




casperse
Members
-
Joined
-
Last visited
Everything posted by casperse
-
Yes some time ago:
-
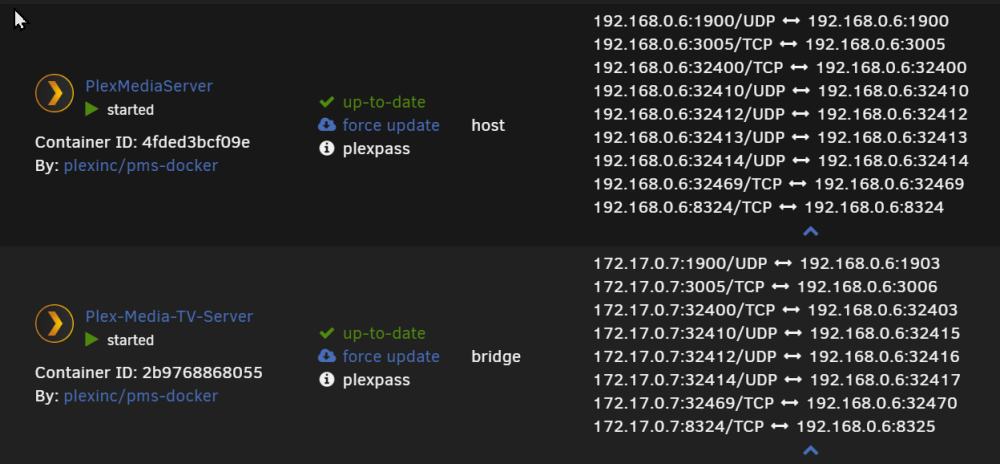
But that would result in not using the proxynet and sharing the docker naming in NMP right? I did read (Read most of all the posts in this thread) that running NMP on Host was "recommended" but since I have + 40 proxyhosts I really dont want to change all of them 🙂 Ok so I read up on ports and I changed them all like below (Making sure no ports conflicted) I now have first in Host and second running in bridge (Hmm I didn't try proxynet? would that work now?) Anyway NMP is now working with one as host and one in bridge. Thanks again for explaining this!
-
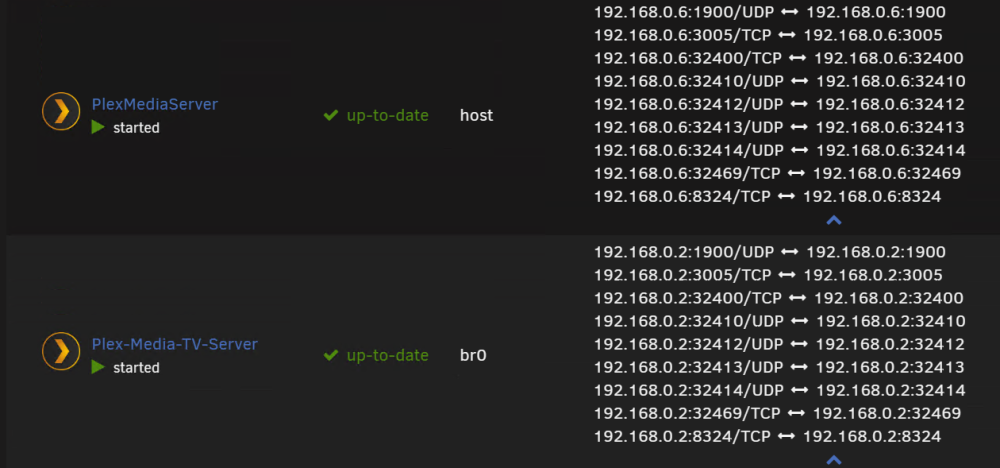
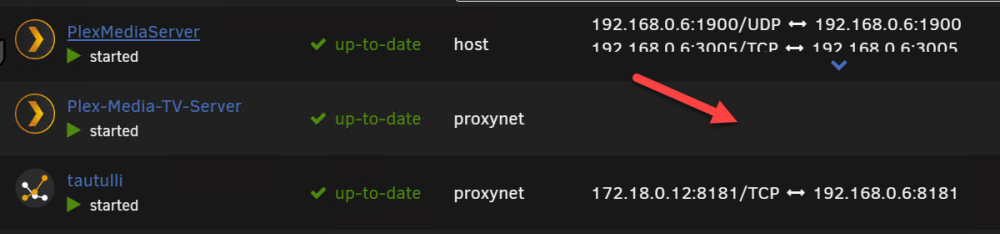
I might have this setup wrong, so long time since I did this (So sorry for asking stupid Questions, I am truly reading to find answers :-). I have like many others created my "Proxynet" and Yes I use the names of the dockers in NMP, and it works great! But I cant use Proxynet for Plex I get no IP? and cant access the Plex server (Like below) Each have there own IP now, one is Host IP and the other is br0 fixed custom IP: 192.168.0.2 If I try bridge or Proxynet I get the above or below picture with no IP? When you say changing host side ports? Is that adding each port as a variable in the docker interface and substituting them with others? (I think I once tried that, but mostly I dont change ports on Unraid dockers) NMP