




T0a
Members
-
Joined
-
Last visited
Everything posted by T0a
-
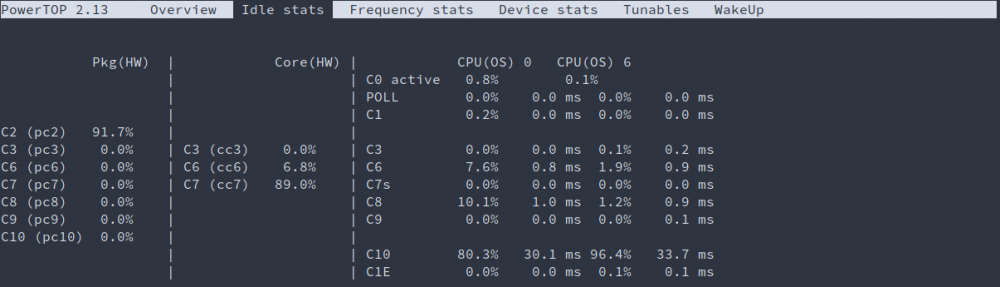
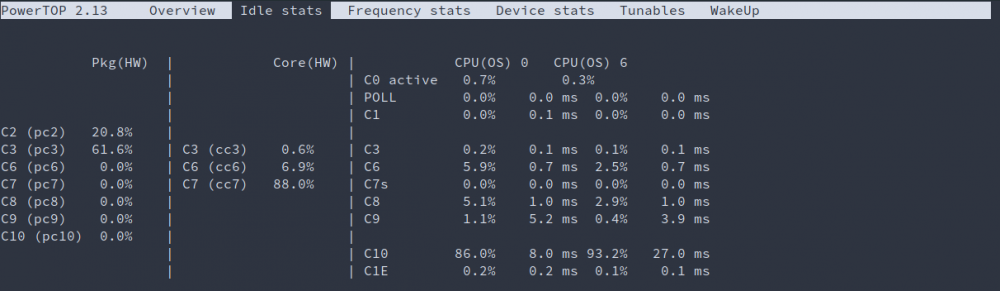
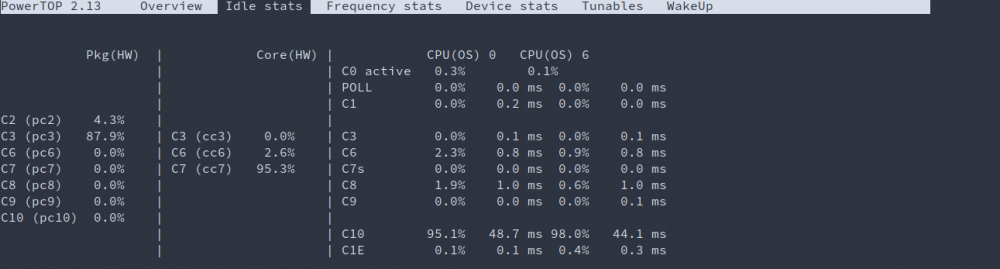
@mgutt Thank you for the hint! I added 'powertop --auto-tune' a while ago to my Go file, but couldn't find the time to measure, analyze and give feedback. Here we go now: Introduction: The system contains all parts listed in 1 with 1.1 as an upgrade. The Samsung 860 EVO M.2 with its controller is marked as passthrough device. For the measurement there is also no device connected to the Inatek KT4006, no other USB devices attached to the host either and no display plugged-in. The iGPU is blacklisted hence it is used for VM passthrough too. I use VM's as my daily driver with an external display connected. I need the Inatek KT4006, because I couldn't get my audio interface Presonos AudioBox USB reliable working otherwise. Bios Settings: The mainboard does not come with a lot of power saving settings in the BIOS. I have disabled audio, enabled Intel Speed Shift, enabled C-States and set C State Limit from AUTO to C10. Boot parameter: kernel /bzimage append video=efifb:off,vesafb:off modprobe.blacklist=i2c_i801,i2c_smbus,snd_hda_intel,snd_hda_codec_hdmi,i915,drm,drm_kms_helper,i2c_algo_bit initrd=/bzroot Measurement: 1. Unraid idle, all disks spin-up, powertop --auto-tune: 26W 2. Unraid idle, only cache spin-up, powertop --auto-tune: 19,6W 3. Unraid idle, only cache spin-up, powertop --auto-tune, Ubuntu VM idle: 19,9W to peaks 21W 4. Unraid idle, only cache spin-up, powertop --auto-tune, Ubuntu VM shutdown: 18W My initial measurement was 15W without the Inatek KT4006, Samsung 860 EVO M.2, using a i3-8100 and no powertop optimizations. In consideration that I've added two new devices an increase of 3W (with powertop optimization included) seems reasonable. However, I wonder why the hardware is not capable of reaching lower C-states. Maybe the USB add-on card prevents lower states.
