





Zonediver
Members
-
Joined
-
Last visited
Everything posted by Zonediver
-
UD issues an idle command to disk drives that will put it to sleep if the drive responds to the idle command. It should go to sleep unless it is busy. Why does a disk have to be spun down for the server to go to sleep? Cause i defined it so under the Sleep-Plugin - Server goes to sleep, if all disks are spun down - indication for no longer need the server. The main reason is to safe energy. The Unassigned Device is only a TEMP-Drive for the Plex-Transcoder to torture the SSD less. My unRaid is only for Plex-Streaming. But i did a reboot and all is fine now - thanks for your help dlandon
-
Just a short question: Is it normal that the Unassigned Device - in my case a HDD - never spun down??? It prevents my server to go to sleep.
-
...thats the reason, why nobody reads the documentation - most of them is outdated - wasting time About this plugin: I see the main-problem in the reason, that the userinterface is not behave like the rest of unraid like Dynamix. So first you must rethink to underrstand the behave and second, you must lern, how it works (or RTFM). But who likes to Read The Fucking Manual??? An UI should be "self-explaining" and intuitive - but yes, functionality is extensive and very good. Regarding the red-x: the plugin should have a button or something for deleting the Disk - like in Dynamix. This could help "newcomers" to understand easier, how it works. As i mentioned, the behavior is different from other UI-function at Dynamix/unraid - so this may be a problem. I like to say thanks a lot to dlandon for his great work, great support and a great plugin, which gave us the ability that unraid dosnt In my case, moving the Plex-Transcoder TEMP-Files away from the SSD and moving the Plex-Database Backup off of the array - GREAT WORK!!!
-
If the board in your sig is what you are using, I don't believe you have ipmi. You can go to the command line and type ps aux | grep ipmi pe aux | grep php Then killall the processes. How can i kill what? Run those commands from the command line and let me know what the result is. ps aux | grep php: 16938 0.0 0.0 5100 1720 pts/0 S+ 03:36 0:00 grep php ps aux | grep ipmi: 17208 0.0 0.0 5100 1676 pts/0 S+ 03:36 0:00 grep ipmi EDIT: WebGUI came back after 10mins and i was able to deinstall this plugin - pfffffffffffff.... not funny mate
-
If the board in your sig is what you are using, I don't believe you have ipmi. You can go to the command line and type ps aux | grep ipmi pe aux | grep php Then killall the processes. How can i kill what?
-
I installed this plugin and now, my WegGUI is unresponsible - what now? How can i get the GUI back? It seems this plugin crashes the whole GUI - mad WOW - did a shutdown -r now over ssh - now the Server is up but i cant do anything. How can i remove this plugin now??? And of corse the server is doing a parity check now but i cant stop it...
-
Ahhhhh - there is a "switch" okidoki - thanks for this hint dlandon Yep - i see - little bit tricky Now i see how this is working - thanks for your help again
-
In order to format a disk, you have to delete all partitions on the disk using the red-x. Then the format button will appear. I know this "now" - but it was not logical... By the way: I activated the SMB-Share - but i cant see it in Windows - where can i find it? There is no way to give the share a name? Or: How can i create now a share on this device, which is seen in Windows as well?
-
I know this - but the format itself must be done under "Main" "unassigned Devices" Tab and there is no Format - just a red X after unmount a device.
-
Just a question about this plugin: How do i format a disk??? There is nothing at the UI - must i do this by hand? EDIT: Found it I was looking for a Format-Button and didnt see the "red-x" - lol - sorry for that silly question EDIT 2: ...and now, explane me THIS I only activated SMB-Security... or better, i tried it
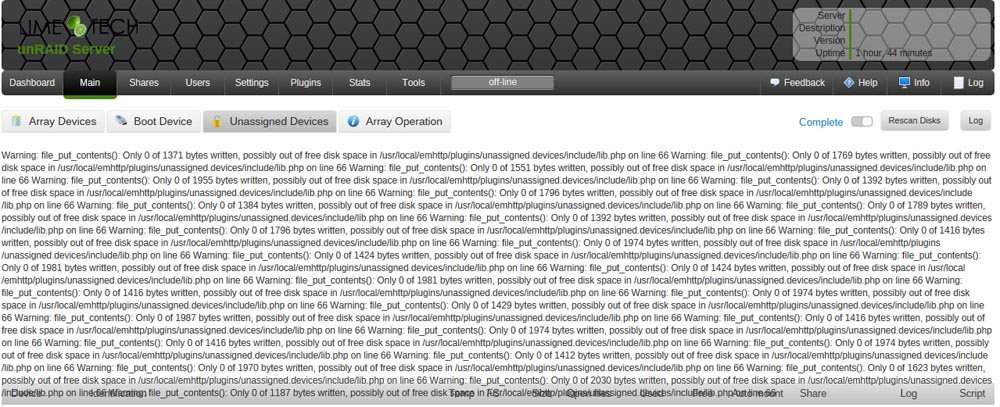
-
Thanks for the links, CHBMB - will test this tomorrow Morning
-
Are you using 6.2beta21, right? My signature says 6.1.9 I never use betas - my sys is a "productive" one And were can i find the "right" packages for 6.1.9?
-
Just an old thread - i know - but one question: How is this working without Docker??? I dont use Docker for Plex, so how can i change the Transcoder-directory to RAM?
-
After installing all this *.txz files, i saw that i was no longer able to reach my SMB-Shares so i removed all this stuff and did a reboot. Now all shares are working again - very disappointingThanks for this info Regarding the copies: I did this by hand - your plugin did not copy to all disks. It always stopps after a copy to only one disk was finished.And whats up with the changes in /etc/profile.d/lang.sh How will they survive? I cant believe, that a system is only coming with an US-support for keyboard/language... strange This "tinker-solution" is crapWhat and where? Go-File? Sorry - i am a Noob at this things...First, you need to install these packages: http://mirrors.slackware.com/slackware/slackware64-current/slackware64/l/glibc-i18n-2.23-x86_64-1.txz http://mirrors.slackware.com/slackware/slackware64-14.1/slackware64/a/kbd-1.15.3-x86_64-2.txz Then, you should take a look into this: http://docs.slackware.com/slackware:localization Ok - tried this procedure and its not working. After a reboot, only US is present and changes in /etc/profile.d/lang.sh are back to default US Did also a locale -av and it gave me only "US". So... how can i make this persistent? Maybe its the installation... I put all packages to folder "extra" on my USB-stick - was this maybe wrong?Ok - done - thanksThanks for your hint gfjardim Just a question: Do i need to install glibc or can i simply change the setting in "/etc/profile.d/lang.sh" to "LANG=de_DE.utf8" ?Actually, unbalance logs are separate from the diagnostics provided by unRAID. They're located at /boot/logs/unbalance.log Sorry mate - here is the correct one unbalance.zipIt should spread the folders over various disks, if space is available. If you can send me the logs (pm if you want), I'll take a look. Hi jbrodriguez, here is the requested Log unraid-diagnostics-20160417-1804.zipI need this too! Somteimes i must directly work on the Server over a Keyboard/Monitor and not over ssh or telnet. For this reason i need to change the keyboard to "German" - only US is present. This is very frustratingHi jonathanm, i see - i tried it and yes, there is no difference for the parity between deleting the files by hand or reformat the drive directly Thanks for this correction - safes a lot of time


