




ChronoStriker1
Members
-
Joined
-
Last visited
Everything posted by ChronoStriker1
-
I seem to be having a problem with the share floor plugin on 6.12.0-rc.4.1, none of the shares below have a file that large in them, so Im not quite sure whats happening. The cache is a two 2TB nvme mirror zfs pool. Share 'Downloads' updated to new floor level: 659.7 GB Share 'retronas' updated to new floor level: 82.5 GB Share 'appdata' updated to new floor level: 82.5 GB Pool 'cache' updated to new floor level: 659.7 GB
-
Right now I doubt the issue is due to being on the rc but as I am using it I figure I should post this here. I had recently replaced most of the hardware on my unraid server but now it seems to be somewhat unstable. The last "crash" happened probably an hour ago, its not really a crash, I have partial access, some dockers will still be running, my ssh session seems to stay up, but some applications (like htop) will just freeze. I think I may loose /mnt/user at the time but Ive only been able to prove it once. Things are usually so bad that I cant run diagnostics or even the shutdown or reboot commands. This was way more prevalent (happening almost daily if not more often) when I first set the server up, but after changing a few hardware around (had a few bad sata cables and an HBA that seemed like it was having issues until I updated its firmware) it seemed like it went away, but I guess thats not the case. I had run memtest but the memory had passed so Im kinda out of ideas. Would appreciate anyones help.
-
The apps page wont load right now. It looks like the json file that its trying to connect to is blank on the github.
-
Can you please add nnn
-
Anyone know how to proxy the novnc with Nginx Proxy Manager? I cant figure out the correct settings for /websockify to get it to forward for sound properly.
-
Ok I think I fixed the issue with sound, at the very least its now working through novnc. The vnc-audio.ini needed to be changed. It looks like tcpserver isnt able to lookup localhost via dns so I changed it to 127.0.0.1. I sent a pull request, but Im somewhat new to git so the build file for the docker needs to be changed back to the main repo from mine.
-
OK I was looking more at the dockerfile on git, I dont think the environmental variables for the ports will change anything as they are currently. The ports are exposes as the actual ports and not the variables. So even if you change the variable the port is still the same. I could be wrong as this is really the first time Im looking at ta dockerfile ment for dockerman. I tested on the fork I made and it seems to work the way I think it should when I do this: # Configure required ports ENV \ PORT_SSH="2222" \ PORT_VNC="5904" \ PORT_AUDIO_STREAM="5905" \ PORT_NOVNC_WEB="18083" \ PORT_AUDIO_WEBSOCKET="32123" # Expose the required ports EXPOSE ${PORT_SSH} EXPOSE ${PORT_VNC} EXPOSE ${PORT_AUDIO_STREAM} EXPOSE ${PORT_NOVNC_WEB} EXPOSE ${PORT_AUDIO_WEBSOCKET} Note I left in port changes I had made for myself but I tested by changing the env variables for vnc and audio for 5908 and 5909. I can say for sure that I can vnc into 5908, I still have no audio so thats still an issue but I dont "think" its related to this. Unless im using port 32123 somewhere and do not realize it.
-
For the life of me I can not get sound to work via vnc with this container. At first I attempted to change the vnc ports as I do have another docker that also used 5901 but when changing the enviormental values, the docker still went with the defaults. I went as far as forking the docker and hardcoding the changes. While it did change the ports sounds still does not work for me. Its the same error in the error log as the other person who had the issue had, "tcpserver: fatal: no IP address for localhost". Any thoughts on things I can try?
-
I to also have the issue where the link has the wrong port. I also have the myserver plugin and due to that when i try going to the qr code with the correct port I get this error An error occurred during a connection to *obfuscated*.myunraid.net:2378. SSL received a record that exceeded the maximum permissible length. Error code: SSL_ERROR_RX_RECORD_TOO_LONG The page you are trying to view cannot be shown because the authenticity of the received data could not be verified. Please contact the website owners to inform them of this problem. For some reason I am unable to get the app to connect manually ether, it just sits and spins.
