




vakilando
Moderators
-
Joined
-
Last visited
Everything posted by vakilando
-
hmm, "java.lang.OutOfMemoryError: Java heap space" ist offensichtlich das Problem..... Vielleicht waren 300 Belege zu viel? Sind die einzelnen Dateien groß? Wieviele wurden erfolgreich importiert? Kannst du die (noch nicht importierten) Belege aus dem Importverzeichnis entfernen und schauen ob joex dann nicht mehr beendet wird? Es gibt auf Github ein issue (geschlossen) dem ich aber nicht entnehmen kann wie das Problem gelöst wurde: issue 284 In der Doku steht auch was, aber auch hier kann ich nicht herauslesen wie der Wert gesetzt wird: hier unter Memory usage Du kannst probieren im Joex Container in der "advanced view" in den "extra parameters" einen Wert zu setzen. In der Doku steht "When using mode=full, a heap setting of at least -Xmx1400M is recommended" Setze in den "extra parameters" mal folgendes: -e JAVA_OPTS="-Xmx2500m" oder -e JAVA_OPTS="-Xmx2500m -Xms256m" wenn du auch ein Minimum festlegen willst. Ansonsten könntest du noch ein neues Issue in Github eröffnen.
-
Wenn ich das richtig sehe, ist das von dir genannte Script der Consumedir Container. Wenn du das Verzeichnis "/mnt/appdata/docspell/docs" angelegt hast musst du noch einen Unterordner erstellen, der den Namen deines "Collective" trägt. Dort legst du die Dokumente ab und die werden dann automatisch importiert. was sagen die Joex Logs?
-
Nein, leider nicht. Es gibt aber ein issue bzw Feature Request auf Github "Nested folders & Tags" hierzu, dem könntest du dich "anschließen". Habe mich dem auch angeschlossen, da ich finde es wäre eine zusätzliche und praktische Sortier- und Suchmöglichkeit.
-
oh, sorry, nein du musst es auf "open" stellen! Ich habs natürlich nach erfolgreicher installation auf closed gesetzt, weil ich die user selbst anlegen bzw. einladen will.
-
https://docspell.org/docs/install/installing/ Punkt 4. Goto http://localhost:7880, signup and login. When signing up, you can choose the same name for collective and user. Then login with this name and the password Gehe auf die Login Seite und lege ein Konto an (sign up). Gib den Namen für das "Collective", deinen Usernamen und dein Passwort an. Anmelden musst du dich später immer in der Form "Collective/Username" und dein Passwort. Wenn du der einzige User bist und immer der einzige sein wirst, dann verwende am besten "Username/Username". Also "Collective"="Username". Dann kannst du dich später nur mit deinem Usernamen anmelden, ansonsten in der Form "Collective/Username". kleine Frage (nicht böse sein)..... kannst du Englisch? Die Doku (s.o.) ist gut und ausführlich....
-
War jetzt eigentlich die Variable CONSUMEDIR_INTEGRATION auch im Template enthalten? ....das sind nämlich meine ersten Templates, die ich gemacht habe....
-
-
klick auf docspell-restserver und im Kontextmenü ganz oben auf => "WebUI" Sollte es "WebUI" nicht geben, klick auf docspell-restserver, dann im Kontexmenü auf Edit und dann ganz oben rechts auf den Schalter "Basic View". In der dann erscheinenden "Advanced View" kannst du die WebUI auf http://[IP]:[PORT:7880] setzen (nichts ändern, genau so übernehmen). Auf jeden Fall solltest du im Browser über http://deine.ip.adre.sse:7880 auf Docspenn kommen.

-
Solr Solr wird so auf bridge nicht laufen, da vermutlich Unraid den Port 80 für sich beansprucht.... Du kannst versuchen den Port zu ändern in z.B. 81 oder du stellst um auf br0 und gibst dem Container eine andere IP. Schau mal unten bei "Show docker allocations ..." welche Ports bereits genutzt werden. Postgres Öffne bitte direkt nachdem du Postgres gestartet hast das Log, selbst wenn der Container nicht startet, sollte es ein Log (über "Edit") geben. Dann poste es hier.
