




hawihoney
Members
-
Joined
-
Last visited
Everything posted by hawihoney
-
Du hast im Prinzip das Hauptmerkmals von Unraid, das Array, noch nicht verstanden. Ich empfehle den Overview Artikel im Unraid Manual: https://docs.unraid.net/unraid-os/manual/what-is-unraid/#parity-protected-array 1.) Wie der Name schon sagt, ist Unraid kein typisches RAID sondern ein Ansammlung (Array) von Platten. Man nennt das auch JBOD (Just a bunch of disks). Das Besondere an Unraids Array ist aber, dass es diese Ansammlung von Platten trotzdem mit bis zu zwei Parity-Platten schützen kann. 2.) Ein weiteres Kernelement des Unraid Arrays ist, dass nicht alle Platten beim Schreiben oder Lesen aktiv sein müssen. Auch das unterscheidet das Unraid Array von typischen RAID Systemen. Auf jeder Platte befindet sich nämlich ein eigenes Dateisystem und somit werden Ordner und Dateien auf Platten verteilt. 3.) Die dritte Kernkomponente ist, dass bei einem gleichzeitigen Defekt von mehr Platten als durch die Parity abgedeckt sind, nicht das ganze Array verloren ist. Das ist nämlich bei allen typischen RAID Systemen der Fall. Nicht so beim Unraid Array. Beispiel typisches RAID-5: 12x Platten können den Ausfall einer Platte verkraften. Wenn nun aber zwei Platten gleichzeitig kaputt gehen, dann ist alles (ALLES!!!) verloren und es hilft nur ein Restore vom Backup. Beispiel Unraid Array: 12x Platten werden durch eine Parity Platte (man kann auch 2x Parity) abgedeckt. Gehen nun sagen wir mal 5 Platten kaputt. Dann kannst Du immer noch den Inhalt der restlichen 5x Platten lesen. Das ist IMHO das Wichtigste an Unraid. Docker Container, VMs, RAIDs/Pools (ZFS, BTRFS), NAS, können alle - so wie Unraid. Aber Du findest wahrscheinlich kein System das so energiesparend und trotzdem so groß wachsen kann wie das Unraid Array.
-
Erster Treffer bei Tante Google: Danach ist man doch auch nicht schlauer. Wie geschrieben: 40 GB am Tag für eine SSD sind nun wirklich nicht die Rede wert. Du hast schon gesehen, dass meine SSD 700 TB hinter sich hat und nicht 700 GB. Jeder Hersteller liefert zudem TBW Werte. Aber auch damit kannst Du nach einem Tag baden gehen.
-
Ganz ehrlich? Das ist doch Kleinkram. Hier läuft bis zum 20-fachen pro Tag über eine am Rechner baumelnde SSD (Samsung Portable SSD T7). Auf der wurden bisher über 700 TB geschrieben und wieder gelesen und wieder gelöscht (hab heute in irgendeinem anderen Thread einen Screenshot von der gepostet). Einfach mal loslegen und eine Entscheidung treffen.
-
Ich sehe 63.000 Bewertungen - zu 97 % positiv. Ich sehe allein 3.000 verkaufte Modelle diesen Typs. Bei dem laufen Millionen durch. Natürlich kann der morgen verschwinden - so wie Kaufhof und Benzko auch ... Wenn ich mich danach richten würde, dann käme ja nur noch Amazon in Frage. Ach stimmt ja, kaufe ja nur bei Amazon und gelegentlich bei eBay
-
Weiß ich nicht. Die sind erst seit ein paar Monaten bei mir drin. Haben aber alle schon eine volle Befüllung überlebt Bis auf die Handvoll neuen Seagates sind bei mir ausschließlich Toshibas in Betrieb (HDWR160, MG07ACA12TE, MG09ACA18TE). Es kommt natürlich auf die Erwartungshaltung an. In meinen Arrays tut sich nicht sehr viel. In der Regel wird hier eine Platte im Array genau einmal beschrieben und dann nur noch gelesen. Da kaufe ich immer das Billigste. Die eigentliche Arbeit läuft auf den Pools die mit SSD und NVMe Devices bestückt sind. Z.B. ein Single-Disk XFS SSD Pool: Niemand kann Dir eine Garantie geben. Hochgelobte Platten können bei Dir am nächsten Tag ausfallen. Du musst selbst entscheiden auf welches Pferd Du setzt. Kannst Dich aber bei Backblaze erkundigen (Stichwort: Hard Drive Reliability Updates).