-
Can highly recommend that product, the software and the developer behind it. Maxim is a great guy and a hell of a developer and engineer. Thanks for sharing here!
-
Nein, keine weiteren Parameter ausser die Post Arguments wie oben angegeben. Habe den aktualisierten Befehl ausprobiert und kann nun alle Volumes und Container zuordnen. Vielen Dank!
-
Ich habe mir den Fall nun etwas genauer angesehen. Es handelt sich bei dem Volume, welches sich nicht zuordnen laesst, um Redis. Den Grund feur die Datei kannst du hier nachlesen. 2021-08-28 12:46:51.018237367 +0200 /var/lib/docker/volumes/23b5360adabd40ddfef437d4e5702c7e07af7f578b3b2a538378c2ea8e61a964/_data/dump.rdb ======================================================================================================== Redis /var/lib/docker/(btrfs|overlay2)/.../57b5a1df778859ae545e595b285381e7f585eb547a6f731016c832cbd4072ce8 db390ed2556d /var/lib/docker/containers/db390ed2556d6cbdb41f7400615ece4cd5bf749a4309edeb67544c06efedb9ee Ich starte den Redis Container (von jj9987) mit 'redis-server --requirepass "secret"' als Post Arguments. Der Container wird fuer paperless-ng benoetigt. Ich schaue gerade in der Dokumentation von Redis, ob und wie man das Interval fuer das Snapshot Feature anpassen kann. In der Standard-Konfiguration wird die Datei alle 30 Sekunden geschrieben. Fuer die Anwendung paperless-ng ist es IMHO nicht noetig Daten in Redis dauerhaft zu persistieren. Edit: Der Befehl schaltet das Feature ab: redis-server --requirepass "secret" --save '' Wahrscheinlich muss man dann auch die Datei "dump.rdb" loeschen, sonst laed Redis bei jedem Start veraltete Daten. Mir sind die Implikationen auf paperless-ng jedoch noch nicht bewusst. Ueber "--save" kann man auch die Frequenz einstellen. Der Befehl "--save 60 1000" speichert z.B. das Dataset alle 60 Sekunden, wenn sich 1000 Keys geaendert haben. Laut diesem Artikel, wird der Snapshot nur so haeufig durchgefuehrt, wenn viele Daten durch Redis verarbeitet werden. Aktuell verarbeite ich aber keine Daten aktiv durch paperless-ng. Ich vermute, dass das Scheduling der Worker Tasks Ursache ist.
-
Seems like newer versions of paperless-ng rely on python3.9 now. Please try 'python manage.py createsuperuser'. I will adapt the first post accordingly. @jseeman Seems like. I already created a pull request to make paperless-ng work with the new Gotenberg 7 API. Waiting for the maintainers to review and merge. Will let you know, once it is available.