-
thats an older pic, the forward port is just 5443
-
Also here is my port forward
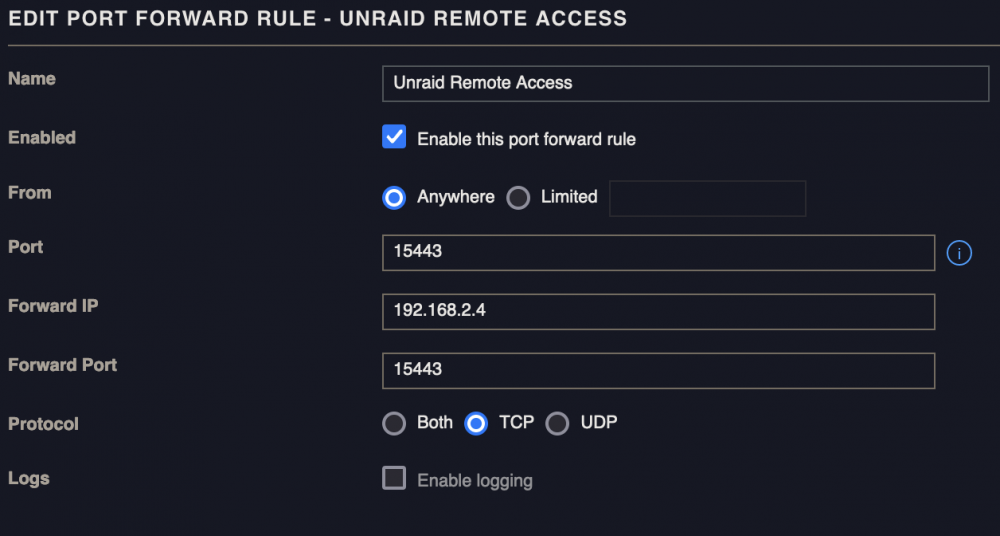
-
I'm having issues getting remote access working. I don't technically need it but its there and I'd like to figure out why its not working. Diagnostics attached. Also here is the output of php /usr/local/emhttp/plugins/dynamix/include/UpdateDNS.php -v (Output is anonymized, use '-vv' to see full details) Unraid OS 6.10.0-rc4 with My Servers plugin version 2022.03.01.2301 ✅ Signed in to Unraid.net as ChronoStriker1 Use SSL is auto ✅ Rebind protection is disabled Local Access url: https://192-168-2-4.hash.myunraid.net:5443 ✅ 192-168-2-4.hash.myunraid.net resolves to 192.168.2.4 Remote Access url: https://[redacted].hash.myunraid.net:[redacted] ✅ [redacted].hash.myunraid.net resolves to [redacted] IP address changes were detected, nginx was reloaded Request: { "keyfile": "[redacted]", "plgversion": "2022.03.01.2301", "internalhostname": "*.hash.myunraid.net", "internalport": "5443", "internalprotocol": "https", "remoteaccess": "yes", "servercomment": "Media server", "servername": "Tower", "internalip": "192.168.2.4", "externalhostname": "*.hash.myunraid.net", "externalport": "[redacted]", "externalprotocol": "https" } Response (HTTP 200): [] success tower-diagnostics-20220328-2023.zip
-
OK I see part of the problem looking at the docker install instructions from the github of happypandax you need to create the config.yaml and create a plugins directory in the data folder. If you don't it will start creating those files in the docker image itself which you don't want. It should look like bellow. You can do that after the first start up, just stop it and do that then start it up. It will start using the correct folders after that. import: skip_existing_galleries: true transparent_nested_folders: true watch: enable: true dirs: - /content options: /content: import.scan_on_startup: true plugin: plugin_dir: /data/plugins server: host: 0.0.0.0 The last line will allow you to use the desktop client to connect to the server
-
You may want to add the download directory as a configurable path since content appears to only be for uploading things and not where its placing files once they are in your library from what I can tell. Since appdata is on peoples cache drive they will probably want to move those files to somewhere on a share. Honestly this app is a bit confusing on its usage.
-
The config.yaml is not something that is shared in the appdata directory, it really needs to be. Also since the happypandax user the docker runs as is not root you cant install vi or nano in the docker image to edit that file that way ether. Currently I am also seeing that its not following the content directory so everything downloaded seems to live in the appdata folder, but out of the two things that it downloaded from exhentai for me only one shows and the logs are less than helpful.
-
Was just checking your script out. It works but if you don't already have the BACKUP_DEST_APP folder already created it never backs anything up due to the location not being writable. You may want to do a check for it or at least output an error. The other two work find since you are always creating them.
