casperse
Members
-
Joined
-
Last visited
Everything posted by casperse
-
Ok so I got the SSH working to the redpill image: So I need to create the user_config.json file here ? - before installing any DSM? https://github.com/pocopico/tinycore-redpill/blob/main/user_config.json

-
Does anyone know how to set the serial in the configuration? (I don't want to generate one, I want to use the serial I have for my old Synology NAS, replacing the one I have)
-
Seem to be some access problem?
-
Hi All After the last update my second cache drive is showing up as a shared drive? This "share" contains all my cache appdata - so how can I remove it?
-
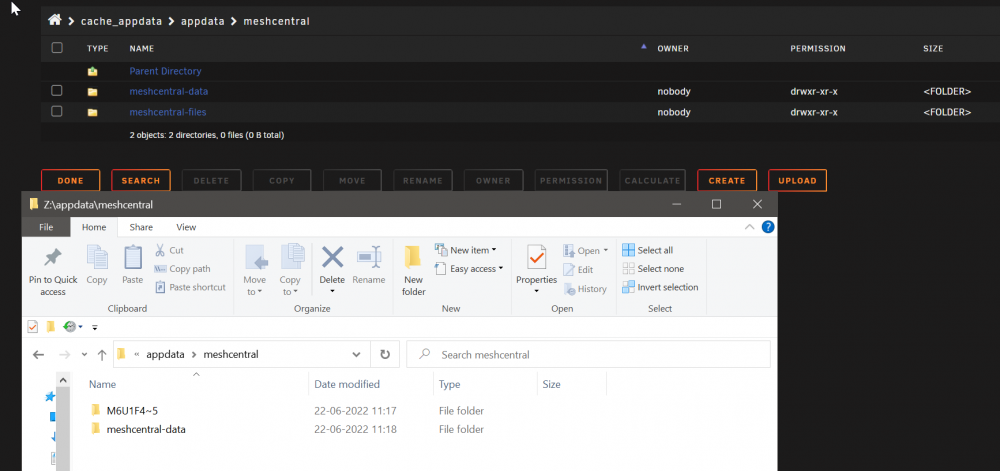
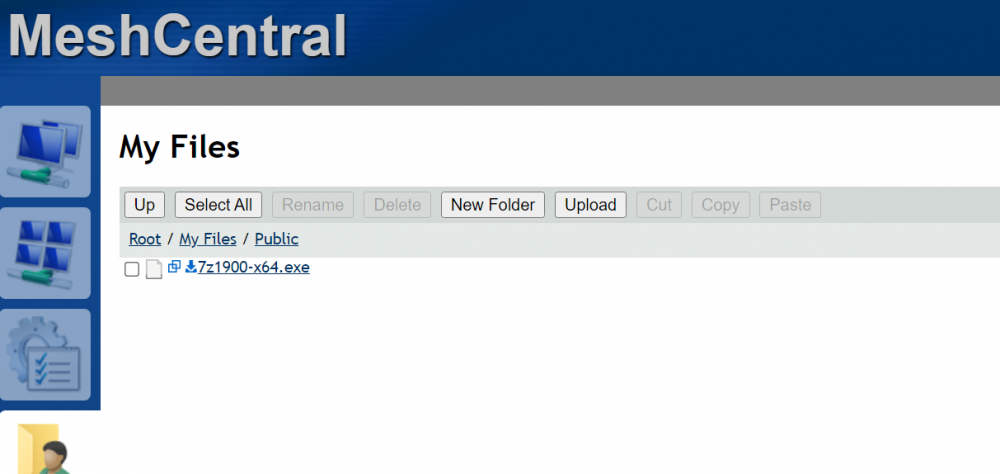
I tried the community app but I am having some problems? Uploading files does not get uploaded to the files folder? Also windows share shows the folder strange? "M6U1...." Also changing the port number breaks the "open webui" on the Unraid docker menu (But thats a smaller problem)
-
Thanks for the feedback! I have a Xeon E2100G and even this setup is causing problems during passthrough of the NVidia cards 😞 I am starting to consider a setup like yours with plenty of possibilities for future expansion! But NOT running Unraid as a bare-metal hypervisor (Like I always have done!) But instead run Proxmox as my hypervisor and then having all the VM's running here! (Passthrough should be much easier) And Unraid running as a virtual setup on Proxmox with HW passthrough of all the drives That way I could re-boot Unraid and keep all my VM running + the backup of VM's and snapshots would be built into Proxmox
-
Just want to hear if you got the ROMED8-2T motherboard stable running VM's? Are you happy with this MB & CPU? - I am asking because I am in the middle of ordering the same MB as an upgrade to my stable Xeon MB
-
"Reproduceable problem" First let me say I don't know if this is specific to this release? (VM for Windows 11 is new feature) So please move it if you feel it shouldn't be here! I have a problem where if I try to start my new VM windows 11 setup Then the UI freezes and I cannot login to UNRAID anymore (From anywher!) BUT all my existing Dockers and VM's are running 100% just fine! so RAM/CPU must have enough resources