




Michael_P
Members
-
Joined
-
Last visited
Everything posted by Michael_P
-
Whatever container you have running that python instance is hitting its memory limit and is being culled. Frigate also caused the host to OOM around the same time and was killed by the kernel, you should configure the cache for the transcode to go to disk. When you've resolved it, you can restart to clear the log so FCP doesn't keep warning you.
-
You can run an extended SMART on it to be sure, and check the cables
-
At that timestamp someone ran a search for that term and it posted in your syslog, FCP will alert anytime it sees the string 'out of memory' in the log, which is why it warned you. Jul 22 14:46:30 UNRAID sudo: root : TTY=pts/2 ; PWD=/root ; USER=root ; COMMAND=/usr/bin/grep -i 'out of memory' /var/log/syslog The warning when you added the memory limit is harmless, it is just letting you know there's no swap file. The flapping I'm referring to are these entries, it's likely a container starting and stopping repeatedly: Jul 27 11:01:23 UNRAID kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth55e566d: link becomes ready Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 8(veth55e566d) entered blocking state Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 8(veth55e566d) entered forwarding state Jul 27 11:01:23 UNRAID Docker Auto Update: Restarting nextcloud-aio-redis Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 9(veth82c5f3b) entered blocking state Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 9(veth82c5f3b) entered disabled state Jul 27 11:01:23 UNRAID kernel: device veth82c5f3b entered promiscuous mode Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 9(veth82c5f3b) entered blocking state Jul 27 11:01:23 UNRAID kernel: br-33e69eebc9ce: port 9(veth82c5f3b) entered forwarding state Jul 27 11:01:24 UNRAID kernel: eth0: renamed from vethf207f46 Jul 27 11:01:24 UNRAID kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth82c5f3b: link becomes ready
-
I don't see any OOM events in your log, but it looks like one of your containers is flapping - check the container list and whichever one has the lowest uptime is the one turning on and off repeatedly. If you've already solved whatever OOM event FCP is warning you about you can reboot to clear the log so FCP stops warning you, else post the log with the event showing
-
Nice, and you should still track down whatever is spamming your log
-
Looks like both Plex and Jellyfin are running at the same time, and you have a frigate instance going too? Might be a scheduled task in one of them - how many containers are you running? Might do with disabling some, and any plugins until you track down either the culprit or whatever is spamming your log (or both).
-
I'd start with whatever is dropping all of this in your log - ps -auxf may be able to give you a clue if you don't already have an idea Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth00831b3" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0080e96" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0080e76" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0080628" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth007d5f2" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth007af2a" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0074183" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth006ddce" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth00658df" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth00634ec" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth006172c" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth005e70b" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0058271" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth003dc13" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth00387b6" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0035234" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0033662" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth00273be" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0026d90" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth002498e" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth001e4ba" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth001dedf" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0016aec" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth0006b67" disabled. Jul 16 04:48:07 Devante-NAS vnstatd[1241454]: Interface "veth000040b" disabled.
-
USB Type-C can carry USB4 data which is a lot faster, but they are usually found in those portable SSDs
-
Frigate - configure it to use disk instead of RAM to transcode. Then you can reboot to clear the log so FCP stops warning you
-
Which ever container was spawning all of those chrome processes had one of them trip the OOM at 1342. Reboot to clear the log so FCP stop warning you and if it happens again, check the config for the container
-
The cells themselves actually love heat, it's the controllers that don't. They'll throttle if they get hot tho - using a reputable brand is key if you're concerned about temps.
-
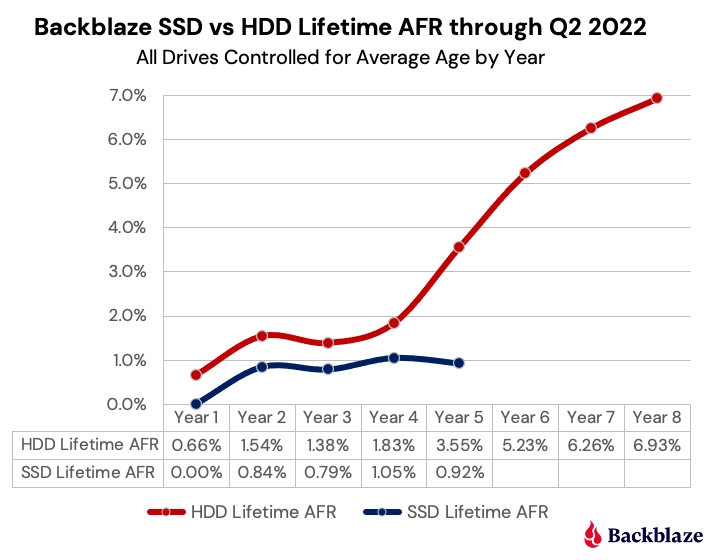
Anecdotal evidence is anecdotal, but still Early mortality is much more likely than when a drive has been in service a while - and SSDs are far and away more reliable as the days go by. Spinners spin, those parts wear out, lube dries out, etc. It's a given. SSDs couldn't care less if they sit idle for years in NAS service (if you're constantly writing to them then that's a different story). For media a media server and backup destination, at the drive sizes and cost of SSDs, parity is a wasteful, IMO of course.
-
SSDs are a lot more reliable than rust spinners, doesn't make sense to waste the storage capacity for parity unless you REALLY need uptime
-
I wouldn't bother with a parity drive for an all SSD array, or a cache drive for that matter.
-
16 gigs should be fine if you're not running VMs and such. If your Tdarr instance is caching to RAM, change it to cache to disk - same with any of your other containers (crashplan can be a hog, too). Reboot to clear the log so FCP stop warning you.
-
There's an issue with Github and CA
-
Probably not the CPU since it's a 15. If you have multiple RAM sticks, try running with 1 and then the other to see if it continues to rule out bad RAM
-
Looks like it ran OOM twice yesterday around 1920-1930, and killed the docker service both times. Doesn't appear to be any particular container, and is likely just trying to do too much at once. Check your container configs to make sure anything that you have caching to RAM isn't going to exhaust the host, and consider limiting the RAM available to the container. Reboot to clear the log so FCP stops warning you.
-
First question, is it continuing to happen? Second part of first question, if it is continuing, have you turned off those docker containers to see if it stops? If it's one of those two containers causing the problem you can follow up in the container's support thread to narrow down the issue
-
Is your system time correct?
-
Doesn't look out of the ordinary to me

-
You can also try moving it to the array to rule out the SSD
-
What? MCE can be any number of things and it's a deferred error. [Hardware Error]: Deferred error, no action required. Reboot to clear the log and to see if it happens again
-
Never had to restore so I couldn't tell you for sure, but looks like you re-install the containers then restore
-
Reckon that would depend on what you had backed up