-
Hab gerade festgestellt, dass für postgres die Daten doch direkt unter /mnt/appdata/postgres liegen und nicht innerhalb des Hauptordners! Habs oben korrigiert....
-
Hoffentlich hilft dir das! Ich finde Docspell richtig gut, da es sich für einen Privatanwender auf das wesentliche konzentriert (was brauch ich z.B. Workflows?!). Der Entwickler "eikek" auf Github gibt sich wirklich viel Mühe und antwortet schnell auf Anfragen. Die Dokumentation ist auch sehr gut und ausführlich: https://docspell.org/docs/ Er hat zur Zeit eine Anfrage am laufen wie man die Installation vereinfachen könnte: https://github.com/eikek/docspell/issues/675 Da werde ich vermutlich auch meinen Senf dazu abgeben 🙃
-
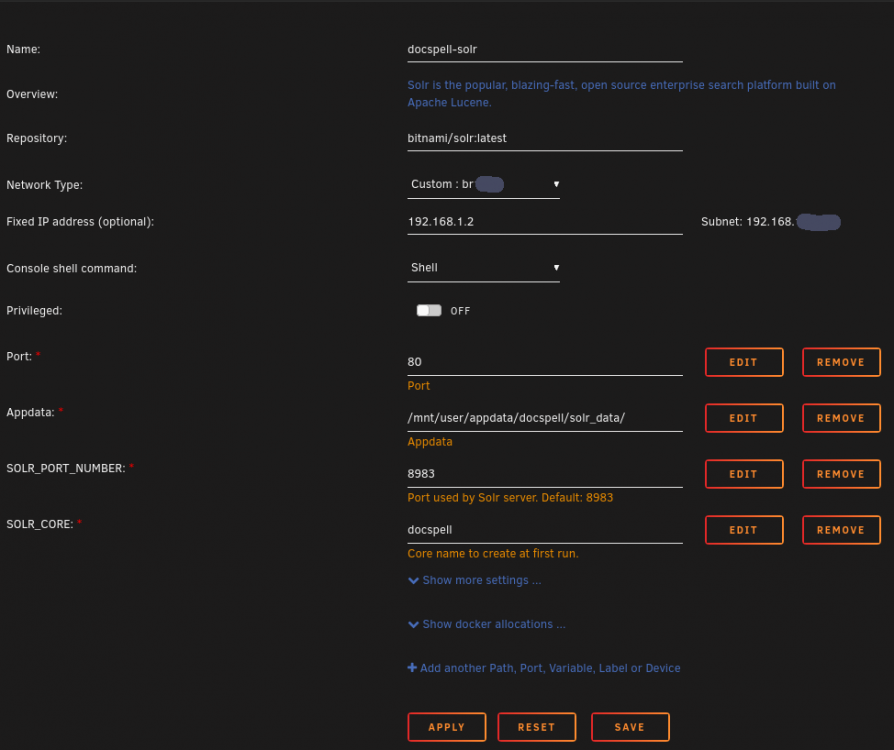
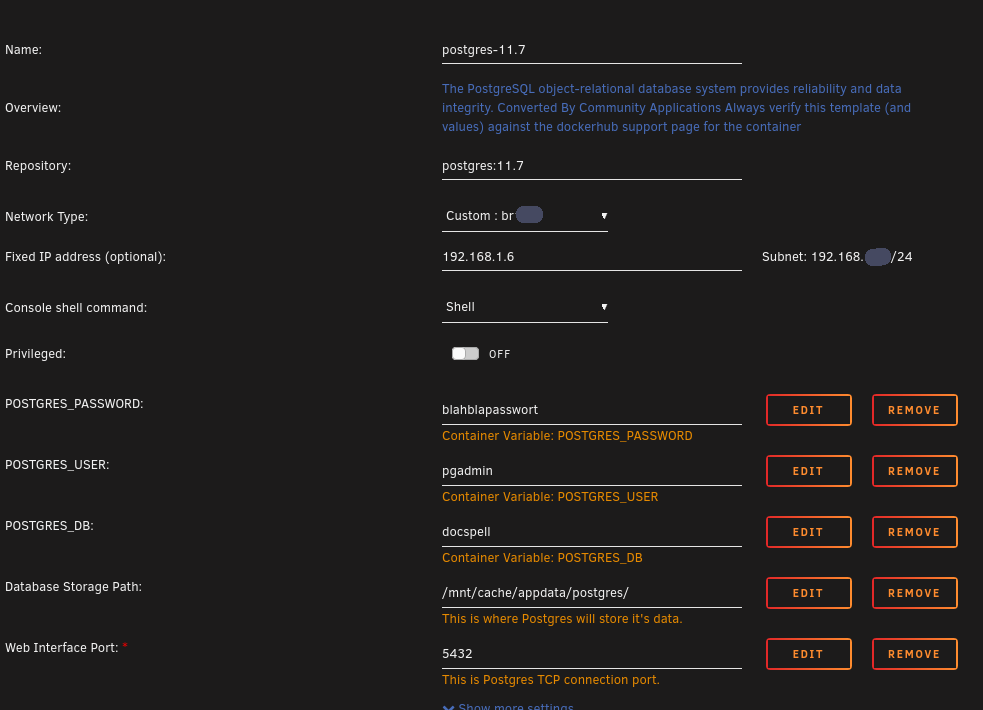
So hier sind die Screenshots der Container (gelistet in der Reihenfolge wie sie gestartet werden). Die eingetragenen Werte sind natürlich nicht meine (user, Passwörter, HeaderValue, ...) Der letzte Screenshot zeigt eine neue Variable, die noch nicht in meinem Template für das Consumedir enthalten ist. Die Variable im letzten Screenshot ist nun auch in meinem Template für das Consumedir enthalten! 1. SOLR 2. POSTGRES 3. DOCSPELL-JOEX 4. DOCSPELL-RESTSERVER 5. DOCSPELL-CONSUMEDIR Die Variable CONSUMEDIR_INTEGRATION ist nun auch im Template enthalten!
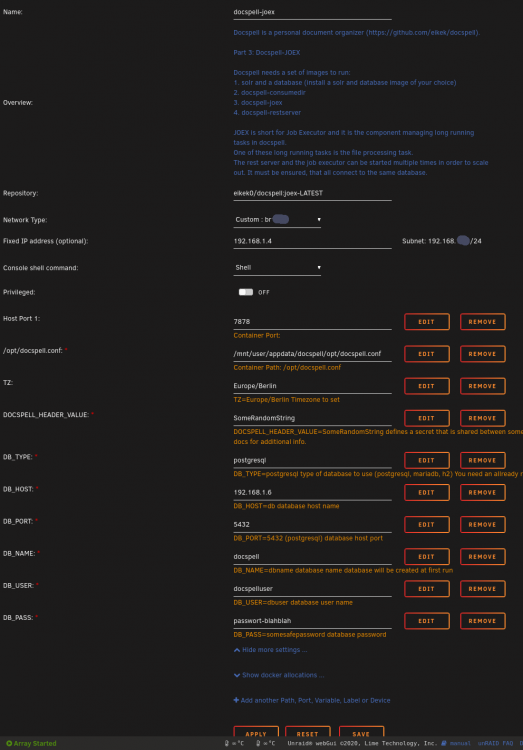
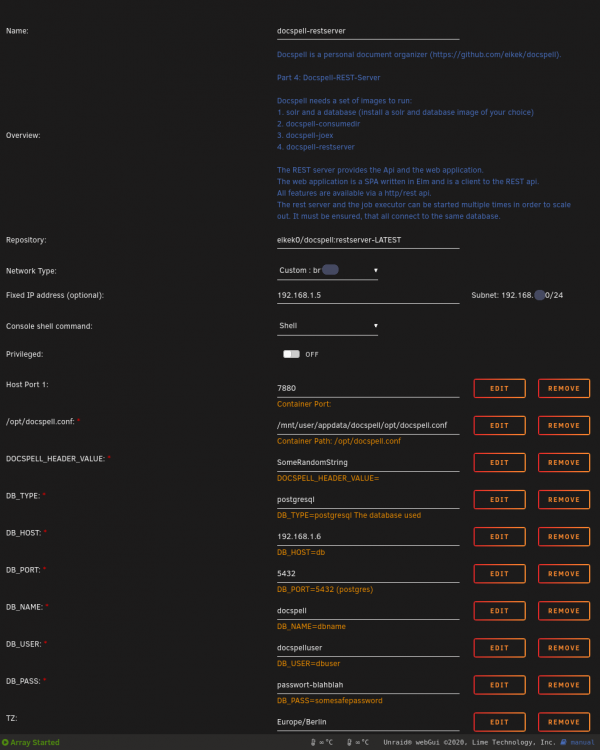
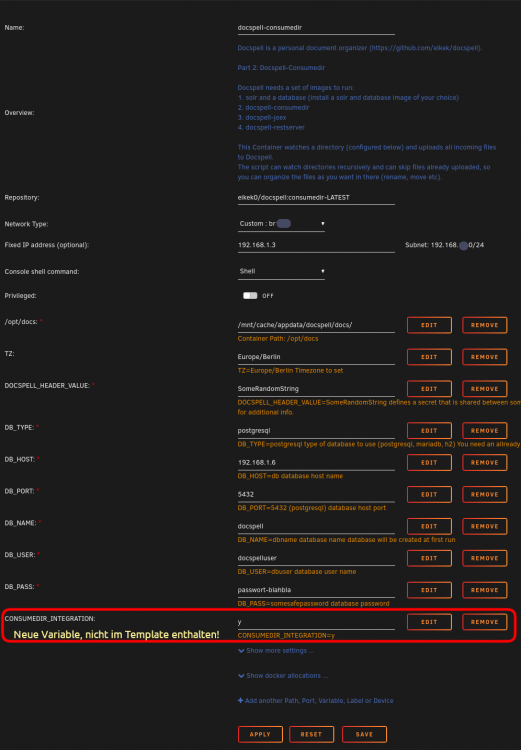
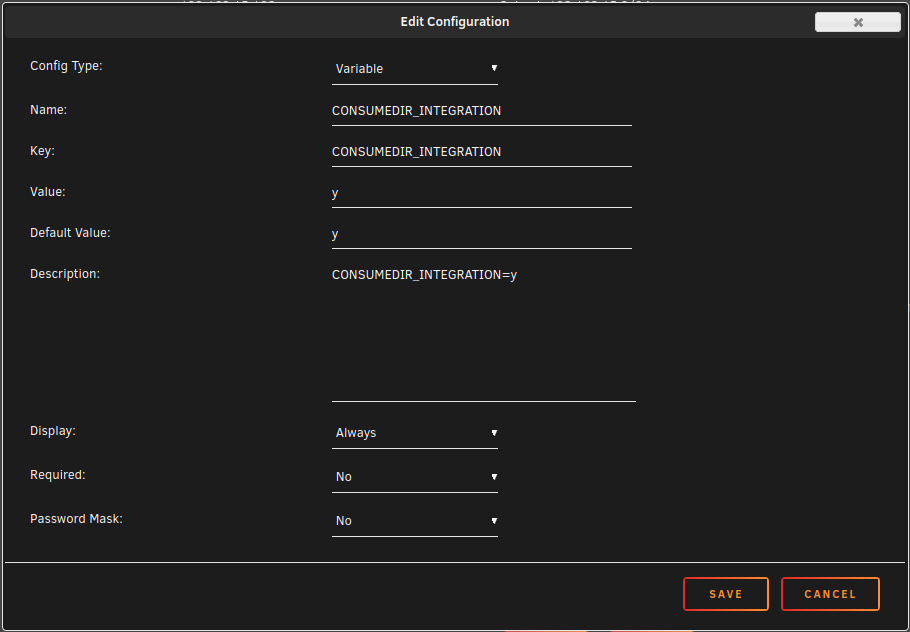
-
ich kann dir noch Screenshots meiner Docker mitgeben, sollte aber eigentlich aus den Templates hervorgehen was einzutragen ist ..... wenn ich es ordentlich gemacht habe.... Der von mir verwendete SOLR Container ist "bitnami/solr:latest" Der von mir verwendete POSTGRES Container ist "postgres:11.7"
-