-
Im trying to download something with radarr right now and all im getting it .meta files and in rtorrent they are showing as "Tracker: [DHT search unsuccessful.]" any ideas? EDIT Well in case anyone is wondering if you are checking a torrent magnets wont change from meta to torrents until its done... Im checking a 2.1Tb torrent so I have a bunch of .meta files. Pausing the checking and they all converted to torrents.
-
Can you include httpcfg in the docker so I can enable SSL. Thanks
-
I finally got it to startup again but will only work when vpn is off. Nothing I did should have had any affect though
-
After updating to 6.2.0-rc4 sab stopped letting me connect to it while vpn is enabled. Any help would be appreciated usermod: no changes [info] Env var PUID defined as 99 [info] Env var PGID defined as 100 [info] Permissions already set for /config and /data [info] Starting Supervisor... 2016-08-23 15:38:14,557 CRIT Set uid to user 0 2016-08-23 15:38:14,600 INFO Included extra file "/etc/supervisor/conf.d/sabnzbdvpn.conf" during parsing 2016-08-23 15:38:14,603 INFO supervisord started with pid 19 2016-08-23 15:38:15,605 INFO spawned: 'start-script' with pid 22 2016-08-23 15:38:15,606 INFO spawned: 'sabnzbd-script' with pid 23 2016-08-23 15:38:15,607 INFO spawned: 'privoxy-script' with pid 24 2016-08-23 15:38:15,615 DEBG 'privoxy-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-08-23 15:38:15,615 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 15:38:15,615 INFO success: sabnzbd-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 15:38:15,615 INFO success: privoxy-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 15:38:15,617 DEBG 'sabnzbd-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-08-23 15:38:15,675 DEBG 'start-script' stdout output: [info] VPN is enabled, beginning configuration of VPN 2016-08-23 15:38:15,720 DEBG 'start-script' stdout output: [info] VPN provider defined as pia 2016-08-23 15:38:15,755 DEBG 'start-script' stdout output: [info] VPN default certs defined, copying to /config/openvpn/... 2016-08-23 15:38:15,759 DEBG 'start-script' stdout output: [info] VPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn 2016-08-23 15:38:15,791 DEBG 'start-script' stdout output: [info] Env vars defined via docker -e flags for remote host, port and protocol, writing values to ovpn file... 2016-08-23 15:38:15,804 DEBG 'start-script' stdout output: [info] VPN provider remote gateway defined as us-midwest.privateinternetaccess.com [info] VPN provider remote port defined as 1198 [info] VPN provider remote protocol defined as udp 2016-08-23 15:38:15,813 DEBG 'start-script' stdout output: [info] VPN provider username defined as user 2016-08-23 15:38:15,821 DEBG 'start-script' stdout output: [info] VPN provider password defined as password 2016-08-23 15:38:15,916 DEBG 'start-script' stdout output: [info] Default route for container is 172.17.0.1 2016-08-23 15:38:15,923 DEBG 'start-script' stdout output: [info] Setting permissions recursively on /config/openvpn... 2016-08-23 15:38:15,969 DEBG 'start-script' stdout output: [info] Adding 192.168.1.0/24 as route via docker eth0 2016-08-23 15:38:15,970 DEBG 'start-script' stdout output: [info] ip route defined as follows... 2016-08-23 15:38:15,970 DEBG 'start-script' stdout output: -------------------- 2016-08-23 15:38:15,971 DEBG 'start-script' stdout output: default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.4 192.168.1.0/24 via 172.17.0.1 dev eth0 2016-08-23 15:38:15,971 DEBG 'start-script' stdout output: -------------------- 2016-08-23 15:38:15,987 DEBG 'start-script' stdout output: [info] iptable_mangle module not supported, attempting to load... 2016-08-23 15:38:15,988 DEBG 'start-script' stderr output: modprobe: FATAL: Module iptable_mangle not found in directory /lib/modules/4.4.18-unRAID 2016-08-23 15:38:15,988 DEBG 