-
Hi @mgutt, vielen Dank fuer deine detaillierte Analyse und Schritte zur Senkung der Schreibvorgaenge. Leider habe ich ein paar Container, welche ich mit deinen Befehlen nicht identifizieren kann. In dem angefuegten Beispiel finde ich nur einen Container. Ich verwende BTRFS. $ find /var/lib/docker -type f -print0 | xargs -0 stat --format '%Y :%y %n' | sort -nr | cut -d: -f2- | head -n30 2021-08-26 14:22:10.173941747 +0200 /var/lib/docker/containers/b08e6e2d18fbb8ac7743f05c9587936cf216d07c02fb077bf36ec6ec666ddfa4/b08e6e2d18fbb8ac7743f05c9587936cf216d07c02fb077bf36ec6ec666ddfa4-json.log 2021-08-26 14:22:10.075941360 +0200 /var/lib/docker/volumes/11ad4a2d8c58a5baf36528dafe15c4d71b3b47db02676219ec4a35c4247131fc/_data/dump.rdb 2021-08-26 14:20:43.434600397 +0200 /var/lib/docker/containers/3a619f64c1353174cecf913582ffb3360a3d972521640c39d17e924f99e88d62/3a619f64c1353174cecf913582ffb3360a3d972521640c39d17e924f99e88d62-json.log 2021-08-26 14:05:40.423066270 +0200 /var/lib/docker/containers/1de8d6e23f5a1cb3c1cfe497156c557deb3c1b187d7916ab71eb2116885cd685/1de8d6e23f5a1cb3c1cfe497156c557deb3c1b187d7916ab71eb2116885cd685-json.log 2021-08-26 14:05:39.344062070 +0200 /var/lib/docker/btrfs/subvolumes/2c44fb572165fdf52a19fc518924de003750fcdbfc4074505a14cb8997477f1b/run/tomcat/tomcat9.pid 2021-08-26 14:05:31.841032871 +0200 /var/lib/docker/containerd/daemon/io.containerd.metadata.v1.bolt/meta.db 2021-08-26 14:05:31.786032657 +0200 /var/lib/docker/btrfs/subvolumes/2c44fb572165fdf52a19fc518924de003750fcdbfc4074505a14cb8997477f1b/etc/mysql/my.cnf $ csv="CONTAINER ID;NAME;SUBVOLUME\n"; for f in /var/lib/docker/image/*/layerdb/mounts/*/mount-id; do sub=$(cat $f); id=$(dirname $f | xargs basename | cut -c 1-12); csv+="$id;" csv+=$(docker ps --format "{{.Names}}" -f "id=$id")";" csv+="/var/lib/docker/.../$sub\n"; done; echo -e $csv | column -t -s';' CONTAINER ID NAME SUBVOLUME 0837668ab9aa ha-dockermon /var/lib/docker/.../c453891a316ec4eb019e3f422822522ab02eab5206d8057fb683148f9f9ee73e 1de8d6e23f5a ApacheGuacamole /var/lib/docker/.../2c44fb572165fdf52a19fc518924de003750fcdbfc4074505a14cb8997477f1b 327b99639003 mediabox-webdav /var/lib/docker/.../060bacaf2b0a5ba9da609170d23f3aa784c740013a868a7144109b5074679e8d 3332bcd89455 /var/lib/docker/.../9b2cfb3fa23e8f6e223b3e706663fcbbeebf84b8597d706c8ce23f643fc42274 3a619f64c135 paperless-ng /var/lib/docker/.../1c3de7a697750b83951615239d40a196fdfe8a3c1f14dd987ee39b28a72ee6f3 658a3cdbc4ec pyload /var/lib/docker/.../9ee162566420a1490a21a1365665b9d72bd0282f89a384950867d0142cee4cb1 85d30bcb7ebc PhotoPrism /var/lib/docker/.../afe5ba079e28dafb855219569836437f013add1ea5f4ae77972c78ac72d42c04 a486d6c7fd29 syncthing /var/lib/docker/.../42ec5e12317b47750f9c6776952678028b20416bbe868f5e152deb10bc239b56 abfd165b7c2d cyberchef /var/lib/docker/.../8437459cd2b973a976954aaa87bbe82be907bf48c106cafb2b3ea540cc460b6f b08e6e2d18fb Redis /var/lib/docker/.../230a683c4c170076532d72dd3c44fe5864ffafc3b354c3936831f86d239ca22c b6d9783d0efa borgmatic /var/lib/docker/.../00348b7c4c31d7a8c62c1d3f887db40be599d7bce20a121afd9a07c532d6c98d c0e15cf5cfee /var/lib/docker/.../202335a2b00810c0292518af7cf2985341e3953e6c5cbc86f206a8bff52a9c70 e6027b587016 /var/lib/docker/.../65e4ae75354b4593e84f8555444e9168420984d11d76365ee1ad06b6dcc4acfb $ for f in /var/lib/docker/image/btrfs/layerdb/mounts/*/mount-id; do echo $(dirname $f | xargs basename | cut -c 1-12)' (Container-ID) > '$(cat $f)' (BTRFS subvolume ID)'; done 0837668ab9aa (Container-ID) > c453891a316ec4eb019e3f422822522ab02eab5206d8057fb683148f9f9ee73e (BTRFS subvolume ID) 1de8d6e23f5a (Container-ID) > 2c44fb572165fdf52a19fc518924de003750fcdbfc4074505a14cb8997477f1b (BTRFS subvolume ID) 327b99639003 (Container-ID) > 060bacaf2b0a5ba9da609170d23f3aa784c740013a868a7144109b5074679e8d (BTRFS subvolume ID) 3332bcd89455 (Container-ID) > 9b2cfb3fa23e8f6e223b3e706663fcbbeebf84b8597d706c8ce23f643fc42274 (BTRFS subvolume ID) 3a619f64c135 (Container-ID) > 1c3de7a697750b83951615239d40a196fdfe8a3c1f14dd987ee39b28a72ee6f3 (BTRFS subvolume ID) 658a3cdbc4ec (Container-ID) > 9ee162566420a1490a21a1365665b9d72bd0282f89a384950867d0142cee4cb1 (BTRFS subvolume ID) 85d30bcb7ebc (Container-ID) > afe5ba079e28dafb855219569836437f013add1ea5f4ae77972c78ac72d42c04 (BTRFS subvolume ID) a486d6c7fd29 (Container-ID) > 42ec5e12317b47750f9c6776952678028b20416bbe868f5e152deb10bc239b56 (BTRFS subvolume ID) abfd165b7c2d (Container-ID) > 8437459cd2b973a976954aaa87bbe82be907bf48c106cafb2b3ea540cc460b6f (BTRFS subvolume ID) b08e6e2d18fb (Container-ID) > 230a683c4c170076532d72dd3c44fe5864ffafc3b354c3936831f86d239ca22c (BTRFS subvolume ID) b6d9783d0efa (Container-ID) > 00348b7c4c31d7a8c62c1d3f887db40be599d7bce20a121afd9a07c532d6c98d (BTRFS subvolume ID) c0e15cf5cfee (Container-ID) > 202335a2b00810c0292518af7cf2985341e3953e6c5cbc86f206a8bff52a9c70 (BTRFS subvolume ID) e6027b587016 (Container-ID) > 65e4ae75354b4593e84f8555444e9168420984d11d76365ee1ad06b6dcc4acfb (BTRFS subvolume ID) PS: Kann es sein, dass du vergessen hast den Befehl fuer BTRFS im Guide zu ergaenzen?
-
I switched from the 'docker.img' to a docker bind-mount directory on a separate docker share, and restored all of my docker containers via this plugin for the first time. Great experience, this feature works like a charm! After restoring and checking on the containers, the docker tab still reported 'Update available' for some of the containers. I clicked on check for updates then and everything reported as 'up-to-date'. Seems like the plugin does not fetch the version status of the container after restoring. Maybe this is intended behavior. Was not a problem for me. Just wanted to let you know and use the chance to say thank you!
-
Have you tried the PAPERLESS_OCR_LANGUAGES variable to install the language you need? To actually use these languages, also set the default OCR language of paperless: PAPERLESS_OCR_LANGUAGE. You can read more about the configuration options in the documentation here. Do you get this error for all PDF's you tested? Can you try to manually upload another document via the web interface from your host? In the best case please use something you just created via MS Word using the export to PDF function. Nothing fancy! Does this work? Then try to upload your document from the share via the web upload. Does that work then? Maybe the permissions of your consume folder are causing that issue. Trying to rule that out with the tests mentioned before. Please also check: https://paperless-ng.readthedocs.io/en/latest/troubleshooting.html#permission-denied-errors-in-the-consumption-directory Do you receive the disconnect after issuing the superuser command or is it unrelated to that command? Have you checked the docker log files?
-
What does the log tell you when you use your server IP address i.e. `redis://XXX.XXX.XXX.XX:6379`. I think `127.0.0.1` will not work, because it tries to resolve Redis in the paperless-ng container then. Keep me posted.
-
What happens when we add the 'Requires' tag to our templates when there is already an entry in your Moderation.json? Will the entry in the Moderation.json take precedence? Can we ping you to remove the the Requires tag once we updated the template? The question arised, because for paperless-ng the entry in Moderation.json looks fine, but I plan to add it to the template.
-
On iOS I use the PhotoSync app to upload my pictures and videos to an UnRaid SMB share. Though, it is not free but worth the money IMHO. Edit: Looks like the app was mentioned before.