is on the Proxynet: My only working options so far (I have tried all other) for Plex has been to keep my main on Host and the other on Br0: I guess my Proxynet is the same as when you say standard bridge? The above br0 "works" just not for NMP - But accessing the http://192.168.0.2:32400/web works (Plex 2) I added the /web under the host to get that working long ago for the host one, and that works in NMP Doing this for the 192.168.0.2 br0 I get the: I read that the function to enable "Host access to custom networks" will be removed un this thread. So I guess its better to try other alteratives And thanks Alturismo for helping me out! Much appreciated, I think I am missing something "stupid" just cant put my finger on it.

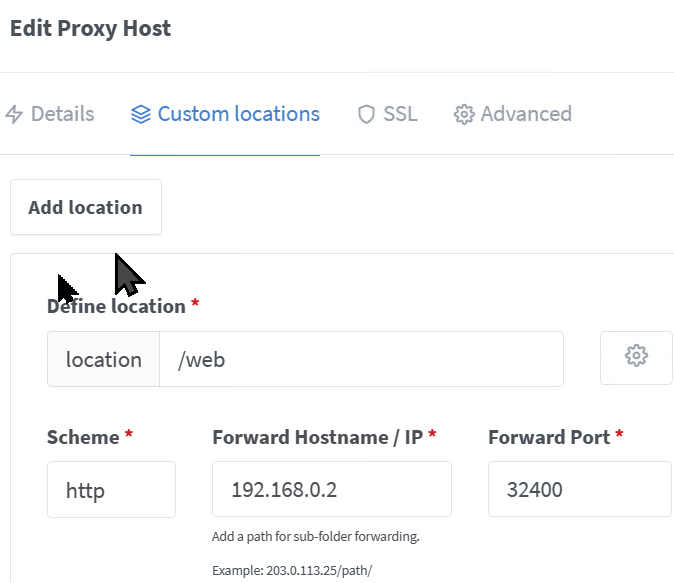
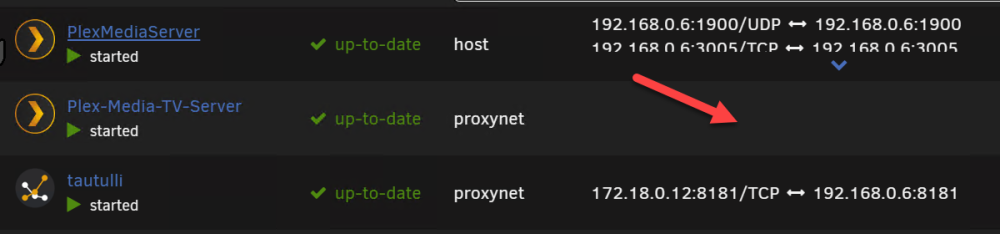


-
Sorry I am not following how to do this. (Plex really doesn't like having two instances on the same server) I already have two dockers running with each in separate appdata folders. Plex (Main): Host mode Plex (second): in Br0 - fixed IP Many people wants two Plex servers on Unraid, and end up having a second VM with a dedicated LAN port (Passthrough). All my other dockers are either using the proxynet but my Plex server (Main) needs to run in host mode. So I haven't found any way (Except maybe some special network creation to be used specially for a 2 plex server setup.) Mapping ports through a router is easy. Are you talking about mapping ports in the nginx proxy manager?
