




hawihoney
Members
-
Joined
-
Last visited
Everything posted by hawihoney
-
Das verstehe ich nicht. Was will das Tool denn? Guck mal in den Dump? Sieht er inhaltlich ok aus?
-
Probiere Deine Kommandos bitte mal auf der Container Konsole - also ohne den "docker exec mariaDB" Prefix. Ich denke, da siehst Du den einen oder anderen zusätzlichen Hinweis. Nachtrag: Guck mal in den Dump. Sind dort überhaupt CREATE TABLE und INSERT Befehle enthalten?
-
Vieles von UD und GUI ist frei zugänglich. Jede Hilfe ist willkommen https://github.com/unraid/webgui https://github.com/dlandon/unassigned.devices
-
Hab oben die Liste erweitert um meinen Standpunkt klar zu machen. Außerhalb server-grade Hardware nutze ich keine externen Expander, Multiplier, Hubs - oder was auch immer - zur Anbindung von Festplatten. Wenn da nicht Supermicro, LSI/Broadcom o.ä drauf steht kommt mir eine solche Technik nicht ins Haus. Meinen drei untereinander verknüpften BPN-SAS2-EN1 Backplanes hingegen vertraute ich blind. Muss mal bei Gelegenheit den Hersteller der darauf verbauten Chips checken. Genau das hatte ich oben beim damals von mir genutzten HDDRACK5 als Vorteil beschrieben:
-
Für mein damaliges Rack rufen die jetzt einen Fantasiepreis auf. Ich habe damals bei eBay nur einen Bruchteil bezahlt. Ich fand die nackte Anbindung gut - jede Platte im Rack mit eigener Strom- und SATA Anbindung. Das lief mehrere Jahre ohne einen Mucks. Bin kein Freund von Expandern/Multipliern/Hubs in Festplattentechnik außerhalb der Profiliga (Supermicro etc). Für andere Empfehlungen muss die Hardware Fraktion hier ran.
-
Hab oben eSATA Komponenten hinzugefügt.
-
Dafür gibt es eSATA. Ich habe viele Jahre eSATA Gehäuse und eSATA Adapter mit Unraid betrieben. Ich hatte DeLock eSATA Slotblech, SansDigital HDDRack5. Sehen Sch... aus, liefen aber stabil. Da kann man sogar einen 24pin Stromanschluß verwenden.
-
Zufall? Wenn Du das System ernsthaft betreiben willst, dann lass es mit USB. Unraid reagiert sofort wenn eine Anbindung nicht stabil reagiert. Die Information darüber erhält es vom Kernel/Treiber. Mit Deinem Problem wird Dir niemand helfen können und Du spielst mit Deinen Daten Toto/Lotto. Eine Diskussion darüber wäre einfach nur müßig.
-
Und schon bin ich raus. Davon wird ganz klar abgeraten. USB ist nicht stabil genug für die Anbindung an ein RAID. Nur einer von vielen Threads zu diesem Thema:
-
Ach komm jetzt. Das ist einfach nur Quatsch. Das Array in seiner jetzigen Form existiert seit fast 20 Jahren. Ich persönlich habe schon hunderte Platten in Unraid Arrays eingebaut, getauscht, geprüft, etc. Wenn es das gäbe dann würde es in diesem Forum irgendwo zu finden sein. Ich tippe eher auf Dein Rack, dessen Anbindung, etc.
-
Wie ist das Rack angebunden?
-
Hatte ich das nicht geschrieben?
-
Die Fehler sind doch dann erst im letzten Lauf korrigiert worden. Wenn der letzte Check mit Korrektur war, und alle anderen davor ohne Korrektur, dann würde der nächste Lauf keinen Fehler mehr melden.
-
Nur zur Klarstellung: Es sind zwei Platten gleichzeitig während eines Parity-Builds ausgestiegen - Disk6 und Parity2 - wobei letztere gerade aufgebaut wurde? Das ist eine Situation die mir noch nie untergekommen ist. Wie ist denn jetzt der Status (Screenshots!)? Was zeigt denn Unraid an? Theoretisch kann Disk6 mit Parity1 emuliert werden. Da Parity2 keine Kopie von Parity1 ist, sondern separat u.a. aus dem Inhalt von Parity1 berechnet wird, ist m.E. noch nichts passiert. Da ich aber nicht an Zufälle glaube würde ich mal recherchieren ob es nicht Kabel oder sonstige Probleme gibt. Was sagt denn das syslog?