-
Sorry for being late to the party. I think the question about why it is a good idea to stop containers when running a backup has been addressed adequately. Check out the following post for how you can achieve it:
-
Sorry, for the late response. Looks like you got your answer here. Have you checked the documentation? The variable PAPERLESS_FILENAME_DATE_ORDER you are using means something different: PAPERLESS_FILENAME_DATE_ORDER=<format>: Paperless will check the document text for document date information. Use this setting to enable checking the document filename for date information. The date order can be set to any option as specified in https://dateparser.readthedocs.io/en/latest/settings.html#date-order. The filename will be checked first, and if nothing is found, the document text will be checked as normal. Have a look at the first page of this post. We discussed changing the date order there.
-
The online app store lists it as available (https://unraid.net/community/apps?q=paperless#r). I haven't removed it. So, I have to investigate once I'm home. Update 1: I broke the template with the latest update Should have checked before submitting the changes. Will fix it now and try to get the changes to the CA ASAP Update 2: I submitted the fix for the template. We wait for getting it merged. Sorry for the trouble guys Update 3: The template is available again
-
I think concurrent access to a file based database such as SQLite is kind of a problem sometimes and results in issues like "database is locked" messages. When you are the only person using the paperless-ng instance this shouldn't be a problem though. I never tried running paperless with PostgreSQL and therefore cannot tell what's the improvement gain. I have no need to switch, because I have no problem with the SQLite database so far. Maybe @CorneliousJD can give some insides here?
-
Glad you got it working. No problem, you are welcome. Creating this template was no effort for me tbh. Credits go to the new dev Jonas Winkler for improving paperless. There is no requirement for the document name. The guesswork feature you are referring to was removed in version 0.9.9. The Redis database is just used for checking if a document is finished processing. Make sure you replace the IP in the template with the machine running the Redis database. The documents are stored in the Media folder. Make sure that this host mount points to a share on your server with enough space for the documents. The documents metadata get persisted in a SQLite database that is stored in the Data directory. It is also possible to use a full-blown SQL database such as PostgreSQL rather then the file based database. The steps to migrate from the default SQLite database to PostgreSQL are outlined in the first page of this thread. Though, documents will still be stored as files on the mapped Media share. Only metadata is persisted in the database.
-
Ich habe nicht die komplette Diskussion verfolgt aber UD kann ein Skript ausführen, sobald eine Festplatte eingebunden wird. Ein Beispiel findet sich im ersten Post des UD Threads.
-
Have you stripped away parts from the stacktrace? Is this stacktrace from the web UI? Does the docker container log contain more information? For me the error "name or service not known" looks like a typically docker container resolution issue. I've seen such errors when you register or link a service that resides outside the container and the application tries to find it inside container. How does your Redis environment configuration look like? Any chance you linked something else with a symbolic name that is not known to the container? I also wonder why the container name is "enemy-ceiling-delta-wyoming". The paperless container name is fixed to paperless-ng AFAIK or am I wrong?
-
I feel you. I run an English system too, because I prefer having technical terms in English. There is a feature request here to do so. Raise your voice.
-
It is bound to your browser localization. Is it set to german?
-
The environment variable PAPERLESS_DATE_ORDER of the original paperless meant something different. AFAIK the date format is adapted with the localization setting. Have you tried to change it to German? Also see this issue.
-
I was asked via PM how my home assistant integration with paperless-ng looks like. As stated in (3) I use the pre and post hooks to execute web hooks in order to check via home assistant whether the processing failed for uploaded documents. Thereby, I receive notifications about the import status. In the following you can find the scripts and automation: Pre-consumption script #!/usr/bin/env bash # https://paperless.readthedocs.io/en/latest/consumption.html#hooking-into-the-consumption-process echo Begin pre-processing script echo - Original filename: [${1}] curl -X POST http://<ha-ip>:8123/api/webhook/paperless_start_processing -d "{\"filename\": \"${1}\"}" -H "Content-Type:application/json" echo End pre-processing script Post-consumption script #!/usr/bin/env bash # https://paperless.readthedocs.io/en/latest/consumption.html#hooking-into-the-consumption-process echo Begin post-processing script echo - Document id: [${1}] echo - Generated filename: [${2}] echo - Source path: [${3}] echo - Thumbnail path: [${4}] echo - Download URL: [${5}] echo - Thumbnail URL: [${6}] echo - Correspondent: [${7}] echo - Tags: [${8}] curl -X POST http://<ha-ip>:8123/api/webhook/paperless_finish_processing -d "{\"filename\": \"${2}\", \"correspondent\": \"${7}\", \"tags\": \"${8}\"}" -H "Content-Type:application/json" echo End post-processing script Home Assistant Automation - alias: 'Job - Paperless Process document' initial_state: true trigger: platform: webhook webhook_id: paperless_start_processing action: - variables: document: "{{ trigger.json.filename }}" - wait_for_trigger: - platform: webhook webhook_id: paperless_finish_processing timeout: '00:10:00' - choose: - conditions: # No trigger happened before timeout expired - condition: template value_template: "{{ wait.trigger == None }}" sequence: - service: notify.telegram data_template: title: 'Job - Paperless Import failed ❌' message: | - Import failed for document "{{ document }}" default: - service: notify.telegram data_template: title: 'Job - Paperless Import successful ✅' message: | - Original name: "{{ document }}" - Import name: {{ wait.trigger.json.filename }} - From: {{ wait.trigger.json.correspondent }} - Tags: {{ wait.trigger.json.tags }} Unfortunately, the automation contains a little issue. When you consume document A and document B at the same time and document B is finished before document A, then the automation notifies success for document A. I had no time yet to look into this, but wanted to share the basic idea any way.
