




jowi
Members
-
Joined
-
Last visited
Everything posted by jowi
-
Every week a new release. Right. Maybe you guys should go back to actually test builds as beta's etc, fix the bugs and issues, and THEN release them. Crazy idea, i know.
-
I reinstalled the fcp plugin, ran it, and created the diagnostics and took the screenshot. The sickbeard_alt.plg it referres to has been removed years ago...
-
unraid-diagnostics-20250613-1003.zip The yellow ones are weird:
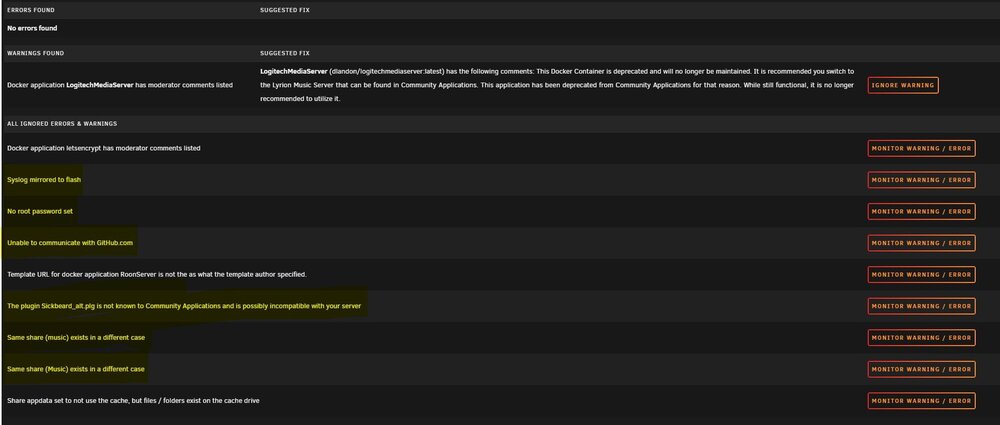
-
I've removed the pugin atm, will re-install it later today or tomorrow and post the diagnostics.
-
-
Is this plugin still relevant? I'm getting al sorts off false errors and warnings: root has no password (it does) syslog is mirrored on the flash drive (it is not, mirroring is OFF and log folder is empty) multiple folder music and Music (there is no 'music' anywhere) deprecated plugins i havent used in years and are nowhere to be found
-
I'm still on 6.12.10 due to the time i needed to convert from reiserfs to xfs disk by disk, took a long time. Couldn't and didn't hurry. But by the looks of it i think i'll stay with it for a while longer.
-
So what is the latest actual stable version? Because a release that has bugfixes every other day doen't give me a lot of trust.
-
Thanks, yeah after some searching and googling i found out that the unassigned devices preclear is the way to go apparently :)
-
I've added a new parity disk a year ago and i swear i used this to preclear it... but if i start the docker now and type 'pre' i get an error : sh: pre: command not found has this docker become invalid? I did update it? what am i missing? And where is the preclear in the UI you are talking about? Oh, i removed so i could re-install, but it can not be found in the apps anymore? Is that correct?
-
That is already there... do i need to change it to my actual ip adress?
-
The docker's context menu doesn't show 'web ui' anymore, just 'console'. Why is that?
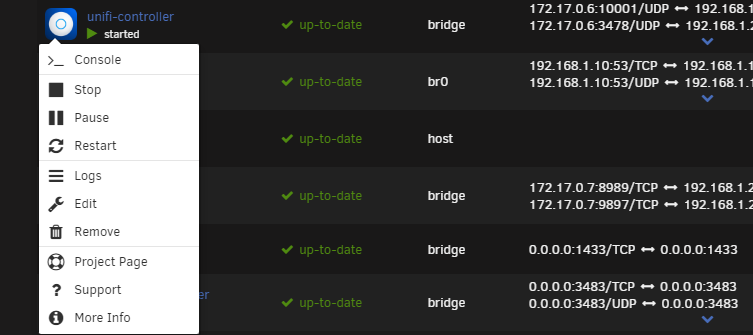
-
The docker menu doesn't show 'web ui' option anymore, only 'console', see picture. You can access the web ui by browsing to the ip:port you configured, but the option is gone?