-
I dont think its possible to change the Plex internal port (Many other posts are at least saying that you cant do that)? Hmm I forgot the above setting, when I created the Proxynet on Unraid, I dont beleive it would be good to enable custom networks? Or I have to find a LAN card and make a special group for this docker 😞 Thanks for your insight!
-
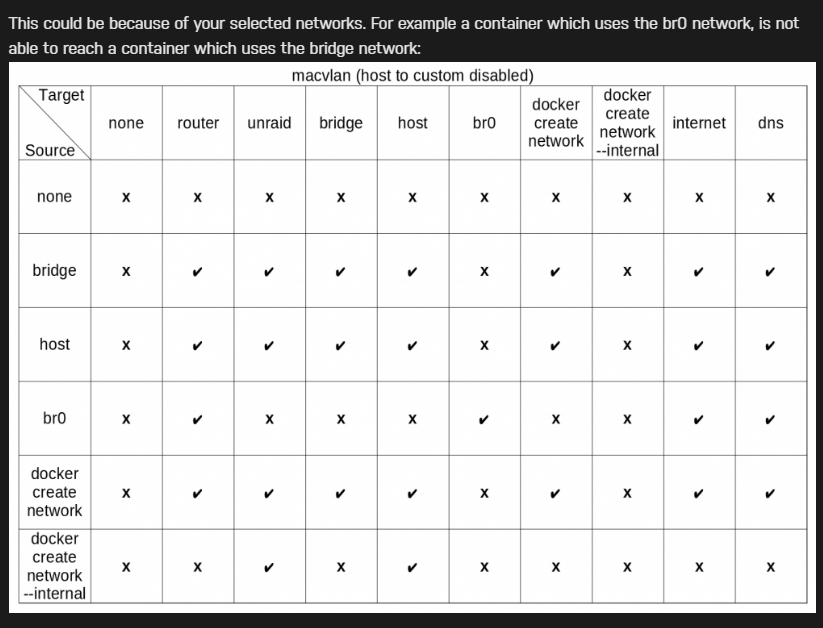
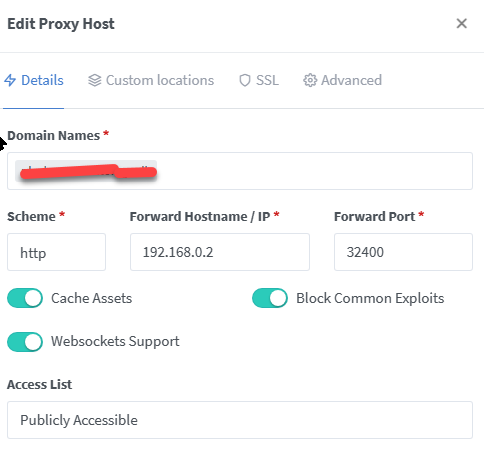
I needed a second Plex docker and did this by creating a fixed IP on br0, but is there anyway to use NGINX? I have been reading and your great table says no? My docker is working and running in parallel. And the local link works. And I did set the: I have 40 working locations, but this one keeps getting me:
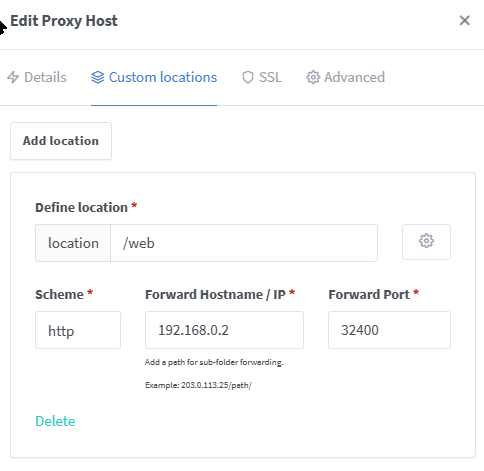
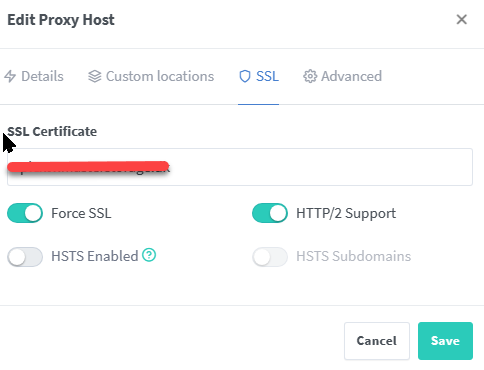
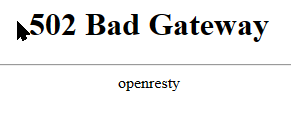
-
Solved by just creating a new Docker and selecting: My only problem remaining is getting NGINX working it somehow dosen't like the fixed IP using br0?
