





killeriq
Members
-
Joined
-
Last visited
Everything posted by killeriq
-
I did set "28.0.10-previous" , but then it didnt want to upgrade to 28.0.11 from WebUI. So i went via commands and now i'm stuck here: No such Log in Nextcloud folder, will check also inside docker
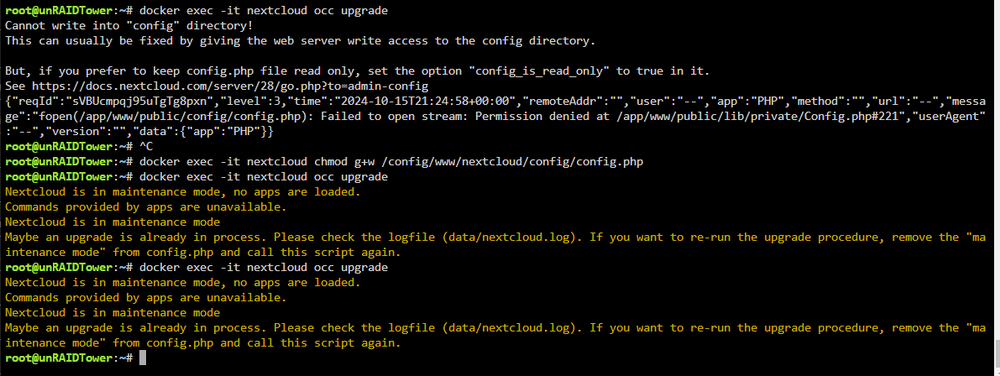
-
My curiosity was Faster and i've set 28.0.4 as it mentioned in the Log Now it loads till WebUI. So what is the correct process to upgrade with NC Docker (unraid) and the Nextcloud server it self?
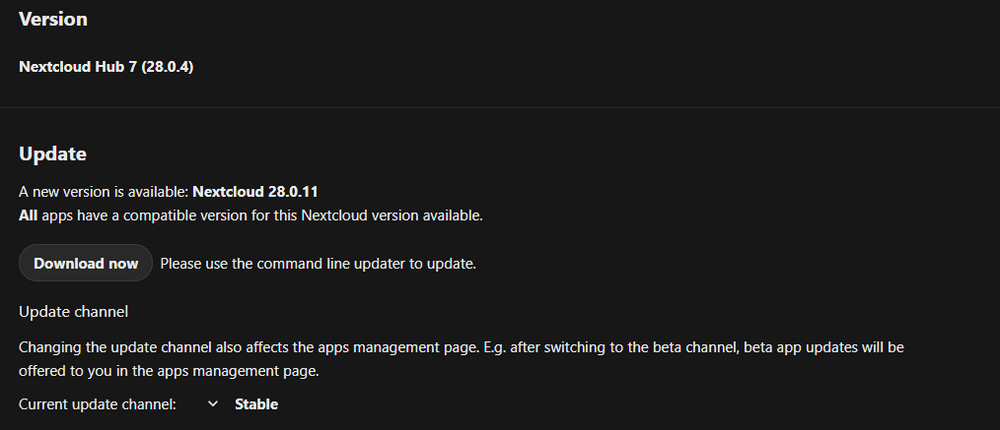
-
I found your post, I assume this might do the trick...but seems like Apps backup isn't backing up for some time, probably something changed during upgrades. Or where i could double check please?
-
I found it in Previous Apps (didnt knew it exist ) and did re-install, now I see Docker again, but it wont start WebUI. It gives 404 Seems like i had docker on this version "lscr.io/linuxserver/nextcloud:25.0.2" Here is the output from NC Docker Log

