bombz
Members
-
Joined
-
Last visited
Everything posted by bombz
-
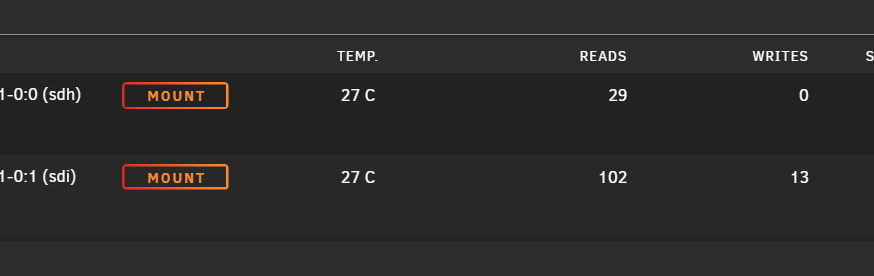
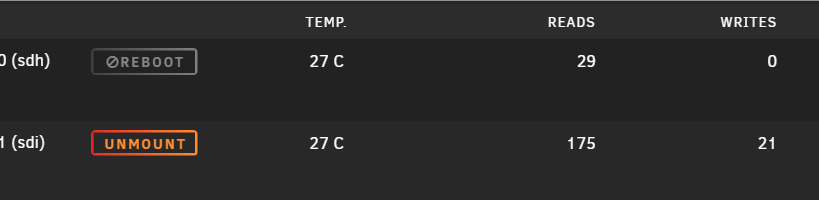
Hello, Thank you for the quick reply. I am not sure what you mean? Here are the 2 disk, if I try to mount (sdh) I receive the following prompt as stated above But if I mount (sdi) the mount is successful and (sdh) changes to 'reboot' would you mind clarifying? Thank you.
-
Hello, Attempting to mount a device with UD and unsure as if why it won't mount. It is a disk I pulled from the array formatted as XFS and the plan is to preclear it. I am running into the following error Jan 20 14:13:27 unassigned.devices: Error: Device '/dev/sdh1' mount point 'WDC_WD40_EFRX' - name is reserved, used in the array or a pool, or by an unassigned device. Jan 20 14:13:27 unassigned.devices: Disk with serial 'WDC_WD40_EFRX_ATMM221U3000000001-0:0', mountpoint 'WDC_WD40_EFRX' cannot be mounted. I was able to mount other disk, however this one is not allowing to mount. Any ideas?
-
10-4 seems better now, had to pick an off-peek time to reboot, was considering performing a reboot sooner, and thought to add some info for the community, just incase :-) seems better now... 0 /var/log/pwfail 8.0K /var/log/unraid-api 0 /var/log/preclear 0 /var/log/swtpm/libvirt/qemu 0 /var/log/swtpm/libvirt 0 /var/log/swtpm 0 /var/log/samba/cores/rpcd_winreg 0 /var/log/samba/cores/rpcd_classic 0 /var/log/samba/cores/rpcd_lsad 0 /var/log/samba/cores/samba-dcerpcd 0 /var/log/samba/cores/winbindd 0 /var/log/samba/cores/nmbd 0 /var/log/samba/cores/smbd 0 /var/log/samba/cores 36K /var/log/samba 0 /var/log/plugins 0 /var/log/pkgtools/removed_uninstall_scripts 4.0K /var/log/pkgtools/removed_scripts 4.0K /var/log/pkgtools/removed_packages 8.0K /var/log/pkgtools 4.0K /var/log/nginx 0 /var/log/nfsd 0 /var/log/libvirt/qemu 0 /var/log/libvirt/ch 0 /var/log/libvirt 428K /var/log Thank you again for your assistance!
-
Hello, Here is the output of the command: 0 /var/log/pwfail 127M /var/log/unraid-api 0 /var/log/preclear 0 /var/log/swtpm/libvirt/qemu 0 /var/log/swtpm/libvirt 0 /var/log/swtpm 0 /var/log/samba/cores/rpcd_winreg 0 /var/log/samba/cores/rpcd_classic 0 /var/log/samba/cores/rpcd_lsad 0 /var/log/samba/cores/samba-dcerpcd 0 /var/log/samba/cores/winbindd 0 /var/log/samba/cores/nmbd 0 /var/log/samba/cores/smbd 0 /var/log/samba/cores 1.1M /var/log/samba 0 /var/log/plugins 0 /var/log/pkgtools/removed_uninstall_scripts 4.0K /var/log/pkgtools/removed_scripts 12K /var/log/pkgtools/removed_packages 16K /var/log/pkgtools 8.0K /var/log/nginx 0 /var/log/nfsd 0 /var/log/libvirt/qemu 0 /var/log/libvirt/ch 0 /var/log/libvirt 128M /var/log Appreciate your feedback, hope it helps with a resolution. Thank you.