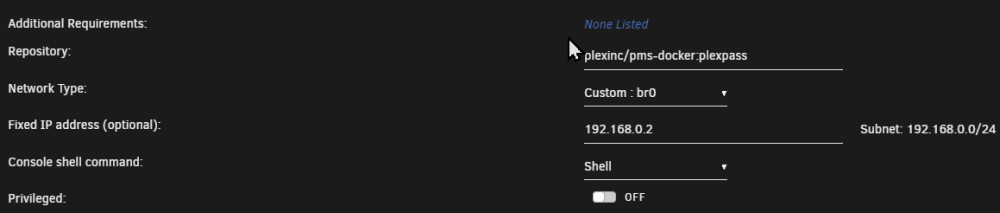
-
Not sure if its the configuration or if its some problem waking the SATBOX up from standby (This normally always work) I think the line /dev/null just removes the data so should I do this? (it didnt run during the last 24 hours?

-
Great thanks I will try that right away.... 🙂

-
Thanks so much! I used the wrong command and the bouquet name was wrong. So now I got the command working! - Now to get it running automatically. So I dont have a user and password - its a closed home LAN, can I just make the empty in the config file? (" ") Also the name of the TV Bouquet was with a space so can I just do: "PLEX (TV)" And then cron setting through the WEB UI and that should be it? I can get the picon to be loaded to xTeVe this is so great! Before I did manually matching and tuning channels this awsome!

-
This is a very old post, and Unraid have developed allot!!! 🙂 I really want to run a second Plex server to play with XteVe and the Live TV. Would it be easier to create a VM with a dedicated LAN passthrough? Or is there an easier way to do this? - So far bridging haven't been possible running in two dockers
-
I feel stupid, but reading so many posts I havnet found one that explain how to use ./owi2plex ? Reading the github I should use this command to get the XML from my enigma SAT box. ./owi2plex -b PLEX -h 192.168.0.250 -o /owi2plex/stue-epg.xml I tried executing this in the docker terminal, but with no succes. Thanks
-
Yes my existing Unraid server (See below configuration) is lacking the power to run everything. Plex/Emby/Jellyfin server yes! - But all the great dockers running on the side: NextCloud, Paperless, Synology DSM docker (NAS in a NAS with Apps) etc just needs more power and nvmes. And a couple of VMs for gaming (AMP - gaming server VM is awesome). Also I would like to have enough Nvme's for a ZFS mirror or raid to protect the data and have snap-shoot support on APPDATA and VM's. I would need a GPU for UNMANIC 🙂 but I guess the Quadro P2000 would be better in a 4x slot (And very energy efficient). The very small 3060 card was to get better quality when encoding with UNMANIC. Correct the 10G is on my list but I really want a Unifi 10G switch and I am waiting for a better product than the existing one that also supports 2,5G Network in a enterprise rack setup. I must admit that the lack of Pci-e lanes almost made me go AMD, but the iGPU quicksync performance made me choose Intel again! Like many others.
