




jenga201
Members
-
Joined
-
Last visited
Everything posted by jenga201
-
Ah gotcha. Thanks for that info. I saw the lost+found dir and found it to be a single chunk proxmox backup file. I've scanned that and re-backed up the vm.
-
Awesome, Thanks JorgeB! I can see all the missing shares and the data rebuild is progressing. For anybody else, this disk wasn't actually bad. It was just the file system was corrupted. All I really had to do was; start in maintenance mode check & fix the file system stop the array mount the disk using unassigned devices unmount start the array normally wait for the Data-Rebuild to finish
-
No, I believe the file system is still corrupt in the parity (if that's possible). I'm waiting for the parity to finish rebuilding before fixing the file system on the good disk. About 2 days to go
-
Thank you so much, JorgeB. I replaced the failed drive, started the array and parity started to rebuild. The old drive was mountable using unassigned disk drives and all data seemed in tact. Worst case, I can copy from the old drive if the disk11 FS is still corrupt after parity rebuild.
-
Thanks. I started the array in maintenance mode and went to disk11. The Check button output Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... Metadata CRC error detected at 0x47dddd, xfs_finobt block 0x20/0x1000 btree block 0/4 is suspect, error -74 sb_fdblocks 3223950395, counted 3251191352 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 5 - agno = 6 - agno = 8 - agno = 12 - agno = 2 - agno = 4 - agno = 3 - agno = 7 - agno = 9 - agno = 10 - agno = 11 - agno = 14 - agno = 13 - agno = 1 No modify flag set, skipping phase 5 Inode allocation btrees are too corrupted, skipping phases 6 and 7 No modify flag set, skipping filesystem flush and exiting. The Fix command output Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. I see a button that says Zero Log, but I'm not sure that's what I should do. What is the preferred process after this? Should I; 1) mount /dev/md11p1 /temp/dir 2) unmount /temp/dir 3) Refresh WebUI disk11 and try to re-run Check/Fix ?
-
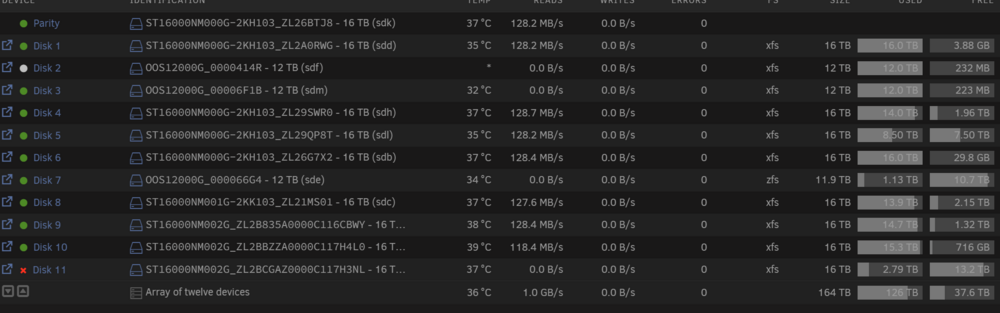
A hard drive failed on Friday and the replacements will arrive on Monday. There were a couple shares set to using only the drive that failed. These shares were readable Friday/Saturday, but do not exist today Sunday. Early Saturday a Read-Check started, which is still running and has not shown any read errors corrected. The failed drive is in an expected I/O error state UnRaid sees an expected amount of data on this drive and the Parity disk is still OK. (I remember about 2.8TB data used) Will I still be OK to replace the failed drive in this state? Any help would be much appreciated, Thank you! beast-diagnostics-20250202-0815.zip


-
How can the ports be mapped using the RustDeskServer-AiO container? I'm trying to specify an ip on my custom network, like normal when setting up containers. The ports are only mapped when using the Bridge network, and those are internal docker ips. Also, using network Host doesn't map ports. Edit: Well, it works using host even without ports mapped, but doesn't with custom bridges.