Mit Ordner meinst du u.a. /mnt/appdata/docspell nehme ich an. Hast du ein Custom Network angelegt? Du solltest nämlich auch br0 nehmen können (einfacher, fällt mir gerade ein...) ....und vielleicht sogar ganz normal bridge, wenn die Container für Docspell mit den Portnummern nicht in Konflikt mit anderen Containern kommt (nicht getestet...) Meine Ordnerstruktur sieht so aus: /mnt/appdata/docspell/ => "Hauptordner" /mnt/appdata/docspell/docs => für "consumedir-container" (kann aber auch ins Array und vermutlich werde ich das auch noch verschieben) /mnt/appdata/postgres => Postgres-Datenbank (innerhalb des Hauptordners damit ich weiß dass es nur dafür verwendet wird, kann aber auch extra unter appdata liegen) /mnt/appdata/docspell/opt => da liegt die docspell.conf /mnt/appdata/docspell/solr_data => Volltextsuche (innerhalb des Hauptordners damit ich weiß dass es nur dafür verwendet wird, kann aber auch extra unter appdata liegen) /mnt/appdata/docspell/tools => Optional, dort liegt z.B. das script "export-files.sh" mit dem alle Inhalte (Dateien & Metadaten) zwecks Backup aus Decspell exportiert werden können /mnt/appdata/docspell/export => Optional, dorthin lasse ich über "export-files.sh" das Backup hinschreiben Meine /mnt/appdata/docspell/opt/docspell.conf sieht so aus (siehe auch Anhang): docspell.server { app-name = "Dein selbstgewählter Name deiner Docspell-Instanz" ####### DIE BASE-URL (entweder 1. oder 2. oder 3.): ### 1. ### Die IP-Adresse:Port die du deinem restserver Container gegeben hast (nur interne Verwendung). ### Funktioniert auch wenn du ein selbsterstelltes Custom Network hast. ### Fang am besten damit an! Kannst du immer noch ändern! base-url = "http://192.168.1.5:7880" ### 2. ### NUR WENN du ein selbsterstelltes Custom Network verwendest (externe Verwendung über Reverse Proxy): #base-url = "http://containername-des-restserver:7880" ### 3. ### Der FQDN für deine doscspell-Instanz (restserver Container). (externe Verwendung über Reverse Proxy) ### Hierfür brauchst du natürlich einen DynDNS Service mit der Möglichkleit Subdomains anzulegen #base-url = "https://docspell.deine-dyndns-domain.de" ####### bind { address = "0.0.0.0" } integration-endpoint { enabled = true ## The priority to use when submitting files through this endpoint. priority = "low" ## The name used for the item "source" property when uploaded through this endpoint. source-name = "integration" ## Requests are expected to supply some specific header when uploading files. http-header { enabled = true header-value = ein-von-dir-ausgedachter-string-am-besten-auch-mit-2ahlen } } ### Die IP-Adresse:Port die du deinem SOLR Container gegeben hast (Volltextsuche). full-text-search { enabled = true recreate-key = "" solr = { url = "http://192.168.1.2:8983/solr/docspell" } } backend { ### Die IP-Adresse:Port die du deinem POSTGRES Container gegeben hast (Datenbank). ### sowie User und dessen Passwort für die docspell Datenbank jdbc { url = "jdbc:postgresql://192.168.1.6:5432/docspell" user = "ein-user-für-die-docspell-Datenbank" password = "ein-passwort-für-die-docspell-Datenbank" } signup { # The mode defines if new users can signup or not. values: # - open: every new user can sign up # - invite: new users can sign up only if they provide a correct # invitation key. Invitation keys can be generated by the server. # - closed: signing up is disabled. mode = "closed" # If mode == 'invite', a password must be provided to generate # invitation keys. It must not be empty. new-invite-password = "ein-passwort-für-die-Einladefunktion" # If mode == 'invite', this is the period an invitation token is considered valid. invite-time = "3 days" } files { # Defines the chunk size (in bytes) used to store the files. # This will affect the memory footprint when uploading and # downloading files. At most this amount is loaded into RAM for # down- and uploading. # # It also defines the chunk size used for the blobs inside the # database. chunk-size = 524288 # The file content types that are considered valid. Docspell # will only pass these files to processing. The processing code # itself has also checks for which files are supported and which # not. This affects the uploading part and can be used to # restrict file types that should be handed over to processing. # By default all files are allowed. valid-mime-types = [ ] } } } docspell.joex { ### Der Containername:Port des JOEX Containers bei Verwendung von Custom Network. #base-url = "http://joex:7878" ### Die IP-Adresse:Port des JOEX Containers (geht auch bei bei Verwendung von Custom Network). base-url = "http://192.168.1.4:7878" ####### bind { address = "0.0.0.0" } jdbc { ### Die IP-Adresse:Port die du deinem POSTGRES Container gegeben hast (Datenbank). ### sowie User und dessen Passwort für die docspell Datenbank url = "jdbc:postgresql://192.168.1.6:5432/docspell" user = "ein-user-für-die-docspell-Datenbank" password = "ein-passwort-für-die-docspell-Datenbank" } ### Die IP-Adresse:Port die du deinem SOLR Container gegeben hast (Volltextsuche). full-text-search { enabled = true solr = { url = "http://192.168.1.2:8983/solr/docspell" } } scheduler { pool-size = 1 } } docspell.conf.beispiel.txt
-
Bin unterwegs, melde mich sobald ich wieder am Rechner bin.
-
Sadly I have the same issue.... My Home Assistant Docker (host network) has lost connection to my ispyagentdvr docker container (custom br0.6 network) twice. Stopping and starting the docker service solves this issue. I have two NICs and four VLANs.