-
I have plans to use the PCI slots for: PCIe slot 1: x1 IPMI PCIe slot 2: x8 SAS Controller: LSI Logic SAS 9305-24i Host Bus Adapter - x8, PCIe 3.0, 8000 MB/s (6 connectors = Supports 24 internal 12Gb/s SATA+SAS ports - Supports SATA link rates of 3Gb/s and 6Gb/s) PCIe slot 3: x8 GIGABYTE - AORUS Gen4 AIC Adaptor, PCIe 4.0 GC-4XM2G4 PCIe slot 4: x4 NIC: Intel i350-T4 4x 1GbE Quad Port Network LAN Ethernet PCIe x4 OEM Controller card (I350T4V2BLK) PCIe slot 5: x4 NVIDIA GeForce RTX 3060 The HBA is for the backplane 48 server case, and the AORUS is for 2 addtional M.2. drives (+ the 3 on the board) I only placed the RTX 3060 because from reading I would need a GPU using the IPMI? (I might replace that with an old NVIDIA Quadro P2000)
-
THANKS! - I couldn't understand why it just stopped working! (This should be on the top page, in the support forum, its a "breaking" change)
-
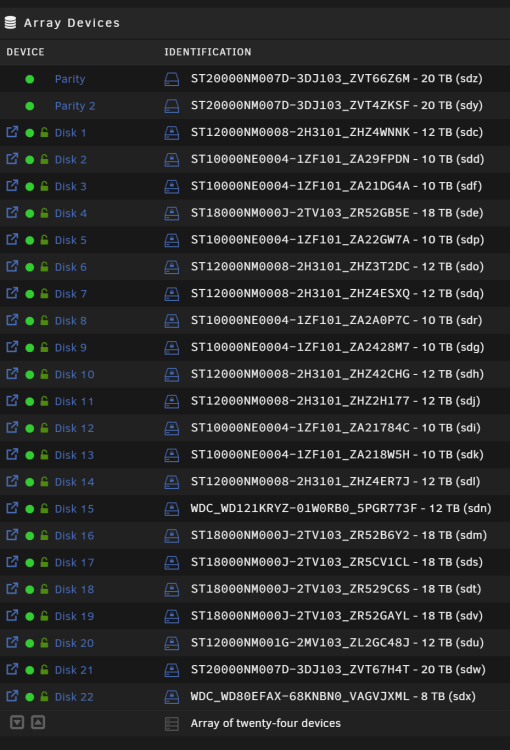
23 and 24 is the Parity 1+2 above in my screenshot. I am happy to report that all my drives is functioning in Unraid 🙂
-
Sure Thing. No emulation: Also enabled syslog.... diagnostics-20231201-1246.zip
-
I recently noticed that I now have State "Device not present" But all drive is running and working on Unraid? I have tried running the scan but same issue?

-
Yes I also found that video, looking into the data sheet for size, looks okay! (Just got the ASUS Pro WS W680-ACE IPMI on a Black Friday deal) - now looking at getting the right CPU? Since the platform is end of live (Intel will have new sockets in 2024) I thought better to go high! i9 14900K and the "tame" the power usage? - That way I can dial it up later if I need extra speed/computing power? Also my last build I always regretted that I only got 64G ram and the Intel’s Xeon E-2176G should have maxed it out. (Now that's going to be the backup server)
-
Hi @Omid I am in the same situation, what CPU cooler did you get in order to have the IPMI in the first slot? I really wanted the Noctua NH-D15 and cant find a cooler that is in the same league and can fit?
-
My turn if you still do requests 🙂 2. I will need the case manufacturer and model name. Shenzhen Toploong Technology Model: S865-48 3. I will need a picture (preferably straight from the front) 8U model, 48 drives Thanks again for volunteering to do this!

-
Can you manually set it to 4800? and if so is it stable?
-
What CPU cooler did you get in order to have the IPMI in the first slot?
-
If it doesn't support bifurcation you need a card that can do the split like the: SABRENT 4-Drive NVMe M.2 SSD to PCIe 3.0 x4 Adapter Card [PC-P3X4]
-
The video was done with measurement of wattage. So I guess the big questions is does the extra cost vs the savings in wattage make it worth it? Normally I would always buy new since IT quickly get old, but I think a server upgrade should last +5 years (Unraid)





