available! Even my other VM and AMP gaming server runs perfect! My only option is to SSH in to Unraid and do a: powerdown -r And Fortunately I didn't have auto start on this VM 🙂 And afterwards I can login again I can reproduce the problem easily, I have tried removing cores & adding less RAM? So if you have any special SSH commands to get the diagnostic file or other logs I should do to trouble shoot this then let me know! MY XML from the Windows 11 VM (If I have never seen a VM totally stop the entire access to the UI before? not even the login works)
-
Yes I get this no - no further problems 🙂
-
I have made the changes and I havnet seen any memory warning for some time, but got one today (Havent found any Emby reference) Is this just one off these things where you have to upgrade your memory 😞 Attached new Diag file diagnostics-20220508-1427.zip

-
I was on RC4 I am now on RC5 Do you need anymore info or additional running commands from me? :--)
-
So sorry My BAD I got a little freaked out and did a reboot - hoping all my data would reappear again and it did.... I am monitoring my new cache very closely. I promise to send a new Diag if it happens again
-
Hi All I had problems with a blinking cursor on the stable release of Unraid 6.9 but after upgrading to 6.10.rc4 it worked again! Now I have upgraded to Unraid 6.10rc5 and I get the dreaded cursor again 😞 No Firefox UI I have tested this on a 1080P monitor with a HDMI cable And another 4K monitor and another cable and result is the same this is what I see on both screen: Hard to explain I made a video: (Sorry for the shaken picture) Diag log attached below UI-diagnostics-20220430-1151.zip
-
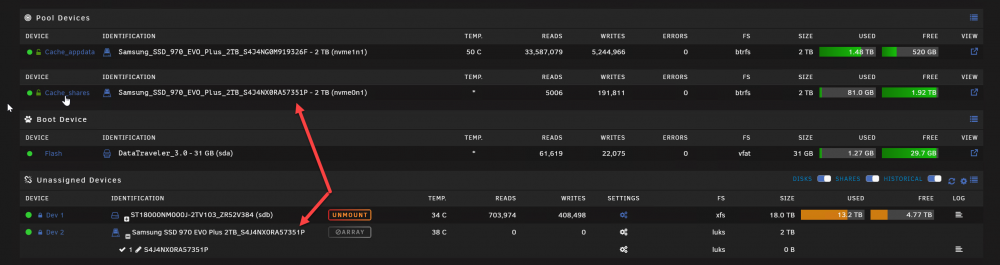
THANKS again! - I decided to change every path to get the better performance and everything worked great! Also updated plugins to do appdata backup etc.... so everything was running just fine and I wanted to check files on my new cache drive But this time it was EMPTY! and in my main view I had this: (This was not present when running the new cache drive at start?) Somehow my new cache drive was in both places? Afraid that I had now lost all my cache files I did a reboot and everything is back again? I upgraded to rc5 yesterday, not sure this is an error or something else?
