB USB 3.0 drive I got this USB drive to boot on my laptop successfully for a test. Took it to the NAS (Asus Mobo) and it wouldn't boot. Attempted to try all the USB ports in the I/O and always get the error that device is not bootable My previous Kingston USB 2.0 disk, that is corrupted , I put it in my Windows system, it repaired the disk. I then put this same USB 2.0 flash back into the NAS and it booted without issue. I am starting to wonder if this Asus Mobo is old (thought it has USB 3.0 ports on it) that it won't boot the Unraid Kingston USB 3.0 flash for whatever reason. It's hard to find USB 2.0 drives online currently. I did find a few sandisk, but based on the Unraid wiki PSA there may be counterfeit ones out there too. Thoughts?
-
Reaching out for a strange one, I have done this USB replacement many times in the past with USB 2.0 disk My current Kingston USB 2.0 drive is showing corruption, so I only have Kingston USB 3.0 USB on hand. I used the USB Flash creator, created the flash disk Copied over my backup after the flash was created ran make_bootable.bat From there tried to boot to this USB flash with my NAS and another laptop to attempt to test, and there has been no luck, says non-bootable medium. I attempted with the 'Allow UEFI Boot' checked and attempted many enable and disable legacy boot etc. My last USB 2.0 drive has the EFI folder on it, so I always used that. Im scratching my head at this one. Any suggestions? Thanks.
-
Hello again, Ran another pass on both my servers and this monthly pass showed no errors reposted. Strange why they produced in the first place. As always I appreciate the feedback, support and assistance with this inquiry. Thank you again!
-
Hey, OK sweet, thanks for this info! Looking forward to future updates. Thanks again for all the hard work on this docker its been a game changer over the years!
-
Appreciate the back and forth today. I can only make out that I was on a version older than 1.4.0-3, and when pushing to 1.5.0 these mariadb errors occurred. If anyone runs into a concern as I did today, this would be my recommendation (although the dev-op may have better recommendations) Upgrade: ApacheGuacamole > Edit > Repository: jasonbean/guacamole:1.4.0-3 Select > Apply Test the docker instance. Upgrade Continued: Once confirmed the above is operational proceed with the following ApacheGuacamole > Edit > Repository: jasonbean/guacamole Select > Apply Test the docker instance. The log should show the following if successful uacd[34]: INFO: Guacamole proxy daemon (guacd) version 1.5.0 started Should be up-to-date This docker hands down has helped me so much, and I am happy to see it has development currently. I will do my best to check the thread BEFORE pushing future updates. Thank you again :-)
-
Hello, This is wonderful information and I appreciate you taking the time to explain this. Thank you for the location of the file @ appdata/ApacheGuacamole/guacamole/guacamole.properties I have confirmed that my settings are the same as yours, I never changed any of these settings since the deployment of ApacheGuac years ago. So based on what was discovered today, moving forward, I should be good to go with this current state? ### http://guacamole.apache.org/doc/gug/jdbc-auth.html#jdbc-auth-mysql ### MySQL properties mysql-hostname: 127.0.0.1 mysql-port: 3306 mysql-database: guacamole mysql-username: guacamole mysql-password: <password> Thank you.
-
I think I get it now. I must have been on an older version of ApacheGuacamole I pushed the update today using jasonbean/guacamole Which I then had the errors described above I then was able to downgrade to jasonbean/guacamole:1.4.0-3 Which was then operational I then edited the repository to jasonbean/guacamole Which now shows the deamon started on version 1.5.0 ---------------------- User UID: 99 User GID: 100 ---------------------- Using existing properties file. Upgrading MySQL extension. Upgrading TOTP extension. Updating user permissions. Database exists. Database upgrade not needed. 2023-04-01 17:24:59,749 INFO Included extra file "/etc/supervisor/conf.d/supervisord.conf" during parsing 2023-04-01 17:24:59,750 INFO Set uid to user 0 succeeded 2023-04-01 17:24:59,755 INFO supervisord started with pid 33 2023-04-01 17:25:00,761 INFO spawned: 'guacd' with pid 34 2023-04-01 17:25:00,764 INFO spawned: 'mariadb' with pid 35 2023-04-01 17:25:00,768 INFO spawned: 'tomcat' with pid 36 guacd[34]: INFO: Guacamole proxy daemon (guacd) version 1.5.0 started I think I am good to go now. Apologies for misunderstanding this. From what I can tell I was on a version previous to 1.4.0-3 and upgraded to 1.5.0. Make sense? Thank you kindly.
-
Thank you for the fast response, and do apologize if I missed something. Now that I am back on 1.4.0-3 what is the step process to upgrade the db and container successfully? Do I have to change: OPT_MYSQL: from Y to N ?