'start-script' stdout output: [warn] iptable_mangle module not supported, you will not be able to connect to Deluge webui or Privoxy outside of your LAN 2016-08-23 15:38:16,029 DEBG 'start-script' stdout output: [info] Adding additional incoming port 8081 for eth0 2016-08-23 15:38:16,051 DEBG 'start-script' stdout output: [info] Adding additional outgoing port 8081 for eth0 2016-08-23 15:38:16,057 DEBG 'start-script' stdout output: [info] iptables defined as follows... -------------------- 2016-08-23 15:38:16,058 DEBG 'start-script' stdout output: -P INPUT DROP -P FORWARD ACCEPT -P OUTPUT DROP -A INPUT -i tun0 -j ACCEPT -A INPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1198 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8080 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8080 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8090 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8090 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8081 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8081 -j ACCEPT -A INPUT -p udp -m udp --sport 53 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT -A OUTPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1198 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8080 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8080 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8090 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8090 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8081 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8081 -j ACCEPT -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT 2016-08-23 15:38:16,058 DEBG 'start-script' stdout output: -------------------- [info] nameservers 2016-08-23 15:38:16,059 DEBG 'start-script' stdout output: nameserver 8.8.8.8 nameserver 8.8.4.4 2016-08-23 15:38:16,059 DEBG 'start-script' stdout output: -------------------- [info] Starting OpenVPN... 2016-08-23 15:38:16,123 DEBG 'start-script' stdout output: Tue Aug 23 15:38:16 2016 OpenVPN 2.3.11 x86_64-unknown-linux-gnu [sSL (OpenSSL)] [LZO] [EPOLL] [MH] [iPv6] built on May 12 2016 Tue Aug 23 15:38:16 2016 library versions: OpenSSL 1.0.2h 3 May 2016, LZO 2.09 Tue Aug 23 15:38:16 2016 WARNING: file 'credentials.conf' is group or others accessible 2016-08-23 15:38:16,164 DEBG 'start-script' stdout output: Tue Aug 23 15:38:16 2016 UDPv4 link local: [undef] Tue Aug 23 15:38:16 2016 UDPv4 link remote: [AF_INET]108.61.228.84:1198 2016-08-23 15:38:16,321 DEBG 'start-script' stdout output: Tue Aug 23 15:38:16 2016 [45f105e29e6cc7ffad9ccd7777a88234] Peer Connection Initiated with [AF_INET]108.61.228.84:1198 2016-08-23 15:38:18,761 DEBG 'start-script' stdout output: Tue Aug 23 15:38:18 2016 TUN/TAP device tun0 opened Tue Aug 23 15:38:18 2016 do_ifconfig, tt->ipv6=0, tt->did_ifconfig_ipv6_setup=0 Tue Aug 23 15:38:18 2016 /usr/bin/ip link set dev tun0 up mtu 1500 2016-08-23 15:38:18,763 DEBG 'start-script' stdout output: Tue Aug 23 15:38:18 2016 /usr/bin/ip addr add dev tun0 local 10.126.1.6 peer 10.126.1.5 2016-08-23 15:38:18,767 DEBG 'start-script' stdout output: Tue Aug 23 15:38:18 2016 Initialization Sequence Completed 2016-08-23 15:38:18,856 DEBG 'privoxy-script' stdout output: [info] Privoxy set to disabled 2016-08-23 15:38:18,856 DEBG fd 19 closed, stopped monitoring <POutputDispatcher at 47772837695712 for <Subprocess at 47772837516064 with name privoxy-script in state RUNNING> (stderr)> 2016-08-23 15:38:18,856 DEBG fd 15 closed, stopped monitoring <POutputDispatcher at 47772837560048 for <Subprocess at 47772837516064 with name privoxy-script in state RUNNING> (stdout)> 2016-08-23 15:38:18,856 INFO exited: privoxy-script (exit status 0; expected) 2016-08-23 15:38:18,856 DEBG received SIGCLD indicating a child quit 2016-08-23 15:38:18,887 DEBG 'sabnzbd-script' stdout output: [info] All checks complete, starting SABnzbd...