-
Ich hatte ein solches Phänomen auch schon zweimal, da war das docker Image defekt. Einfach docker stoppen, docker.img löschen und die docker neu einrichten (unter Apps > previously Installed deine docker anhaken und "install" - fertig) Ich muss aber zugeben dass ich mir deine Diagnostics nicht angesehen habe...
-
Ich verwende den docker container linuxserver/ddclient. Welchen Domainanbieter/DNS-Dienst nutzt du denn?
-
Das klingt interessant, da bin ich neugierig was du berichtest...
-
Ich hatte bzgl. Datenbanken mit postgres das Problem, dass ich das volume mit /mnt/cache/appdata... und nicht /mnt/user/appdata... einbinden musste, sonst wollte postgres nicht starten. Probier das ggf mal so.
-
Das könnte auf ein korruptes docker Image hindeuten. Hast du in den logs weitere Fehlermeldung bzgl. Btrfs, loop2? Wenn nach einem Server reboot weiterhin immer die selben Docker Probleme machen (nicht starten bzw nicht ordentlich laufen) würde ich mal das docker.img löschen (settings>docker) und anschließend neu erstellen. Danach über Apps>Previous deine Docker neu installieren. Wenn du über Apps>Previous gehst werden alle Docker genau so installiert und konfiguriert wie beim letzten mal. Aber check erst mal das Log.
-
Ja richtig ich auch. Ich habe mehrere custom Networks und meine docker bzw vm's kommen je nach Zweck etc. in ein bestimmtes Netz. Freigaben auf Portebene erfolgen teilweise auch intern. Auf der Firewall gibt's Regeln auf Basis der Netzwerke und Ports. Auf dem switch sind die Vlans auch noch mal "geregelt". Aber homeassistant hab ich mir beim Versuch den Container auf ein custom Network (macvlan) zu konfigurieren zweimal zerschossen. Dann hab ich mich nicht mehr daran versucht. Deconz habe ich nie versucht auf ein custom Network (macvlan) zu konfigurieren. Ich könnts ja nochmal testen...