-
Sorry, nein. Im Moment nutze ich weder Nextcloud noch eine Alternative. Hatte irgendwann die Nase voll von Nextcloud und dem ewigen Gefrickel. Als extrem ungeduliger Mensch ziehe ich schnell den Stecker ohne über den Rest nachzudenken. Da ich alle Dokumente, Bilder, etc. schon immer sauber organsiert und benannt hatte, klappt das im Moment ganz gut über das Dateisystem und VPN.
-
Ich habe das immer mit den Bordwerkzeugen gemacht. Je nach Version Deiner MariaDB Installation musst Du mit "mysqldump" oder "mariadb-dump" exportieren - es hat bei den Namen der Tools einen Wechsel gegeben. Alle Parameter für den Dump findest Du in u.a. aufgeführten Link. ### docker stop alle Container die auf MariaDB zugreifen docker stop <Name des MariaDB Containers> ### Deprecated docker exec -i mysqldump --user=<Benutzername> --password=<Passwort> <Datenbankname> > <Wohin mit dem Dump?> docker exec -i mariadb-dump --user=<Benutzername> --password=<Passwort> <Datenbankname> > <Wohin mit dem Dump?> docker start <Name des MariaDB Containers> ### docker start alle Container die auf MariaDB zugreifen https://mariadb.com/kb/en/mariadb-dump/ In die neue MariaDB musst Du dann aber auf jeden Fall mit "mariadb" importieren: ### docker stop alle Container die auf MariaDB zugreifen docker stop <Name des MariaDB Containers> ### Deprecated docker exec -i mysql --user=<Benutzername> --password=<Passwort> <Datenbankname> < <Wo liegt der Dump?> docker exec -i mariadb --user=<Benutzername> --password=<Passwort> <Datenbankname> < <Wo liegt der Dump?> docker start <Name des MariaDB Containers> ### docker start alle Container die auf MariaDB zugreifen https://mariadb.com/kb/en/mariadb-command-line-client/ Ich nutze Nextcloud/MySQL/MariaDB seit kurzem nicht mehr, aber so habe ich es immer gemacht.
-
Winzinge Ergänzung zu @alturismo : Und die in den Plex Container gemappten Disks/Shares mit dem Content als readonly mappen. Dann bist Du auf der sicheren Seite:
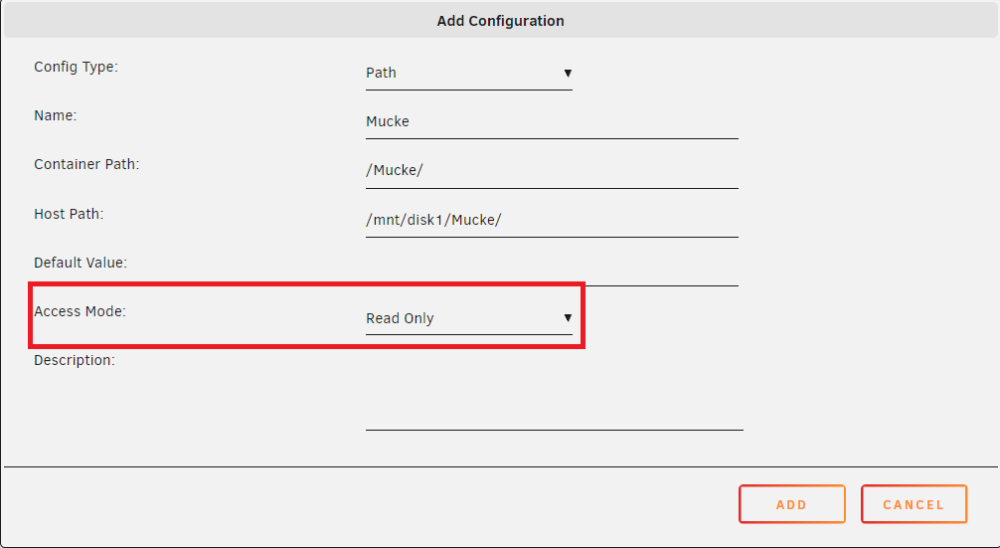
-
Ich würde das Mounten über rclone empfehlen. Das Unassigned Devices Plugin stellt extra für eigene Anbindungen den Ordner /mnt/addons/ bereit. Das Einrichten ist relativ einfach: https://rclone.org/webdav/ https://rclone.org/commands/rclone_mount/ Ich kann mir nicht vorstellen, dass WebDAV jemals in Base Unraid integriert wird - passen würde es thematisch eher zu UD. Aber auch von UD würde ich einen Verweis auf rclone erwarten. Guck Dir mal die unfassbar lange Liste an unterstützten Services in rclone an. Da ist für jeden etwas dabei. Mit dem un-get Tool von @ich777 kannst Du rclone installieren.
