LammeN3rd
Members
-
Joined
-
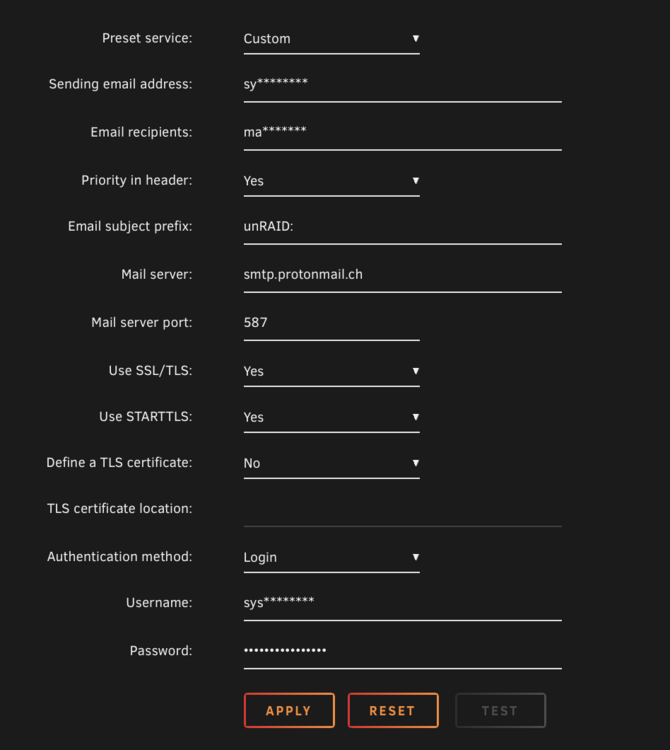
Email notifications with proton SMTP and Unraid work now!! I have included my settings below
-
That's a bummer, just upgraded my server to Unraid 7.0.1 will have to find an other smtp option unfortunately
-
has anyone found a solution for this problem? also switched to proton and this not working is not great
-
I think this is a long overdue change! chasing more and more new users is just not sustainable in the long run! All current users being grandfathered in is great but as a user of a Pro licence for the last 6 years I would recommend looking at the model of Nabucasa (home assistant) and developing additional services for unRAID that do require a subscription for legacy users! I love Unraid and hope to use it for many more years, the company behind it being healthy is crucial to make that happen.
-
When Its Done™️ 😅
-
I would love to have a secure way to access my unraid server, docker containers and VM's remotely without VPN My server is great but lacks access to dockers and VM's. Secure full access to my unraid server would be a service I would happily pay a few Euro per month for
-
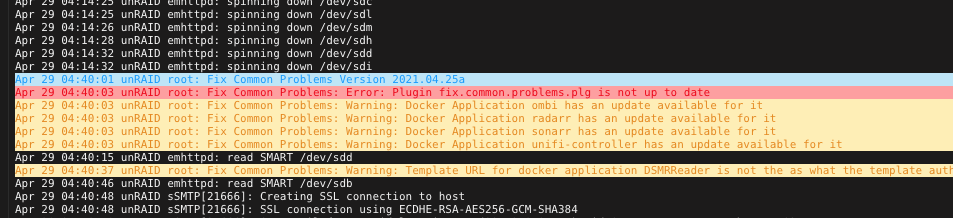
Is there a compelling reason that there is a Red error notification when there is a update for the plugin? from my perspective this should not be red since it's just a plugin update not something really bad.... There have been quite some Updates the last couple of weeks and I still jump every time I see a red error 😬
-
Great to hear! I've switched my UniFi Docker back to macvlan will report back if the issue comes up again
-
I was wondering the same thing
-
to be honest, I don't think it makes real sense to test more than the first 10% of an ssd, this would bypass this issue on all but completely empty ssd's. and ssd's don't have any speed difference for different positions of used flash when doing 100% read speed test, for a spinning disk this makes total sense but from a flash perspective a read workload has no difference as long there is data there.