-
Hello, I previously installed all plugins (today) before I saw this concern happen.... 'connect' was one of them. Saw in the 'connect' release notes before pushing the plugin update, that there were changes to 'connect' due to community feedback. Once updated, I noted the system log went to 100%
-
Hello, I seem to also be having a concern with the GUI system log showing 100% I have been attempting to figure out where the concern may be. I have posted diagnostics to assist. Thank you. unraid-diagnostics-20240113-1058.zip

-
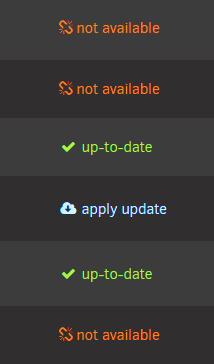
Saw this concern random docker containers are showing 'not available' when attempting to update today....after updating to the latest CA Currently running v6.12.4 Is there a workaround for this concern, or perhaps has been patched in the latest OS 6.12.6?
-
Thanks for the info here. I was looking to update my current HTPC which streams from the PLEX server (direct play). My challenge was discovering all the new hardware out today that would allow the HTPC (client) to play 4K HVEC / AV1 without any concerns. I only need to upgrade the motherboard and CPU I stumbled across this and would like to get your thoughts? Intel Core i3-13100 Desktop Processor 4 cores (4 P-cores + 0 E-cores) 12MB Cache, up to 4.5 GHz MSI PRO-B760M-P-DDR4 (Supports 12th/13th Gen Intel Processors, LGA 1700, DDR4, PCIe 4.0, M.2, 2.5Gbps LAN, USB 3.2 Gen2, mATX) I was curious if the Intel UHD Graphics 730 would handle 4k playback from plex, of if I would require from more horsepower from say a: GeForce GT 710 2GB DDR3 PCI-E2.0 DL-DVI VGA HDMI Passive Cooled Single Slot Low Profile Graphics Card (ZT-71302-20L Looking forward to hear your feedback regarding this. Thank you.
-
Hello, You rock man, thanks for all the feedback, really appreciate your time clarifying these concerns!
-
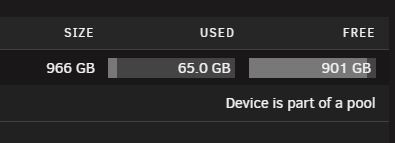
Another question while I have you, since I just deployed the ZFS pool on NVMe -- I was reviwing the 'system' section in 'dashboard' The percentage on the ZFS pool, why does it seem high usage, is this due to it being accessed (it only has one docker on the pool). I looked at the space used vs. space free and I don't think it is related to that? Any feedback would be great so I am understanding what the 'system' percentage is displaying. Thanks.

-
Thank you my friend. I reviewed all shares and disabled NFS on the (1X) share that had 'export' set to 'yes' (now changed to 'no'). Hope that resolves the random concern regarding disk shares disappearing.... strange one for sure. I be sure to follow-up if the concern reoccurs.
-
Ok, appreciate the prompt follow-up. For sanity, to disable NFS Shares select: Shares > Share Name > NFS Security Settings > Export > No Which should disable it?
-
Hello, Appreciate this info. As it stands for this share > NFS Security Settings > No (are set). I also saw you posted this: Settings > Global Shares Settings -> Tunable (support Hard Links): no I can set this setting once I can stop the array. I don't believe I require NFS sharing, I thought maybe it was required for dockers. Would I be required to disable NFS globally, or just on this specific share? Under Global share settings, I don't see a spot at this time to disable SMB or NFS. Currently I am seeing 'Enable Disk Shares' & 'Enable User Shares'
-
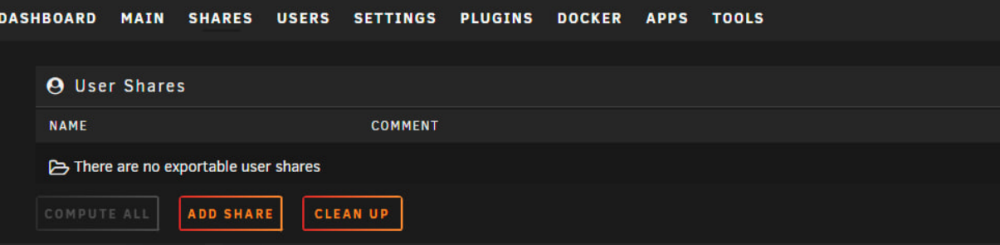
Hello, I shut down the plex docker today to restart and the following error came back when attempting to restart, and all my unraid shares disappeared. I pulled diags Not sure why this happens unraid-diagnostics-20231210-1529.zip
-
Hello, I attempted this without success. I have content that is in EAC5.1 that does work as it should, then other content that is EAC5.1 that previously worked -- which now does not. I attempted to delete the codecs out of the local plex HTPC folder and re-load it, and it does not work on these 4k files... im puzzled to why it stopped playing EAC on only the 4k EAC files? Any suggestions? EDIT: Sorted it out via some testing, it is due to the local network
-
Hello, Appreciate the follow-up. To answer your question, yes changing the network to host (default state) does work and is operational. I was pondering adding the plex docker container through a reverse proxy which is on my custom network and was pondering why the IPs were not applying on a custom network. Based on your feedback, I may have to continue my research to drill down on how to accomplish this. Thank you kindly :-)
-
Resolved over an embarrassing concern... typo in the variable -- unreal @ me !