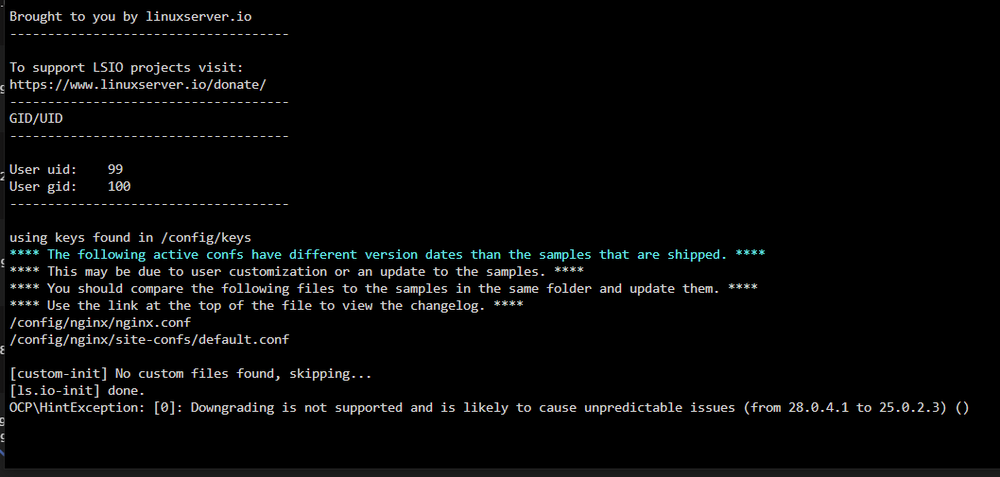
-
anyone?
-
Hi, I found out few days ago that my Docker container was set to "lscr.io/linuxserver/nextcloud:25.0.2" probably due to History reasons and issue with the PHP So i thought lets set it to "latest" , but then i got error about that version is on 30 and u need to be on 28 (or something in this matter) So i set the mentioned docker version to the version it asked "lscr.io/linuxserver/nextcloud:28.0.2" , but after doing it Nextcloud docker is gone from Docker Containers menu and i have no clue how to get it back. Could you or someone please suggest what can I do about it? Thanks!
-
Sep 15 16:10:00 unRAIDTower vnstatd[4586]: Detected bandwidth limit for "br0" changed from 10 Mbit to 1000 Mbit. Got the same today...any progress with it?
-
I've been using the OLD "hiveos-20190114-1121.img" as this was the last one where Virtio Network was working, all releases afterwards werent working anymore. Always network connection issue Today I found solution with "rtl8139" which i didnt even realize is there and ist working with latest image! hiveos-0.6-227-stable@240530 Great and Thanks a lot! Only issue what I'm facing - Card seem like to have some mining limit vs normal HW In FIROPOW 3060ti in VM i get max ~26MH In HW i get around 30-32 on same card, could find where is the problem

-
Hmm so seems like only way at the moment is to time to time disable VPN and proceed with updates, then re-enable VPN Definitely didn't face such issues few months back, but seems like services are blacklisting VPN's IPs due to some spam, ddos attacks etc... Or option B - put only few Dockers on VPN, but no clue if that is possible as they have only single unRAID IP, so perhaps via PORTs only
-
is there some list to that fact? like which services are being blocked? I use AzireVPN. Also i did seen time to time some "blocking" notice on some simple forum that "this IP is blocked due to spam bla bla..."
-
Tried it and also not able to install. Wrote to my VPN provider, seems like there is something on their end. No clue whats wrong all is working except this Docker connection. Tried once again to disable VPN on unRAID and after update check it came with actual updates Strange and Thanks for pointing me right direction.
-
After hitting "check for updates" was taking more then 10m+ and still not finished. So i hit refresh browser tab and same issue as previously Only those 2 dockers are somehow acting/checking state

-
Hello, I've realized that last few weeks/months i'm not able to update Dockers. Most of the time i've seen update details like uptodate, apply update only for those 2 dockers: Nextcloud Transmission Rest of all dockers have "not available". After update from 6.12.9 to 6.12.10 and restart , i can see more updates, but still most of them "not available" No clue why is it happening, even if I put server out of VPN it act same strangely with updates for dockers. I was in opinion that the Docker update server is the same, so the update check should either work for all of them of for none. In the past years I never faced such issue. In 6.12.9 update there is this note, so i thought Finally , but no real improvement only after 6.12.10 i'm able to see more updates. Docker Ignore empty paths in config file when adding or updating containers Resolve certain issues updating containers Fix notifications when container updates are available --- Any clue what else i can try? Thanks