-
This was my bad. I had the warning set to 'unmonitored' and thought it would go away on rescan. Putting it back into monitoring and rescanning gives no more warnings.
-
I'm getting a Fix Common Problems warning; disklocation-master.plg Not Compatible with Unraid version 6.11.5 I know this topic has been discussed, but I'm not sure what the resolution is. Unraid Version: 6.12.3 I've reinstalled via Apps. What can I do to get this warning solved?
-
https://github.com/Jackett/Jackett/issues/13573 According to the forums, the API will be down for maintenance until July 1
-
Thanks for some info. I'm using PIA and it doesn't seem they've updated to use any token system. I re-made the docker container and found there have been a bunch of parameter updates. Not sure why this happened, but keeping my configurations & remaking the unraid docker container with the same info seemed to do the trick.
-
I've upgraded to unraid 6.12.1 and am having trouble starting up the sabnzbd container again. These are the logs; sabnzbd.txt It seems the app attempts to start, then restart, then the UI isn't accessible. I had a large queue of files during the upgrade & restart. The container should have shut down cleanly. Could the program be choking on hashing a large queue on start? Are there any ways to clear the queue from command line or do some other diagnostic? Thanks for any replies!
-
My issue was due to a PIA update to their 'Split Tunnel' feature. I added in an explicit rule to bypass the vpn for my local network. Thanks for the help looking into this unrelated issue
-
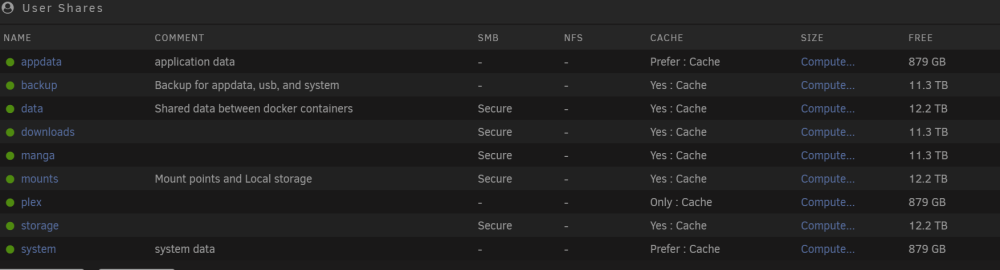
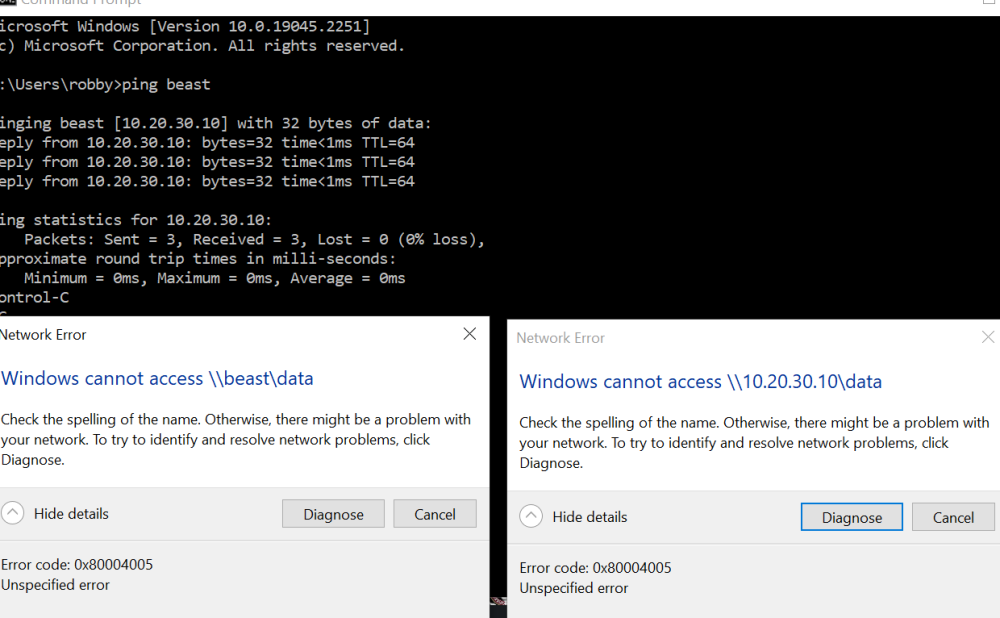
I wasn't aware accessing the shares using the IP was a problem. None of my shares are public. I can resolve the server name, but cannot access it through windows file explorer. It's the same error using the name or ip. As a side note, I've had this share configuration for probably 10 years without any issues.
-
beast-diagnostics-20221115-1655.zip Here you go. Thanks for taking a look
-
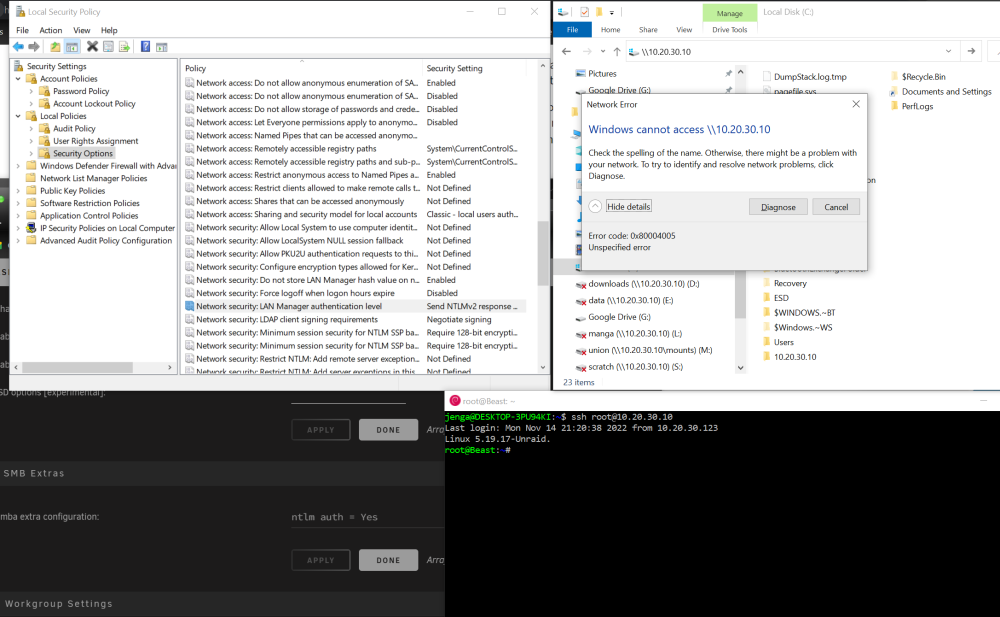
I'm having this same issue with the 6.11.3 upgrade. I'm not using AD. I've set "ntlm auth = Yes" in SMB Extras and set the network security GPO to NTLMv2 only (and combinations of either/or). Are there any other diagnostics or solutions I could do to fix this issue?
-
+1 to update iotop / iftop. I haven't been able to run these for a couple years due to Traceback (most recent call last): File "/usr/sbin/iotop", line 17, in <module> main() File "/usr/lib64/python2.7/site-packages/iotop/ui.py", line 620, in main main_loop() File "/usr/lib64/python2.7/site-packages/iotop/ui.py", line 610, in <lambda> main_loop = lambda: run_iotop(options) File "/usr/lib64/python2.7/site-packages/iotop/ui.py", line 508, in run_iotop return curses.wrapper(run_iotop_window, options) File "/usr/lib64/python2.7/curses/wrapper.py", line 22, in wrapper stdscr = curses.initscr() File "/usr/lib64/python2.7/curses/__init__.py", line 33, in initscr fd=_sys.__stdout__.fileno()) _curses.error: setupterm: could not find terminal Thank you!
-
Restarting the container or making any changes attempts to remake the mysql db. This clears out any saved configurations. => Installing MySQL ... 220123 04:52:59 mysqld_safe Logging to syslog. 220123 04:52:59 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql ERROR 1396 (HY000) at line 1: Operation CREATE USER failed for 'rootuser'@'localhost' => Database created! The mysql db needs to be persisted to appdata to prevent this.
-
Ok, it seems to work using the sg_start and sdparm commands only. The UI just doesn't reflect the state of the drive properly. I think the read errors are due to spinning down the drive while it was being accessed. They aren't going away, so I'll probably just try replacing/formatting that drive again.
-
I didn't mean to imply the syslog errors in my previous post were read errors. This is after a parity check on a previously good drive. Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826600 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826608 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826616 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826624 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826632 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826640 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826648 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826656 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826664 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826672 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826680 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826688 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826696 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826704 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826712 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826720 Oct 12 09:42:17 Beast kernel: md: disk7 read error, sector=5848826728 Oct 12 09:43:55 Beast kernel: md: sync done. time=45545sec The unraid icon remained green and data was still immediately accessible. The particular drive I tested with was not showing any traffic throughout my testing. I did try using this command, but there was no output; sg_start --readonly --pc=3 /dev/sde