-
Same with me, never has worked did you fix it ?
-
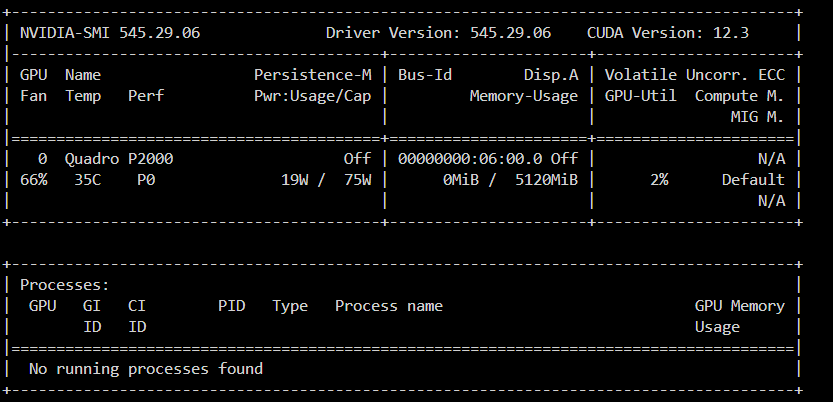
here is SMI Here is the docker run docker run -d --name='Plex-Media-Server' --net='eth1' --ip='192.168.1.2' -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="UnRAID" -e HOST_CONTAINERNAME="Plex-Media-Server" -e 'PLEX_CLAIM'='claim-TOKEN HERE -e 'PLEX_UID'='99' -e 'PLEX_GID'='100' -e 'VERSION'='latest' -e 'NVIDIA_DRIVER_CAPABILITIES'='all' -e 'NVIDIA_VISABLE_DEVICES'='GPU-867b6976-8663-b63c-234e-59c42267ad88' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:32400]/web' -l net.unraid.docker.icon='https://raw.githubusercontent.com/plexinc/pms-docker/master/img/plex-server.png' -v '/tmp':'/transcode':'rw' -v '/mnt/':'/data':'rw' -v '/mnt/user/CACHE_PLEX/appdata/Plex-Media-Server/':'/config':'rw' --runtime=nvidia 'plexinc/pms-docker' 8bba84b89978daba07238055496e246f35aa4eb244db997964e52789f7126453 The command finished successfully! Maybe a full server reboot would kick it into gear?
-
Using officiial plexinc/pms-docker
-
Hello, Reaching out as I am having concerns with Plex using the GPU for hw transcode playback. I have Jellyfin also installed and transcoding works with the GPU, is there something I am missing ? Extra Parameters: --runtime=nvidia NVIDIA DC: Container Variable: NVIDIA_DRIVER_CAPABILITIES all NVIDIA VD: Container Variable: NVIDIA_VISABLE_DEVICES GPU-ID HERE Not sure why, this seems to work with all other dockers expect for plex Any feedback would be apprecaited.
