




hawihoney
Members
-
Joined
-
Last visited
Everything posted by hawihoney
-
Falsch. Die Parity wird on-the-fly für jeden geänderten Block auf Disk6 beschrieben. Auf Deinem Screenshot kannst Du sehen was geschrieben wird. Damit werden jetzt alle (!!!) Platten genutzt und nicht mehr nur Disk2, Disk6 sowie Parity --> benötigt mehr Strom. Für mich ist die Situation an Hand Deines Screenshots klar. Dynamix FileManager nutzt rsync zum Verschieben der Daten. Der Match von 72 MB/s auf den drei betroffenen Platten zeigt, dass nix Anderes läuft. Es gäbe sonst ein Lese- oder Schreibunterschied bei den drei Platten. Rechne einfach mal an Hand Deiner Daten nach. Welches Volumen in TB verschiebst Du?
-
Aus Deinem Screenshot wird das ersichtlich: Es wird von Disk2 gelesen und auf Disk6 geschrieben. Offensichtlich hast Du eine einzelne Parity in Betrieb - diese wird ebenfalls beschrieben. Die Schreibperformance von über 70 MB/s ist bei mechanischen Festplatten absolut in Ordnung da das Parity-geschützte Array pro Schreibvorgang vier Operationen ausführt (siehe unten). Das entspricht über 200 MB/s was für mechanische Festplatten sehr gut ist. Ich gehe davon aus, dass Du sehr, sehr viele Daten verschiebst ... Nun teile die zu verschiebende Datenmenge durch 70 MB/s und Du kennst die dafür notwendige Zeit - vorausgesetzt Dein System ist nicht noch mit etwas Anderem beschäftigt. Wenn ich mich nicht verrechnet habe, dann kannst Du mit Deinem Array grob in vier Stunden 1 TB schreiben, bei 2 TB macht das acht Stunden, ... https://wiki.unraid.net/Manual/Storage_Management#Array_Write_Modes
-
Nimm den systemnahen Dynamix File Manager und arbeite im Browser.
-
1.) 5400er wären lange nicht so "zappig" wie 7200er 2.) USB? Ganz schlechte Idee. Ist hier schon dutzende Male thematisiert worden. USB Verbindungen sind definitiv nicht für RAID Systeme wie das Unraid Array gedacht. Nimm zu einfachen externen Gehäusen entweder eSATA oder lebe mit evtl. auftretenden Problemen.
-
Ich kenne das Skript von @mgutt nicht in Gänze - habe gerade nur mal grob drüber geschaut. Stoppt es die VMs vor dem Backup? Ich meine dass das nicht der Fall ist. Wenn nein, dann kann bzw. wird das zum Problem werden. Du brauchst a.) Snapshots auf einem Snapshot-fähigen FS oder b.) ein Backup Programm welches vorab die VMs stoppt und nach dem Backup wieder startet. Man könnte es auch einfach selber in User Scripts packen (Stichworte: virsh sowie rsync Kommandos) aber das erfordert rudimentäre Programmierkenntnisse.
-
-
Beim Anbieter den Umstand unter Zusendung von Details (Anmelde Bestätigung, etc. wenn vorhanden) beschreiben und Account löschen lassen. Alles andere löst nicht das ursächliche Problem.
-
Die einfachste Variante wäre über das Dynamix FileManager Plugin in der Unraid Oberfläche im Browser. Ggfs. musst Du die yaml Extension für den FileManager aktivieren in /boot/config/editor.cfg. Letzteres kannst Du ebenfalls im FileManager editieren.