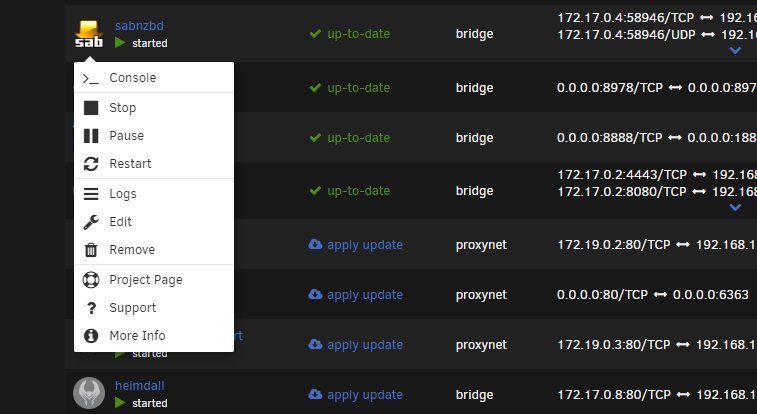
-
Oh, i did not know you could install plugins from CA as well... i assumed CA was all about dockers. I was doing it the hard way from the plugins menu and then try to find a working git repo... which is a pain btw. So i finally by accident found the nerd 'tools' and installed that.
-
The python docker is of no use; i want to run python scripts on unraid itself, not in a docker. I've installed nerd TOOLS (i guess that is the proper nerd plugin for 6.12? because i had to uninstall nerd PACK since it was obsolete). It looks like python is working. Allthough for some reason i can only get python 2 to work, not python 3. Any ideas on why heimdall is complaining? *edit* removed the port 443 from the container and now heimdall is running again.
-
Installing and rebooting was fast and smooth (coming from 6.9). Only issue so far; Heimdall won't start, it throws an execution error/server error. Nothing in the heimdall logs. Also, the update wizard advised me to uninstall the nerd pack and the devpack since they were obsolete, but now i don't have python anymore? The https://github.com/UnRAID/NerdPack/raw/master/plugins/NerdPack.plg repository is gone? How do i get python back? I need that for some custom scripts.
-
I found that a lot of my dockers for some reason have extra params defined: --log-driver none --no-healthcheck If i remove that, the dockser will log again. Sounds about right... if there is no logdriver, you can not log... This is not something i added myself. Where and how is this added? Was this done by an unraid update or some compatibility issue?
-
Found a way to change the root password. The whole parameter thing mentioned above doesnt work for me. Open a putty or ssh connection to unraid, go to the app data folder for mariadb. Edit the custom.conf file, add the entry 'skip-grant-tables' to the [mysqld] block. Save the file & restart the container. Open a console in unraid, enter: mysql enter: use mysql; then: UPDATE user SET `authentication_string` = PASSWORD('myNewPassword') WHERE `User` = 'root'; enter: exit close the console remove the line 'skip-grant-tables' from the custom.conf file, save it. and restart the container Open a new console, now you can enter mysql using: mysql -u root -p enter your password... voila.
-
Nobody? It has been over a year
-
Same here. Lost my pwd and no luck trying the steps provided here. If i add --skip-grant-tables to the parameters, the container is restarted but mariadb itself won't start. Red square. If i DO start it and start the console, the console is immediatly disconnected. I can not do anything.
-
@Aran a bit late, but thanks anyway, this solved my problem
-
Ok, and how do i do that?
-
Nothing? Is there a way i can update node.js myself? In a persistent way?
-
I'm trying to install the "node-red-contrib-virtual-smart-home" palette so i can use Alexa commands in Node-RED, but that package expects node.js version > 18.2.0 to be installed (current in the docker is 16.20.2) Can that be updated in the Node-RED docker?
-
Hi, a few dockers i'm running are showing this error in the log. I noticed that after a reboot this error appeared, other dockers are showing it as well, e.g. nginxproxy, sabnzbd, wordpress, heimdall, mariadb to name a few. How do i fix this?