-
Thanks for making this a plugin. Hope I can help with some diagnostics. HUS724030ALS640 Fail with *Temp and drive not spun down. Still operational, seemingly no effect. Getting read errors after a reboot. Oct 11 20:38:24 Beast kernel: mdcmd (47): spindown 7 Oct 11 20:38:24 Beast kernel: md: do_drive_cmd: disk7: ATA_OP e0 ioctl error: -5 Oct 11 20:38:24 Beast emhttpd: error: mdcmd, 2723: Input/output error (5): write Oct 11 20:38:24 Beast SAS Assist v0.6[27532]: spinning down slot 7, device /dev/sde (/dev/sg4) Slot: 06:00.0 Class: Serial Attached SCSI controller [0107] Vendor: Broadcom / LSI [1000] Device: SAS2116 PCI-Express Fusion-MPT SAS-2 [Meteor] [0064] SVendor: Broadcom / LSI [1000] SDevice: SAS 9201-16i [30c0] Rev: 02 NUMANode: 0

-
Ok I see. I'll have to update the plugin when I get a chance Hey, Thanks for your work on this plugin! Is it possible to also add SAS support to the HDD Temperature sensor? Here's a sample output;
-
You can adjust that in the IPMI Tool settings page. Settings> Display Settings> Dashboard Sensors
-
Ok, Thanks for your response.
-
Is it possible to compile ProFTPD with other modules? I'm using LDAP for various services and would like to use it for FTPS accounts as well. http://www.proftpd.org/docs/contrib/mod_ldap.html Thanks for the plugin!