-
Thanks trurl I found a post saying I should reboot again, but that didnt help. I then removed the new cache drive it was empty anyway, and then I started without the new cache and stopped and added it again and now its active! But I have a question , very afraid to mess up my existing Appdata on my existing cache drive! If I rename my existing cache to a new name cache_appdata and then start the Docker service! Whar will happen to all the paths that are assigned to the currunt path So its actually best and recommended to just use the default /mnt/user/appdata and set prefer Cache! And NOT like me and others to have set it manually on each docker to use the /mnt/cache/appdata - because when adding pools and renaming you have to change the paths on all dockers!
-
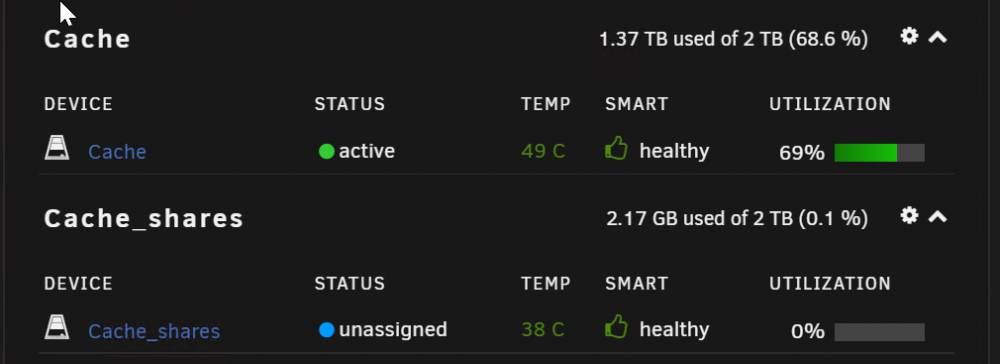
This is very strange after adding the new cache drive I have it listed as un-assigned? its the Cache_shares
-
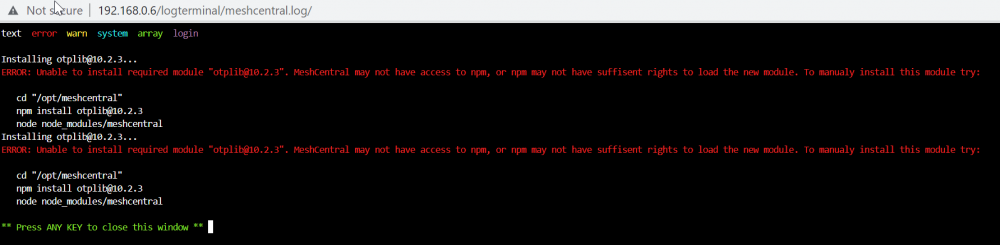
Argh no its a black screen right after the last load on screen of the nvidia loading So somehow the login promt and the local UI resolution does not like my 4K monitor? I could see that it changed resolution while loading on the screen 1080P -> 4K (Very small text) -> back to 1080P and at the login promt black screen? Is there any setting to get this working on a 4K screen? I am now pretty sure that is the problem Diagnostic attached below diagnostics-20220426-1930.zip
-
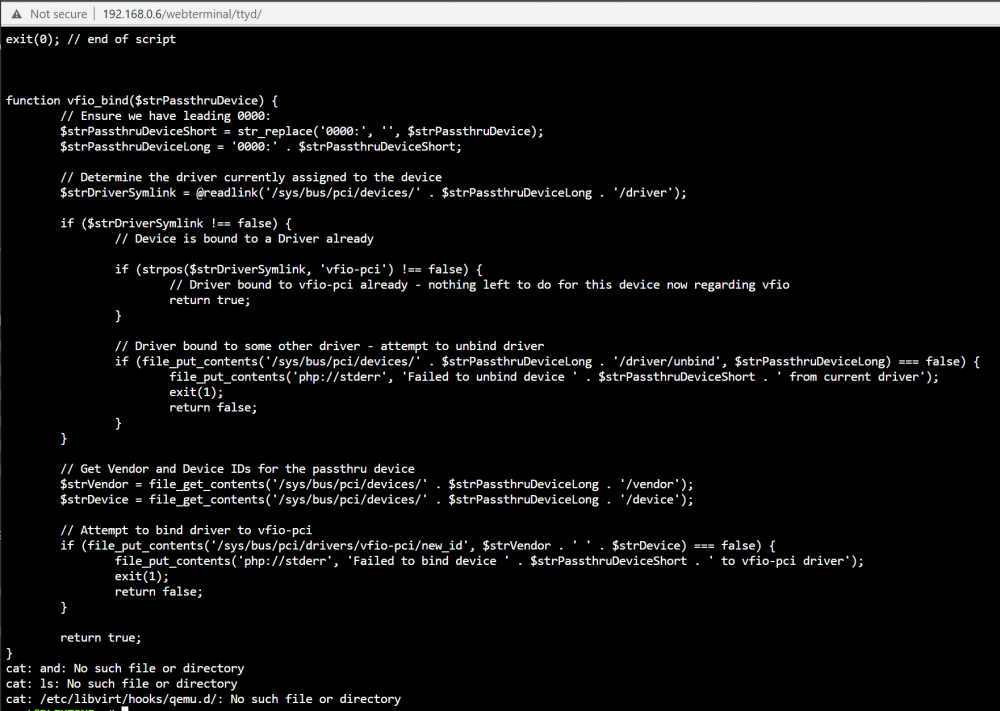
Yes of course, anything to help #!/usr/bin/env php <?php #begin USB_MANAGER if ($argv[2] == 'prepare' || $argv[2] == 'stopped'){ shell_exec("/usr/local/emhttp/plugins/usb_manager/scripts/rc.usb_manager vm_action '{$argv[1]}' {$argv[2]} {$argv[3]} {$argv[4]} >/dev/null 2>&1 & disown") ; } #end USB_MANAGER if (!isset($argv[2]) || $argv[2] != 'start') { exit(0); } $strXML = file_get_contents('php://stdin'); $doc = new DOMDocument(); $doc->loadXML($strXML); $xpath = new DOMXpath($doc); $args = $xpath->evaluate("//domain/*[name()='qemu:commandline']/*[name()='qemu:arg']/@value"); for ($i = 0; $i < $args->length; $i++){ $arg_list = explode(',', $args->item($i)->nodeValue); if ($arg_list[0] !