-
so i had to drop the DIR back to /mnt for plex to see the share ? I don't get why I can't point to the actual share I want plex to use, and have to go trough 2 subfolders for the docker to see it? Previously host path was /mnt/user/media Now set to /mnt/ Which allows plex docker to see it, so strange I will see what other concern I run into, took hours to figure this one out :-(
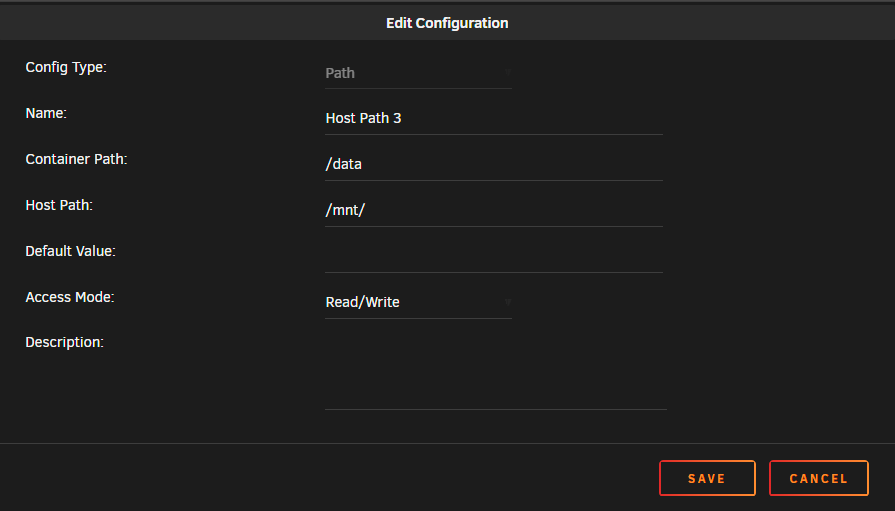
-
so i had to drop the DIR back to /mnt for plex to see the share ? I don't get why I can't point to the actual share I want plex to use, and have to go trough 2 subfolders for the docker to see it? Previously host path was /mnt/user/media Now set to /mnt/ Which allows plex docker to see it, so strange I will see what other concern I run into, took hours to figure this one out :-(
-
Care to explain this ?
-
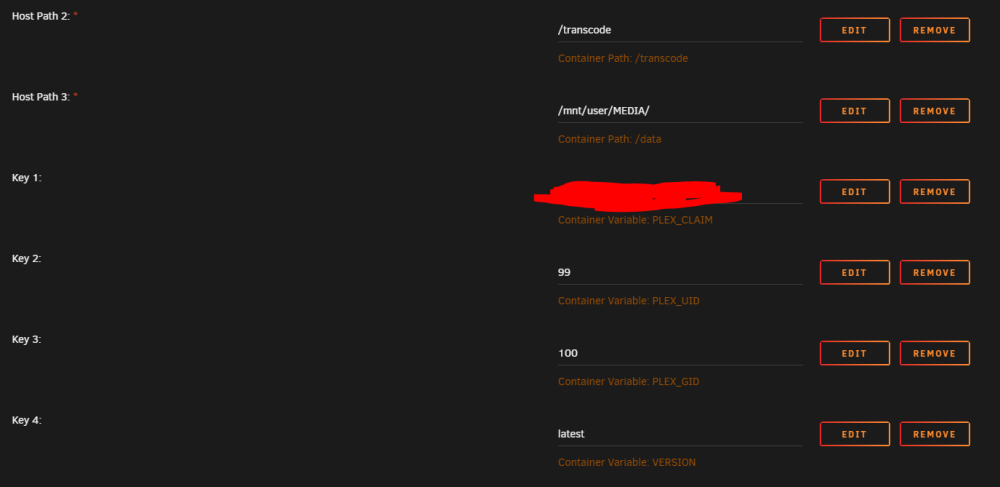
I am also having this same issue, I cannot access my shared within the plex docker. the plex docker app does not see the media folder when set /mnt/user/MEDIA/ When I load the docker and try to add a library, the dir is / which shows subfolders any ideas why plex is not seeing /mnt/user/MEDIA/ ? docker run -d --name='Plex-Media-Server' --net='eth1' -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="UnRAID" -e HOST_CONTAINERNAME="Plex-Media-Server" -e 'PLEX_UID'='99' -e 'PLEX_GID'='100' -e 'VERSION'='latest' -e 'NVIDIA_DRIVER_CAPABILITIES'='all' -e 'NVIDIA_VISABLE_DEVICES'='GPU-867b6976-8663-b63c-234e-59c42267ad88' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:32400]/web' -l net.unraid.docker.icon='https://raw.githubusercontent.com/plexinc/pms-docker/master/img/plex-server.png' -v '/transcode':'/transcode':'rw' -v '/mnt/user/MEDIA/':'/data':'rw' -v '/mnt/user/CACHE_PLEX/appdata/Plex-Media-Server':'/config':'rw' --runtime=nvidia 'plexinc/pms-docker' c88d1b1e5697921566baf5f1f6d130a68b08e1d9a29dd5bae8ff4e965d901ccd The command finished successfully! Any ideas?