-
I dont think its a browser issue because I cant even telnet to port 8112
-
This looks like a successful start to me, so your attempting to connect to the webui inside your lan yes not over the internet right? Sent from my SM-G900F using Tapatalk correct
-
I just updated to 6.2.0-rc4 and it seems my issues have returned. Cant connect via vpn or without this time around. I have even tried redoing the entire install fresh, backing up the old config folder. Needs some help (side note sab seems to have stopped working with the vpn but works without) I turned on debugging in the hopes it would show more but Im not seeing anything. usermod: no changes [info] Env var PUID defined as 99 [info] Env var PGID defined as 100 [info] Setting permissions recursively on /config and /data... [info] Starting Supervisor... 2016-08-23 14:35:13,489 CRIT Set uid to user 0 2016-08-23 14:35:13,489 INFO Included extra file "/etc/supervisor/conf.d/delugevpn.conf" during parsing 2016-08-23 14:35:13,492 INFO supervisord started with pid 21 2016-08-23 14:35:14,495 INFO spawned: 'start-script' with pid 24 2016-08-23 14:35:14,496 INFO spawned: 'webui-script' with pid 25 2016-08-23 14:35:14,498 INFO spawned: 'deluge-script' with pid 26 2016-08-23 14:35:14,499 INFO spawned: 'privoxy-script' with pid 27 2016-08-23 14:35:14,567 DEBG 'privoxy-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-08-23 14:35:14,567 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: webui-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: deluge-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: privoxy-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,495 INFO spawned: 'start-script' with pid 24 2016-08-23 14:35:14,496 INFO spawned: 'webui-script' with pid 25 2016-08-23 14:35:14,498 INFO spawned: 'deluge-script' with pid 26 2016-08-23 14:35:14,499 INFO spawned: 'privoxy-script' with pid 27 2016-08-23 14:35:14,567 DEBG 'privoxy-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-08-23 14:35:14,567 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: webui-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: deluge-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,567 INFO success: privoxy-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-08-23 14:35:14,828 DEBG 'deluge-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-08-23 14:35:14,845 DEBG 'start-script' stdout output: [info] VPN is enabled, beginning configuration of VPN 2016-08-23 14:35:15,059 DEBG 'start-script' stdout output: [info] VPN provider defined as pia 2016-08-23 14:35:15,064 DEBG 'start-script' stdout output: [info] VPN default certs defined, copying to /config/openvpn/... 2016-08-23 14:35:15,067 DEBG 'start-script' stdout output: [debug] Environment variables defined as follows BASH=/bin/bash BASHOPTS=cmdhist:complete_fullquote:extquote:force_fignore:hostcomplete:interactive_comments:progcomp:promptvars:sourcepath BASH_ALIASES=() BASH_ARGC=() BASH_ARGV=() BASH_CMDS=() BASH_LINENO=([0]="0") BASH_SOURCE=([0]="/root/start.sh") BASH_VERSINFO=([0]="4" [1]="3" [2]="42" [3]="1" [4]="release" [5]="x86_64-unknown-linux-gnu") BASH_VERSION='4.3.42(1)-release' DEBUG=true DIRSTACK=() ENABLE_PRIVOXY=no EUID=0 ) HOME=/home/nobody HOSTNAME=553ba5bc7373 HOSTTYPE=x86_64 HOST_OS=unRAID IFS=$' \t\n' LANG=en_GB.UTF-8 LAN_NETWORK=192.168.1.0/24 MACHTYPE=x86_64-unknown-linux-gnu OPTERR=1 OPTIND=1 OSTYPE=linux-gnu PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin PGID=100 PIPESTATUS=([0]="0") PPID=21 PS4='+ ' PUID=99 PWD=/ SHELL=/bin/bash SHELLOPTS=braceexpand:hashall:interactive-comments SHLVL=2 STRONG_CERTS=no SUPERVISOR_ENABLED=1 SUPERVISOR_GROUP_NAME=start-script SUPERVISOR_PROCESS_NAME=start-script TERM=xterm TZ=America/Chicago UID=0 VPN_CONFIG=/config/openvpn/openvpn.ovpn VPN_ENABLED=true VPN_PASS=PASSWORD VPN_PORT=1198 VPN_PROTOCOL=udp VPN_PROV=pia VPN_REMOTE=us-midwest.privateinternetaccess.com VPN_USER=USER _='[debug] Environment variables defined as follows' 2016-08-23 14:35:15,067 DEBG 'start-script' stdout output: [info] VPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn 2016-08-23 14:35:15,077 DEBG 'start-script' stdout output: [info] Env vars defined via docker -e flags for remote host, port and protocol, writing values to ovpn file... 2016-08-23 14:35:15,091 DEBG 'start-script' stdout output: [debug] Contents of ovpn file /config/openvpn/openvpn.ovpn as follows... 