-
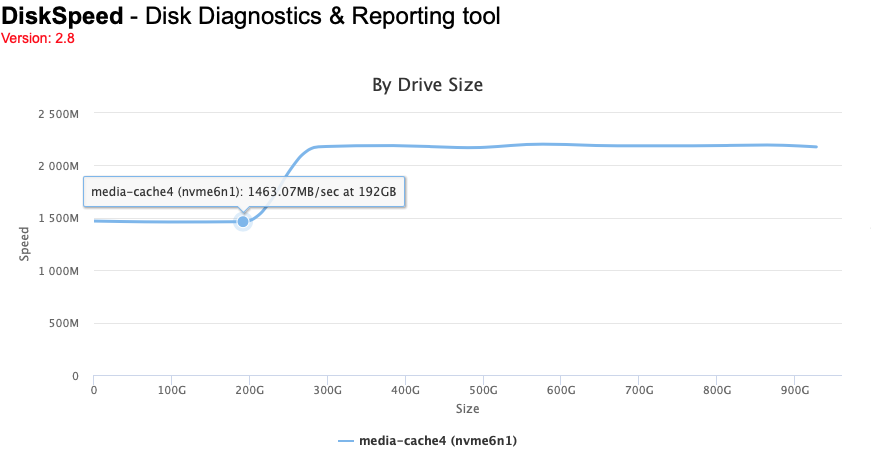
you could have a look at het used space on a drive level, but that's not that easy when drives are used in BTRFS raid other than 2 drives in raid1. NVMe drives usually report namespace utilisation so looking at that number and testing only the Namespace 1 utilization would do the trick. this is the graph from one of my NVMe drives: and this is the used space (274GB):
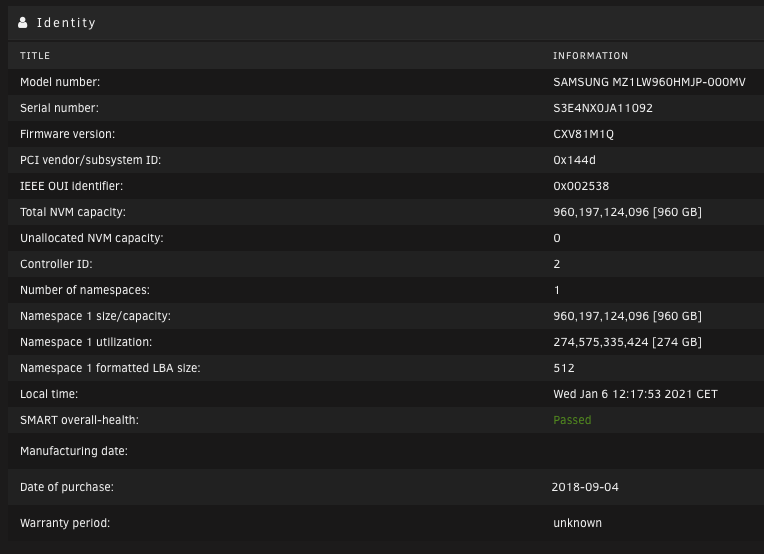
-
Just to make sure I understand it right. The flat line that basically indicates the max. interface throughput is trimmed (empty) space on the SSD? Yes, the controller or interface is probably the bottleneck
-
that's the result of trim, when data is deleted from a modern SSD trim is used to tell the controller that those blocks are free and can be erased, the controller does that and marks those blocks / pages as zeroes. when you try to read from these blocks the ssd controller does not actually read the flash it just sends you zeroes as fast as it can. this is the reason ssd's used in the unraid parity array can not be used with trim since that will invalidate the parity.
-
In safari opening the log window (top right corner) shows the login screen, the terminal and or the logs from docker containers work as normal. In Firefox the log window opens and shows the log like in 6.7.2
-
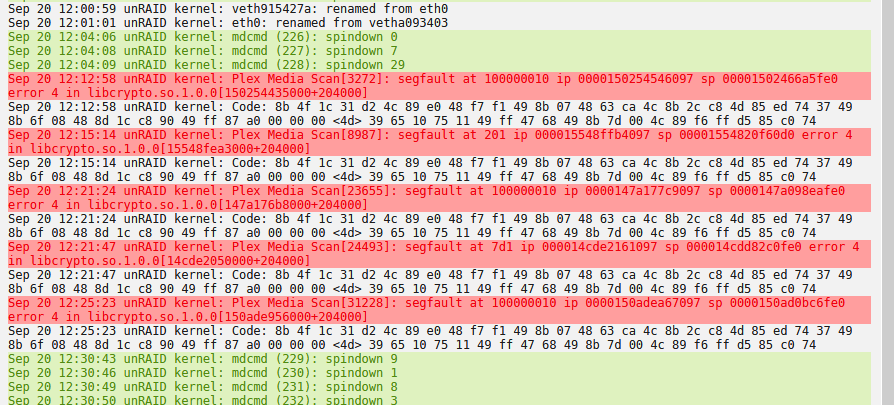
I've been noticing the same messages in my unraid log: every seems to keep working but these errors keep coming back, any ideas?