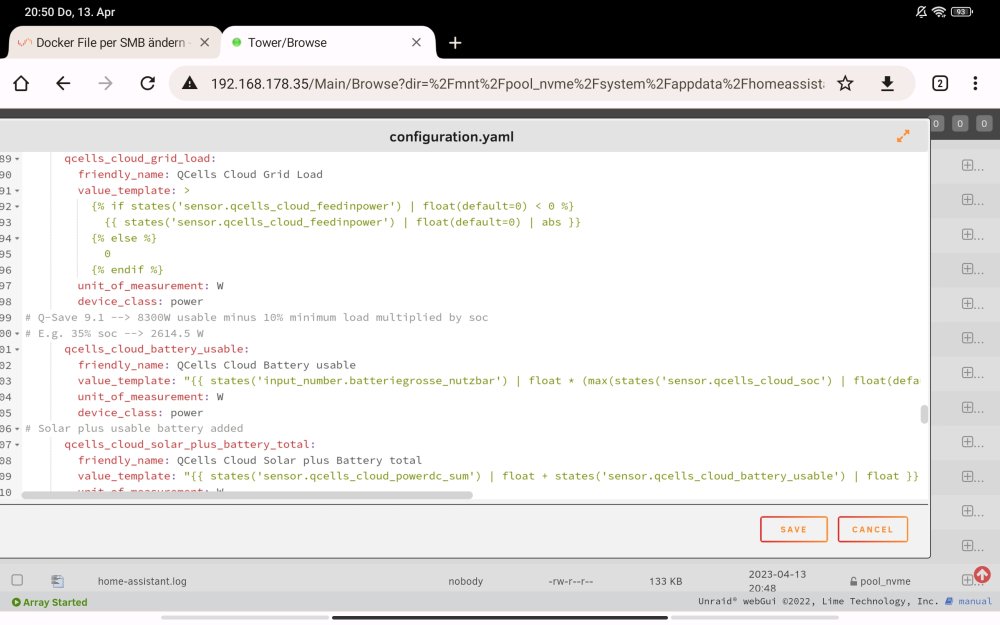
-
Das ist Quatsch. Ich hatte @ich777 allgemein geantwortet (Single Disk ZFS|XFS im Array). Du hast das gequotet und mein Argument für eine Gegenrede verwendet. Ich habe das richtig gestellt und schon drehst Du es wieder um. Geht es hier ums letzte Wort haben müssen? Korrekt war es jedenfalls nicht. Lies im Zweifel noch mal.
-
Kein Thema. Ich hatte manchmal Probleme mit fremden DNS-Servern und Telekom. Ich kann das nicht erklären aber es scheint als gäbe es manchmal Auflösungs-Probleme. Ich rotiere in solchen Fällen zwischen Telekom, Google, Cloudflare und zurück und dann klappt es.
-
Gerade ein "Check for updates" ausgeführt. Für "Home Assistant" wurde ein Update angezeigt. Update erfolgreich ausgeführt. Also hier läuft es. Ist bei Dir noch Software (AdBlocker, Proxy, etc) zwischen Unraid und dem Router?
-
-
Das Du das weißt war mir klar - ich wollte das halt nur mal erwähnt haben. Ein Dataset ist halt irgendwie ein Zwitter. Wird spannend zu sehen wie Unraid das im übernächsten Release in die GUI vollständig integrieren will. Für mich persönlich als Benutzer eines Standard Unraid sind einige Dinge ganz klar. Das Array ist und bleibt für mich die Ablage für die kalten Daten (wenig Bewegung, Platten schlafen ...). Ob bei den individuellen Platten des Arrays XFS oder ZFS zum Einsatz kommt ist mir persönlich Latte. XFS stellst sich mir rock-solid dar. Warum also ändern. ZFS wird hier nur den - in meinen Augen - Totalausfall BTRFS ersetzen. Einen schnellen NVMe RAIDZ1 Pool für die klassischen appdata/domains/etc. Dinge und einen neuen NVMe RAIDZ1 Pool für heiße Daten (viel Bewegung, Platten always-on).
-
-
Ein Versuch war es wert. Hätte ja sein können ... Im Ernst: Du bist lange genug in diesem Forum dabei, und hast auch an einigen Threads teilgenommen, um zu wissen, dass eine solche pauschale, inhaltlich leere Anfrage niemand beantworten kann. Jeder der Dir helfen will muss Dir, wie @DataCollector, vorab ein dutzend Fragen stellen. Diese Details gehören in Deine Anfrage. Das ist als würdest Du in eine Buchhandlung gehen und sagst "Ich will ein Buch". Also: Wie ist diese Anwendung installiert und wie hast Du ihr den Zugriff auf die fehlenden Daten ermöglicht.