-
Mir ging es um Dein Wort "gleichzeitig". Da ist nix gleichzeitig da jeder Schritt auf den vorherigen aufbaut. Und das ist im Kern auf keinen Fall das gleiche ...
-
550 / 8 = ? Wie bereits häufiger geschrieben, die teilweise esoterischen Diskussionen zur Performance kann ich nicht nachvollziehen. Ist hier immer gleich.
-
Steht das etwa so in der deutschen Hilfe? Wäre falsch. Das passiert wirklich:
-
Das ist "auto".
-
Hmm, would be a bummer. So as suggested - let's wait for the next OS update.
-
Egal was ich einbaue - es läuft bei mir auf 55-75 MB/s hinaus. Solange es keine SMR oder 5400er Platten sind. Durch die vier Operationen beim Schreiben ins Array ist nämlich die lahme Umdrehungsgeschwindigkeit ein Hemmschuh.
-
Da habe ich ehrlich gesagt nicht drauf geachtet. Ich will auch nicht wissen wo er die her hat, was die Hinweise bedeuten, etc. Sind sind günstig und laufen Ehrlich gesagt glaube ich auch nicht das das Platten aus der EUR 800 - EUR 1000 Klasse sind. Für 200 Ocken??? Im Array mache ich mir auch keinen Kopf. Wenn die einmal voll sind, dann wird da zu 99% nur noch gelesen. Ich kaufe immer das Billigste fürs Array. Was soll da schon passieren ... Ich habe hier noch eine neue von ihm herumliegen. Wird in den nächsten Tagen eingebaut: Und so sieht so ein Modell im Array aus:


-
Im Unraid array kannst Du mischen wie Du willst - solange die Partity Platten größer oder gleich der größten Daten-Platte sind.
-
Guck mal die für aktuell EUR 209: https://www.ebay.de/itm/185843432850 Wurden auch mir empfohlen. Sind "recertified". Die ersten vier sind bei mir drin und laufen astrein.
-
Wichtig: Der USB-Stick muss eine eindeutige GUID besitzen/liefern. Unraid verknüpft mit dieser seine Lizenz. Hier ein paar Empfehlungen:
-
Dort steht I/O error auf sda. Entweder hat der Stick eine Macke, die Buchse/das Kabel, oder der Inhalt des Sticks ist defekt. Klingt nach Hardware (Stick).
-
zu 20 % wartet die CPU das die Platten mit dem Schreiben fertig werden - die CPU schläft. Sieht nicht tragisch aus. Könnte schlimmer sein. Es könnte das parallele Schreiben von MOVER und Dir sein.
-
Ja loggisch. Wenn von zwei Seiten gleichzeitig massiv geschrieben wird. Die bleiben da. Im Gegenteil. Die sollten auch nicht woanders liegen.
-
Sollte aber nur eine Übergangslösung sein. Ist beim Schreiben - nur beim Schreiben - schneller aber dafür stromhungriger.
-
Docker Container haben per se nix damit zu tun - es sei denn sie schreiben gerade wie wild selbst auf die Platten. Das wüsstest Du aber, denn Du hättest das dann ja selbst initiiert. Wenn man etwas nutzt, dann muss man sich über kurz oder lang damit beschäftigen. Eine erste kleine Starthilfe. Wenn die Werte so niedrig sind einfach mal die Unraid Konsole aufrufen: "top<Enter>" eingeben. TOP startet. Mit "q" beendest Du TOP. Mit "exit" verlässt Du die Konsole. Diesen Wert posten:
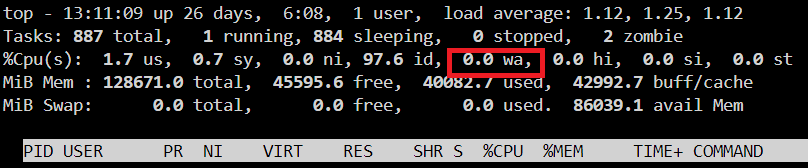
-
Guck Mal in top/htop ob das nicht IO-wait ist. Die Unraid Anzeige macht da keinen Unterschied. Der Linux Cache speichert zunächst ins RAM und wartet irgendwann auf die Platten.
-
You passthrough drives and no controllers. Why should you see controllers from the host then? Be careful. I don't know what you try to do. That way shows how to work with a controller in a VM: # # Just an example from my system - be sure you know what you do # # Find domain, bus, slot lspci -D 0000:01:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) 0000:04:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ^^^^ ^^ ^^ # Find vendor, id, bus, slot in Tools/System Devices [1000:0097] 01:00.0 [1000:0097] 04:00.0 ^^^^ ^^^^ ^^ ^^ # Isolate result in /boot/config/vfio.cfg BIND=0000:01:00.0|1000:0097 0000:04:00.0|1000:0097 ^^^^ ^^ ^^ ^^^^ ^^^^ ^^^^ ^^ ^^ ^^^^ ^^^^ # Passthrough one controller into VM (hostdev Block, needs possible adjustment of target address) <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> # ^^^^ ^^ ^^ </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </hostdev> You do have two controllers with one device each. I never tried to passthrough two controllers that form a RAID to a VM. I doubt that this will work.
-
And how did you passthrough these controllers? Show hostdev Blocks.
-
Du meinst das?
-
Du meinst das Comments Feld? Das erscheint dann aber nicht auf der Übersichtsseite. Kannst aber bestimmt nach dem Kommentar in der /boot/config/disk.log oder disk.cfg suchen. Aber wofür brauchst Du das? Unraid findet doch Platten an Hand der by-id und nicht an Hand des Einbauortes. Oder solltest Du über USB Platten reden. Dann bin ich sofort raus.