2016-08-23 14:35:15,099 DEBG 'start-script' stdout output: client dev tun resolv-retry infinite nobind persist-key cipher aes-128-cbc 1 tls-client remote-cert-tls server auth-user-pass comp-lzo verb 1 reneg-sec 0 crl-verify crl.rsa.2048.pem ca ca.rsa.2048.crt disable-occ 2016-08-23 14:35:15,099 DEBG 'start-script' stdout output: [info] VPN provider remote gateway defined as us-midwest.privateinternetaccess.com [info] VPN provider remote port defined as 1198 [info] VPN provider remote protocol defined as udp 2016-08-23 14:35:15,109 DEBG 'start-script' stdout output: [info] VPN provider username defined as USER 2016-08-23 14:35:15,115 DEBG 'start-script' stdout output: [info] VPN provider password defined as PASSWORD 2016-08-23 14:35:15,145 DEBG 'start-script' stdout output: [info] Default route for container is 172.17.0.1 2016-08-23 14:35:15,155 DEBG 'start-script' stdout output: [info] Setting permissions recursively on /config/openvpn... 2016-08-23 14:35:15,165 DEBG 'start-script' stdout output: [info] Adding 192.168.1.0/24 as route via docker eth0 2016-08-23 14:35:15,166 DEBG 'start-script' stdout output: [info] ip route defined as follows... -------------------- 2016-08-23 14:35:15,167 DEBG 'start-script' stdout output: default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.11 192.168.1.0/24 via 172.17.0.1 dev eth0 2016-08-23 14:35:15,168 DEBG 'start-script' stdout output: -------------------- 2016-08-23 14:35:15,187 DEBG 'start-script' stdout output: [debug] Modules currently loaded for kernel 2016-08-23 14:35:15,188 DEBG 'start-script' stdout output: Module Size Used by tun 16556 0 xt_nat 1849 14 veth 4665 0 ipt_MASQUERADE 1213 15 nf_nat_masquerade_ipv4 1865 1 ipt_MASQUERADE iptable_nat 1831 1 nf_conntrack_ipv4 5810 2 nf_nat_ipv4 4327 1 iptable_nat iptable_filter 1528 1 ip_tables 9422 2 iptable_filter,iptable_nat nf_nat 9852 3 nf_nat_ipv4,xt_nat,nf_nat_masquerade_ipv4 md_mod 36268 5 r8169 57980 0 mii 3523 1 r8169 mxm_wmi 1507 0 coretemp 5276 0 kvm 268324 0 i2c_i801 10759 0 ahci 26003 5 libahci 19067 1 ahci pata_jmicron 2563 0 sata_sil24 10375 2 wmi 6754 1 mxm_wmi acpi_cpufreq 6306 1 2016-08-23 14:35:15,189 DEBG 'start-script' stdout output: [info] iptable_mangle module not supported, attempting to load... 2016-08-23 14:35:15,190 DEBG 'start-script' stderr output: modprobe: FATAL: Module iptable_mangle not found in directory /lib/modules/4.4.18-unRAID 2016-08-23 14:35:15,190 DEBG 'start-script' stdout output: [warn] iptable_mangle module not supported, you will not be able to connect to Deluge webui or Privoxy outside of your LAN 2016-08-23 14:35:15,284 DEBG 'start-script' stdout output: [info] iptables defined as follows... -------------------- 2016-08-23 14:35:15,285 DEBG 'start-script' stdout output: -P INPUT DROP -P FORWARD ACCEPT -P OUTPUT DROP -A INPUT -i tun0 -j ACCEPT -A INPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1198 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8112 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8112 -j ACCEPT -A INPUT -s 192.168.1.0/24 -i eth0 -p tcp -m tcp --dport 58846 -j ACCEPT -A INPUT -p udp -m udp --sport 53 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT -A OUTPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1198 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8112 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8112 -j ACCEPT -A OUTPUT -d 192.168.1.0/24 -o eth0 -p tcp -m tcp --sport 58846 -j ACCEPT -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT 2016-08-23 14:35:15,286 DEBG 'start-script' stdout output: -------------------- 2016-08-23 14:35:15,286 DEBG 'start-script' stdout output: [info] nameservers 2016-08-23 14:35:15,286 DEBG 'start-script' stdout output: nameserver 8.8.8.8 nameserver 8.8.4.4 2016-08-23 14:35:15,286 DEBG 'start-script' stdout output: -------------------- [info] Starting OpenVPN... 