== 'vfio-pci') { continue; } foreach ($arg_list as $arg) { $keypair = explode('=', $arg); if ($keypair[0] == 'host' && !empty($keypair[1])) { vfio_bind($keypair[1]); break; } } } exit(0); // end of script function vfio_bind($strPassthruDevice) { // Ensure we have leading 0000: $strPassthruDeviceShort = str_replace('0000:', '', $strPassthruDevice); $strPassthruDeviceLong = '0000:' . $strPassthruDeviceShort; // Determine the driver currently assigned to the device $strDriverSymlink = @readlink('/sys/bus/pci/devices/' . $strPassthruDeviceLong . '/driver'); if ($strDriverSymlink !== false) { // Device is bound to a Driver already if (strpos($strDriverSymlink, 'vfio-pci') !== false) { // Driver bound to vfio-pci already - nothing left to do for this device now regarding vfio return true; } // Driver bound to some other driver - attempt to unbind driver if (file_put_contents('/sys/bus/pci/devices/' . $strPassthruDeviceLong . '/driver/unbind', $strPassthruDeviceLong) === false) { file_put_contents('php://stderr', 'Failed to unbind device ' . $strPassthruDeviceShort . ' from current driver'); exit(1); return false; } } // Get Vendor and Device IDs for the passthru device $strVendor = file_get_contents('/sys/bus/pci/devices/' . $strPassthruDeviceLong . '/vendor'); $strDevice = file_get_contents('/sys/bus/pci/devices/' . $strPassthruDeviceLong . '/device'); // Attempt to bind driver to vfio-pci if (file_put_contents('/sys/bus/pci/drivers/vfio-pci/new_id', $strVendor . ' ' . $strDevice) === false) { file_put_contents('php://stderr', 'Failed to bind device ' . $strPassthruDeviceShort . ' to vfio-pci driver'); exit(1); return false; } return true; } could do the list /bin/ls: cannot access '/etc/libvirt/hooks/qemu.d/': No such file or directory?
-
Thanks Squid! much appreciated!