-
Hello, I appreciate this post. I was able to successfully downgrade to the following repository successfully Repository: jasonbean/guacamole:1.4.0-3 usermod: no changes chown: cannot access 'var/log/mysql': No such file or directory ---------------------- User UID: 99 User GID: 100 ---------------------- Using existing properties file. Upgrading MySQL extension. Upgrading TOTP extension. Updating user permissions. Database exists. Database upgrade not needed. 2023-04-01 16:45:46,494 INFO Included extra file "/etc/supervisor/conf.d/supervisord.conf" during parsing 2023-04-01 16:45:46,494 INFO Set uid to user 0 succeeded 2023-04-01 16:45:46,498 INFO supervisord started with pid 37 2023-04-01 16:45:47,502 INFO spawned: 'guacd' with pid 40 2023-04-01 16:45:47,505 INFO spawned: 'mariadb' with pid 41 2023-04-01 16:45:47,508 INFO spawned: 'tomcat' with pid 42 guacd[40]: INFO: Guacamole proxy daemon (guacd) version 1.4.0 started guacd[40]: INFO: Listening on host 0.0.0.0, port 4822 2023-04-01 16:45:48,653 INFO success: guacd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:45:48,654 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:45:48,654 INFO success: tomcat entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) guacd[40]: INFO: Creating new client for protocol "rdp" I did note the red banner in the thread... is there a detailed guide on how to perform this db upgrade for this container? Thank you.
-
Hello, I don't use mariadb and upgraded the docker and have this in the log User UID: 99 User GID: 100 ---------------------- Using existing properties file. Using existing MySQL extension. Using existing TOTP extension. No permissions changes needed. Database exists. Database upgrade not needed. 2023-04-01 16:38:22,770 INFO Included extra file "/etc/supervisor/conf.d/supervisord.conf" during parsing 2023-04-01 16:38:22,770 INFO Set uid to user 0 succeeded 2023-04-01 16:38:22,773 INFO supervisord started with pid 23 2023-04-01 16:38:23,779 INFO spawned: 'guacd' with pid 24 2023-04-01 16:38:23,782 INFO spawned: 'mariadb' with pid 25 2023-04-01 16:38:23,786 INFO spawned: 'tomcat' with pid 26 guacd[24]: INFO: Guacamole proxy daemon (guacd) version 1.5.0 started guacd[24]: INFO: Listening on host 0.0.0.0, port 4822 2023-04-01 16:38:24,823 INFO success: guacd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:24,824 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:24,824 INFO success: tomcat entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:24,824 INFO exited: mariadb (exit status 1; not expected) 2023-04-01 16:38:25,829 INFO spawned: 'mariadb' with pid 62 2023-04-01 16:38:26,870 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:26,871 INFO exited: mariadb (exit status 1; not expected) 2023-04-01 16:38:27,875 INFO spawned: 'mariadb' with pid 68 2023-04-01 16:38:28,913 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:28,914 INFO exited: mariadb (exit status 1; not expected) 2023-04-01 16:38:29,919 INFO spawned: 'mariadb' with pid 73 2023-04-01 16:38:30,958 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:30,959 INFO exited: mariadb (exit status 1; not expected) 2023-04-01 16:38:31,964 INFO spawned: 'mariadb' with pid 79 2023-04-01 16:38:32,999 INFO success: mariadb entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2023-04-01 16:38:33,000 INFO exited: mariadb (exit status 1; not expected) Any idea how to fix? Any idea how to downgrade to a previous repository ? GUI error when attempting to access apache guac
-
Hello, Appreciate the prompt follow-up. I will kick off another parity sync, or possibly wait for the next monthly scheduled sync to see how things pan out. I will report back regardless of the findings. Thank you kindly!
-
Hello, Came across parity sync errors as well There are no disk errors at the moment. I am having concerns pinpointing what may be the cause of this. I did run into a concern last weekend when updating a plugin the GUI download halted. I performed a clean shutdown of the server rebooted the server the USB /sda was erroring or corrupted (server would not boot) I pulled the USB and restored my backup on a WinOS system booted the server and ran a parity check the first run saw 2 errors yesterdays scheduled run sees 592 errors Wondering if I should be concerned with this, or where the errors are. Are they possible sync errors? Looking forward to some clarification. Thank you kindly, Cheers diagnostics-20230303-0705.zip

-
Circling back on the V3 thread (as i am still using V2) due to the initial concerns with V3's deployment. Based on some of the posts I am assuming V3 is not fully functional and encountering random backup bugs? I am in no rush to move to V3 as V2 is working flawlessly at this time. If anyone would like to share their experience with the migration from V2 to V3 (any GOTCHAS) to look out for, I am all ears. Thank you kindly.
-
I was pondering that. was going to wait until everything got buttoned up, regarding some of the feedback on I am still running V2 for now. I will push up to the latest soon. I appreciate that recommendation. Thank you.
-
Hello, Reporting to this thread regarding this concern as well UnRAID 6.11.1 Today I was going through my plugin check and (2X) plugins were not updating, they would sit in a 'pending' state Unassigned devices Unassigned devices Preclear I did check the logs before the reboot regarding this so my next course of action was to reboot (I would post the logs of the above plugin errors, however logs are not written to the flash and only to the RAM disk so I can't) going to look into how to possibly resolve that concern if there is a way to capture logs. Upon reboot I did receive a checksum error bzroot-gui - checksum error .... PRESS ANY KEY TO REBOOT I turned off the system and inserted my USB flash into my local desktop Downloaded > unRAIDServer-6.11.1-x86_64.zip Copied > bzroot-gui & bzroot-gui.sha256 (from the above zip to the flash drive) Safely removed the flash disk Inserted the flash disk back into my UnRAID server Booted with success Plugins updated with success Posting feedback in case anyone else has these concerns. Thank you,