-
thanks for point out possible issues, seems is some port issue on VPN, some docker are loading/checking updates and others dont
-
Hi, should it fix also the issue that im not able to see available updates as before? Now (not sure from which version) show on 90% dockers " not available" Thanks

-
@allinvain Great tip! I was wondering why after my Nextcloud update like month ago, i didnt had any new photos uploaded. Wanted to go to WebUI and got that error: This version of Nextcloud is not compatible with PHP>=8.2. You are currently running 8.2.6. Luckily your Tip fixed it... Nextcloud is each time problem, been using it many years, but this the same problems mostly with updates. Finally started and new version so let's update and again this: Every F*king time, need to update in multiple Browsers Chrome / Edge , re-run X times to finish. Then it fails with this message " to “login you need to provide the unhashed value of “updater.secret” in your config file.”" Which doesnt work for me... 1. Stop docker Only way is to open/edit - www\nextcloud\config\config.php 'updater.release.channel' => 'stable', 'maintenance' => true, TO 'updater.release.channel' => 'stable', 'maintenance' => false, 2. Start docker , go to UI and continue
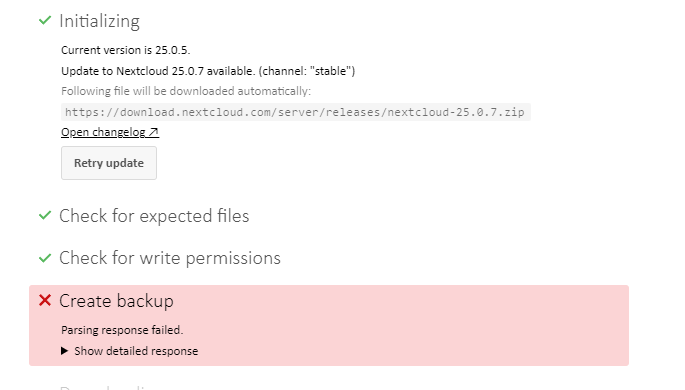