-
Change "[IP]" to the actual IP of your Unraid server or the server that runs the Redis service i.e. 192.168.1.10 or something. Localhost would be inside your docker container causing the "connection refused" error. Let me know if that helps.
-
Do you have Redis installed as container and configured in the paperless-ng template?
-
Backup ist ein Thema bei dem man wirklich sehr viel Zeit verbringen kann. In einer finalen Ausbaustufe empfiehlt es sich der 3-2-1 Backup-Regel zu folgen. Bevor du dir aber aber Dinge wie Offsite-Backup und unterschiedliche Speichermedien Gedanken machst, solltest du ein solides lokales Backup deiner Daten haben. In Unraid hast du verschiedene Arten von Daten wie z.B. Anwendungsdaten, VMs, deine persönlichen Daten, etc. die zu sichern sind und unterschiedliche Eigenschaften aufweisen. Nicht für alle Daten ist immer die gleiche Backup-Lösung geeignet. Beispielsweise machen konventionelle inkrementelle Backups für große VM-Images keinen Sinn, da sich diese häufig in wenigen Bits verändern und dadurch in jedem inkrementellen Backup erneut aufgenommen werden. Der erste Schritt ist zu entscheiden, welche Daten du sichern möchtest und basierend auf dieser Entscheidung eine passende Lösung zu wählen. Für ein inkrementelles Backup deiner persönlichen Daten auf eine USB-Festplatte kann ich dir dieses Skript von @mgutt empfehlen. Dazu benötigst du außerdem das Unassigned Devices (UD) Plugin, um deine externe Festplatte anzuschließen und das User Scripts Plugin, mit dem du das Skript ausführen kannst. Sobald du dein lokales Backup eingerichtet hast und es eine Weile läuft kannst du dich dann im näcsten Schritt über ein Offsite-Backup informieren. Das Offsite-Backup muss nicht immer eine Sicherung zu einem Cloud-Speicher Anbieter sein, sondern kann auch beispielsweise durch eine Festplatte realisiert werden, die du regelmäßig bei einem Freund oder deiner Familie austauscht. Falls du zur Thematik Offsite-Backup Fragen hast, gebe ich dazu gerne auch mehr Informationen. Ich habe schon ein paar Iterationen hinter mir. Bei der externen Festplatte solltest du darauf achten, dass diese einen echten internen SATA-Anschluss hat und nicht direkt auf die Platine gelötet ist. Sollte die Platine nämlich nicht mehr funktionieren, kannst du die Festplatte dann aus dem Gehäuse entfernen und einen regulären SATA-zu-USB Adapter nehmen. Ist das nicht der Fall, hast du keine Möglichkeit mehr auf die Daten deiner Festplatte zuzugreifen. Weitere Anmerkungen zu Backups: - Ein Backup sollte regelmäßig überprüft werden, ob es wiederherstellbar ist (z.B. mind. am World-Backup-Day) - Ein Backup sollte aktuell sein - RAID ist kein Backup, sondern zielt auf Verfügbarkeit ab - Meiner Meinung nach ist das Kopieren (synchronisieren) deiner Daten ohne Versionierung auf ein anderes Medium kein Backup, da fälschlicherweise gelöschte Dateien ebenfalls in deiner Kopie entfernt werden