-
Hast Du schon unter den Tisch geschaut?
-
Wirst Du wohl mit apt-get installieren müssen.
-
https://letmegooglethat.com/?q=resize+partition+debian StackExchange? growpart? Ohne Gewähr!
-
Noch eine zusätzliche Anmerkung hierzu da es oft zu Missverständnissen führt: Selbst bei einer "Precleared" Festplatte wird am Ende der Punkt a.) - das clearen - im neuen, bisher ungenutzten Bereich der Festplatte ausgeführt. Deshalb bringt das Preclearen nur eine Zeitersparnis im Array beim Hinzufügen von zusätzlichen Platten und nicht beim Ersetzen von Festplatten. Denn es ist eine beliebte Frage beim Ersetzen durch eine größere Platte "Wieso wird denn nach dem Rebuild über Stunden nur die Ersatzplatte (ggfs. zusätzlich Parity) beschrieben?" Das sind die Nullen ...
-
Genau so funktioniert das Unraid Array seit Anfang an - egal ob mit XFS, BTRFS, ReiserFS oder ZFS. Am Ende des Rebuilds wird a.) der Rest der größeren Platte mit Nullen beschrieben und b.) die Partition in diesen Bereich erweitert. Diese zusätzlichen Anpassungen wandern dann auch gleich in die Parity so dass diese 20 TB Platte sofort wieder gegen eine andere 20 TB ausgetauscht werden könnte. Ein kleiner Ausflug ins Jahr 2008 in dem ich meine erste Unraid Lizenz erwarb https://web.archive.org/web/20080803131341/http://lime-technology.com/?page_id=47#toc-replace-a-single-disk-with-a-bigger-one
-
Kann man mit Unraid Bordmitteln ändern. Danach muss die Linux Partition innerhalb der vdisk manuell angepasst werden: Das sind dann aber eher Linux Bordmittel und hat nix mehr mit Unraid zu tun.
-
After the latest update SQLiteBrowser does no longer work here. I receive an empty blue screen - nothing else. I did restart the container, I did empty my browser cache, nothing helps. What can I do?
-
Ist doch auch zu 99,99% die gleich Vorgehensweise. Zum Abschluss wird bei Clear Disk zusätzlich die Unraid Signatur gesetzt und eine leere Partition angelegt. Das steht auch zwei Posts über diesem ... Die "Reported_Uncorrect" würde ich auf jeden Fall beobachten. Wenn die weiter steigen würde ich nervös werden. Alle anderen Indikatoren sind IMHO nicht dramatisch.
-
Ah, I see. The label "Search string" is misleading. It should be named e.g. "Search pattern" or even something that's more correct IMHO. The "Search string" "imdb" does not find anything.
-
Das will der OP meinem Verständnis nach aber nicht. Eine Warteschlange - einen Stapel - abzuarbeiten können MKVToolNix, Handbrake, etc. Ihm geht es aber auch um das automatisierte Einlesen eines kompletten Ordners um alle Dateien in dem Ordner zu verarbeiten. Er will - um bei der Analogie zu bleiben - das der Stapel maschinell gefüllt wird und das der Stapel dann auch noch automatisch abgearbeitet werden soll. Das geht mit einem kleinen Skript wie gesagt bei MakeMKV, MKVToolNix und FFMPEG. Ich persönlich würde MakeMKV verwenden, da ich hier die volle Kontrolle über die Auswahl der Streams an Hand der oben gezeigten Selection-Rule hätte. Wenn die Stream Anordnung in den Input Dateien nämlich abweicht, dann stehst Du ohne intelligente Selection-Rule dumm da. Da kommst Du z.B. mit Stream-Nummern nicht weit. Meine Selection-Rule z.B. selektiert den hochwertigen DE Audio-Stream und schmeiß von diesem auch noch den Core raus. Das alles geht aber nur in einem Skript.