-
Guys please how to fix issue: I download some torrent but when i want to create manualy some folder in there, i CAN'T it say issue with permissions So i need to go TOOLS - NEW PERMISSIONS - pick the folder and hit START It runs the permission and its fine Processing: /mnt/user/Downloads ... chmod -R u-x,go-rwx,go+u,ugo+X /mnt/user/Down ... chown -R nobody:users /mnt/user/Down ... sync Completed, elapsed time: 00:00:04 How to fix it ? that i dont have to do it each time manually? It was fine in past, so no clue what changed... thanks
-
Hi guys, 2y back i was considering to use this App for my ONVIF camera system...there were issue with "live view" wasnt working good and also there was none Mobile App for Android to view whats going on at home from outside. Therefor i didnt used it further.... How is it today? Is it real replacement on HW NVR box? Thanks
-
Guys seems like i got it working, not sure which setting helped in the end. Was watching new video on Win11 install and he did upgrade the VirtIO there, so i tried 1. Download latest VirtIO driver 2. Then i did: - Machine: on latest 7.1 (before 7.0) - VirtIO Drivers ISO: latest you just downloaded - VM Console WS Port: in here i had before "-1", maybe due to fact i did edit TXT as this menu in UI wasnt present. On other VMs with Linux were values like 5701 and up+ Try it and let know if is working now
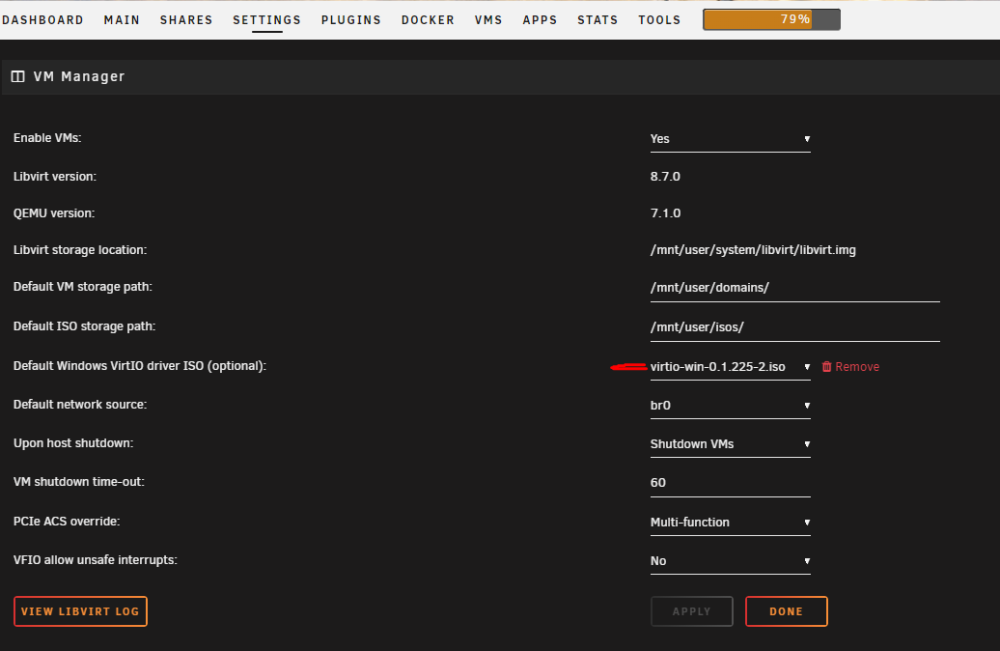
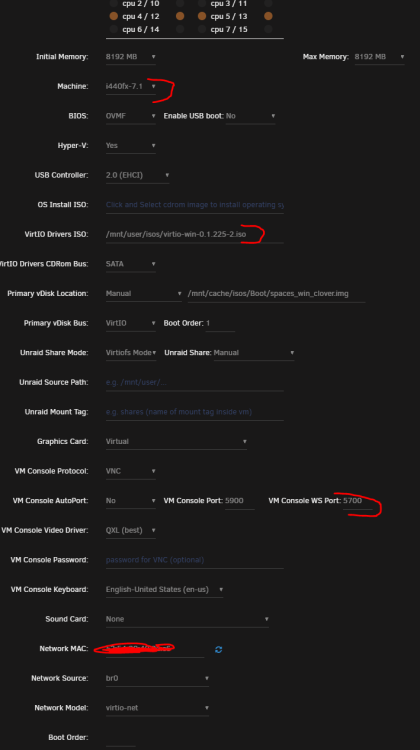
-
Having also similar issue. After some upgrade, not sure which one (currently on Version: 6.11.5 ) i'm not able to boot into my VM Win10 via VNC, just black screen. I have this VM as testing VM so i use it just few times a month or two. Is on M2 SSD via "spaces win clover" per this guide Even i try to take Unraid OS USB out and boot directly from M2 SSD, Windows loads fine...so definitely some issue with Unraid, but not a clue where Other VMs like ubuntu, debian shows just fine via VNC guys any help please? @SpaceInvaderOne @limetech Thanks unraidtower-diagnostics-20221223-1349.zip
-
https://github.com/soerentsch/docker-serviio There is a new Docker of Serviio (search in apps), as this former one is not beeing updated anymore But still from some reason Serviio (this former docker) and even the New one is not promoting, nothing visible in the network as before. No clue if is issue with the product it self or some setting in Docker. Haven't found it... I believe last version which was working for me was around 1.9 or so --- I did try other options "Universal-Media-Server" - Not promoting Gerbera - works right away after docker start...searches for tracks in folder i picked and promoting on network. --- If someone could help with Serviio I would he glad
-
yesterday i tried this docker as Serviio is not promoting (no clue why). This one started to promote right away...bit different UI vs Serviio but i guess it will do the trick as i get used to it. thanks
-
Problem was that it was adding default values into *.json as WHITELIST etc which makes GUI client unable to connect. Now is working for some time already, but seems like something was/is messed up in release
-
will try to wipe transmission docker and set it up again from scratch (but i did that already). No clue what else to try
-
I did there is = where is randomly changing the "settings.json" Problem is that it works and seems either after upgrade or OS reboot it get some of the "default" docker settings , as on fresh install. No clue why. No such issue with other docker

