-
^^^ Genau das ist meine Perspektive mit Unraid. Ich werde wohl auf nicht absehbare Zeit auf 6.11.5 bleiben.
-
Ich würde es machen. Auf fehlende Schreibzugriffe zu vertrauen wäre mir zu viel Toto/Lotto. Nur zur Erläuterung: In RAID Systemen haben die eigentlichen Daten Vorrang vor den Paritäts-Daten. Im Unraid Array bedeutet das "Die Datenplatten haben immer Recht". Wenn bei einem Crash zufällig die Daten-Platte aktualisiert wurde und die Paritäts-Platte noch nicht, dann besteht das Risiko, dass andere, bisher unbeteiligte, Platten beim nächsten Sync neue Fehler erhalten. Beispiel: Nehmen wir einmal an, ein Bit wurde noch nicht in der Parity-Platte vermerkt. Eine andere Datenplatte raucht jetzt vor dem notwendigen Parity-Sync ab. Du steckst eine Ersatzplatte rein und schwupps existiert ein 50% Risiko (even/uneven Parity), dass auf dieser bisher unbeteiligten Daten-Platte an der Stelle ein Fehler erzeugt wird, der vorher noch nicht da war. Und diese Platte kann das dann still und heimlich weitergeben. Der Spuk endet erst beim nächsten Parity-Sync. Dann hat aber die Parity-Disk diesen neuen Fehler bereits übernommen. Ab diesem Zeitpunkt werden keine neuen Fehler erzeugt, aber den bereits erzeugten Fehler merkst Du vielleicht erst in Jahren auf der unbeteiligten Platte. Das Risiko ist minimal aber ich lerne täglich wie unterschiedlich sorglos manche mit ihren Daten umgehen. Man sollte das Risiko zumindest kennen. Lange Rede kurzer Sinn: Mit einem Parity Check bist Du auf der sicheren Seite.
-
Du verstehst es einfach nicht, aber egal ... ... ich bezeichne das als mit fremden Federn schmücken - aber auch egal - gibt so ein nettes Feature hier in der Forums-Software.
-
Das sind zwei unterschiedliche Mechanismen. RAID (auch das parität-gestützte Unraid Array ist ein RAID-System) bietet Redundanz und somit Verfügbarkeit. RAID hilft beim Ausfall kompletter Platten, Backup sichert einzelne Ordner und Dateien. Wenn Du Dir eine Datei aus Versehen löschst, dann nutzt RAID nix. Dann brauchst Du ein Backup mit dieser Datei. Wenn Dir eine Platte ausfällt, dann bist Du ohne RAID erstmal offline. Mit RAID kannst Du trotz der fehlenden Platte weiter arbeiten. BTW, warum markierst Du eine Zusammenfassung der Hilfestellung anderer immer als Deine Solution. Nach meinem Verständnis "ehrt" man die hilfe-gewährenden mit der Solution und erhöht damit deren Reputation. Für die Freiwilligen Helfer hier - und das sind wir alle - ist das der Lohn des Aufwands und der von der Freizeit abgeknapsten Zeit um anderen unentgeltlich zu helfen. Wähle den Helfer, der Dir am ehesten zu Deinem Problem geholfen hat, und "spendiere" ihm die Solution. Wer über das selbe Problem wie Du stolpert findet dann auch seine Lösung in der Gesamtheit des jeweiligen Problem-Threads. Nur meine 0.02 Cent.
-
Arg. Sorry, my fault. Switching between boards and lost the language requirement within these. Thanks for this explanation.
-
Kurze Frage zu Deinem NZBGet Container. Nur so aus Interesse: Gibt es einen bestimmten Grund warum Du das appdata Verzeichnis im Container auf /nzbget mappst statt auf das sonst übliche /config? Vielen Dank.
-
Auch das hatte ich oben geschrieben - sogar mit Link zur Erläuterung.