2016-08-23 14:35:15,457 DEBG 'start-script' stdout output: Tue Aug 23 14:35:15 2016 OpenVPN 2.3.11 x86_64-unknown-linux-gnu [sSL (OpenSSL)] [LZO] [EPOLL] [MH] [iPv6] built on May 12 2016 Tue Aug 23 14:35:15 2016 library versions: OpenSSL 1.0.2h 3 May 2016, LZO 2.09 Tue Aug 23 14:35:15 2016 WARNING: file 'credentials.conf' is group or others accessible 2016-08-23 14:35:15,522 DEBG 'start-script' stdout output: Tue Aug 23 14:35:15 2016 UDPv4 link local: [undef] Tue Aug 23 14:35:15 2016 UDPv4 link remote: [AF_INET]108.61.101.135:1198 2016-08-23 14:35:15,679 DEBG 'start-script' stdout output: Tue Aug 23 14:35:15 2016 [6c497c2c10f107933f06d197388f4eaa] Peer Connection Initiated with [AF_INET]108.61.101.135:1198 2016-08-23 14:35:18,162 DEBG 'start-script' stdout output: Tue Aug 23 14:35:18 2016 TUN/TAP device tun0 opened Tue Aug 23 14:35:18 2016 do_ifconfig, tt->ipv6=0, tt->did_ifconfig_ipv6_setup=0 Tue Aug 23 14:35:18 2016 /usr/bin/ip link set dev tun0 up mtu 1500 2016-08-23 14:35:18,163 DEBG 'start-script' stdout output: Tue Aug 23 14:35:18 2016 /usr/bin/ip addr add dev tun0 local 10.120.1.6 peer 10.120.1.5 2016-08-23 14:35:18,168 DEBG 'start-script' stdout output: Tue Aug 23 14:35:18 2016 Initialization Sequence Completed 2016-08-23 14:35:18,183 DEBG 'privoxy-script' stdout output: [info] Privoxy set to disabled 2016-08-23 14:35:18,183 DEBG fd 24 closed, stopped monitoring <POutputDispatcher at 47802245469032 for <Subprocess at 47802245346944 with name privoxy-script in state RUNNING> (stderr)> 2016-08-23 14:35:18,184 DEBG fd 20 closed, stopped monitoring <POutputDispatcher at 47802245468600 for <Subprocess at 47802245346944 with name privoxy-script in state RUNNING> (stdout)> 2016-08-23 14:35:18,184 INFO exited: privoxy-script (exit status 0; expected) 2016-08-23 14:35:18,184 DEBG received SIGCLD indicating a child quit 2016-08-23 14:35:18,207 DEBG 'deluge-script' stdout output: [info] Deluge daemon not running, marking as first run 2016-08-23 14:35:19,043 DEBG 'deluge-script' stdout output: [warn] PIA incoming port is not an integer, downloads will be slow, does PIA remote gateway supports port forwarding? 2016-08-23 14:35:19,057 DEBG 'deluge-script' stdout output: [info] All checks complete, starting Deluge... 2016-08-23 14:35:21,526 DEBG 'webui-script' stdout output: [info] Starting Deluge webui... 2016-08-23 14:35:21,869 DEBG 'deluge-script' stdout output: Setting random_port to False.. Configuration value successfully updated. 2016-08-23 14:35:22,183 DEBG 'deluge-script' stdout output: Setting listen_ports to (6890, 6890).. Configuration value successfully updated. 2016-08-23 14:35:22,207 DEBG 'deluge-script' stdout output: [debug] VPN incoming port is 6890 [debug] Deluge incoming port is 6890 [debug] VPN IP is 10.120.1.6 [debug] Deluge IP is 10.120.1.6 [debug] Sleeping for 10 mins before rechecking listen interface and port (port checking is for PIA only) 2016-08-23 14:45:22,688 DEBG 'deluge-script' stdout output: [warn] PIA incoming port is not an integer, downloads will be slow, does PIA remote gateway supports port forwarding? [debug] VPN incoming port is 6890 2016-08-23 14:45:22,689 DEBG 'deluge-script' stdout output: [debug] Deluge incoming port is 6890 [debug] VPN IP is 10.120.1.6 [debug] Deluge IP is 10.120.1.6
-
Well thats strange, after fixing the issue I was having with deluge, I was turning vpn back on for sab to get you the requested logs and its working... Deluges issues shouldn't have affected it so I have no idea whats going on
-
no this isnt true, this issue is a config file issue with deluge, the issue with sab is not related to this. please can you update the docker image by forcing an update (6.1.9 bug doesnt show updates) and try again, if its still reporting the same thing then stop the container and rename deluge config file in /config/core.conf to core.old, then start the container, this wll reset your configuration so you will need to reconfigure deluge but should get you up and running. You are correct I needed to rename the deluge config and restart it. Oddly enough it still kept most of my configs.