-
Hi All I am finally going to setup multiple cache pools! 🙂 And I am wondering how to go about it in the right way? Current setup: One cache drive called "cache" Future setup; Having 3 cache drives - cache_apps / cache_vms / cache_shares Would I have to manually go and change all my dockers from /mnt/cache/appdata/ --> /mnt/user/appdata/ before renaming my existing cache drive? Would it be best to move all things back to the array (Change prefer: Cache --> Yes : Cache) and then setup all my cache drives? (The system files and the Docker image files and the Appdate would be keept on the existing cache drive!) I have all my Media dockers on my current cache drive and moving all these small files would take days! Would love to just rename the current cache drive to cache_apps and move the rest to the other cache drives? I might me overthinking this LOL Did see the video about multiple pools but in that they where all empty
-
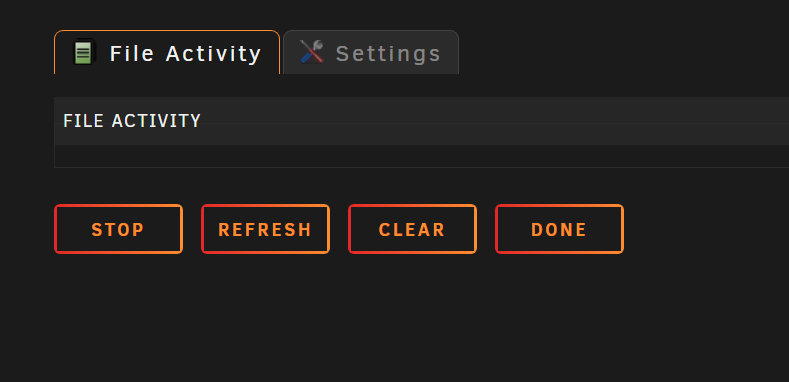
Thanks I have removed them now! I cant get the File activity working in RC4?
-
Hi All I am using the OZNU Homebridge docker. And it works for everything except the Sonos ZP plugin? I have by troubleshooting with the auther found that it is upnp that causes these problems? What network setting are you running with? Mine is: And in the UI: But I keep getting periodic UPnP announcements for .6 - the HOST! ? [4/19/2022, 9:00:21 AM] [Sonos] upnp: RINCON_542A1BE254D901400 is alive at 192.168.0.6 Any input on how to resolve this?

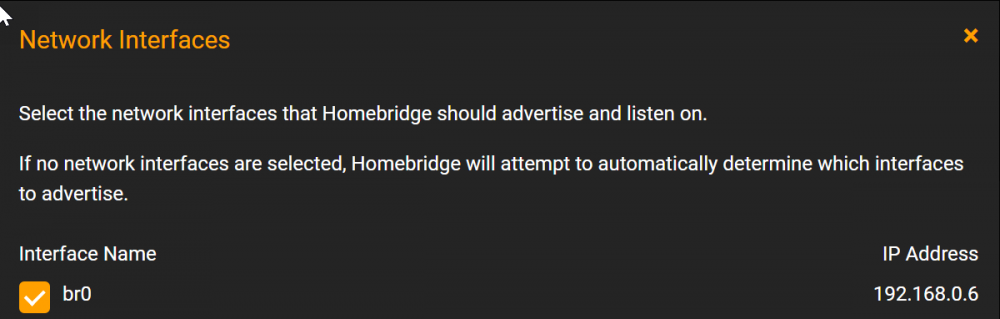
-
The monitor is a standard 1080P monitor Example opening the LOG window (Works fine on any PC accessing the UI!)
-
Thanks Trurl! How can a single file be in two places? OK I can see that the Docker img file on the cache is the new one the System file on the drive 7 is from 2020 so I deleted it (Could this write to disc 7 happen if the cache drive have run full?) So I dont think this was spinning the drive up

-
I just updated to 6.10.rc4 and installed the File activity plugin (My drives keep spinning up) But no matter what I do I dont get any activity in the plugin? Log: But its already over the default size? I then updated it to: I dont get the warning anymore but still no activity listed? Diag file attached below diagnostics-20220415-1823.zip