-
4436 denke ich.... Die Deconz Integration von Home Assistant findet den Deconz automatisch, angezeigt wird nur die IP und kein Port. WebGui ist auf Port 86 (siehe Details) und nicht 80 (siehe Übersicht) Docker Container Übersicht: Docker Container Details (Edit): Das Device taucht in der Konfig zweimal auf (DECONZ_DEVICE + Extra Parameters), ich weiß aber jetzt nicht mehr ob & warum das nötig ist / war.... Unraid Host: netstat root@FloBineDATA:~# netstat -ano | grep 4436 tcp 0 0 0.0.0.0:4436 0.0.0.0:* LISTEN off (0.00/0/0) tcp 0 0 192.168.1.222:54616 192.168.1.222:4436 ESTABLISHED off (0.00/0/0) tcp 0 0 192.168.1.222:4436 192.168.1.222:54616 ESTABLISHED off (0.00/0/0) HA Container: netstat /config # netstat -ano | grep 4436 tcp 0 0 0.0.0.0:4436 0.0.0.0:* LISTEN off (0.00/0/0) tcp 0 0 192.168.1.222:54616 192.168.1.222:4436 ESTABLISHED off (0.00/0/0) tcp 0 0 192.168.1.222:4436 192.168.1.222:54616 ESTABLISHED off (0.00/0/0) selbes Ergebnis, logo, läuft ja beides als "Network Type" Host

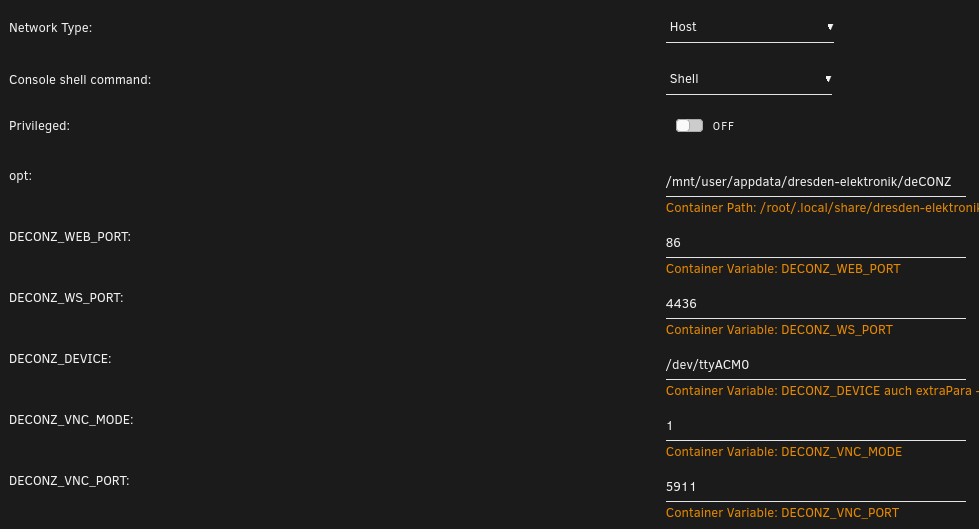


-
same here: two of the corrupt files are not mentioned and I don't know what/where the third one is Jan 6 03:31:59 bunker: error: BLAKE2 hash key mismatch, is corrupted Jan 6 03:51:41 bunker: error: BLAKE2 hash key mismatch, is corrupted Jan 6 03:58:50 bunker: error: BLAKE2 hash key mismatch, ng/fs.json is corrupted Jan 6 04:02:59 bunker: Verify task for disk1 finished, duration: 1 hr, 2 min, 58 sec. Jan 6 04:02:59 bunker: verified 198104 files from /mnt/disk1. Found: 0 mismatches, 3 corruptions. Duration: 01:02:58. Average speed: 36.1 MB/s
-
Wie gibst du den Stick an den Container frei und ist der Treiber von dem Stick in dem Container enthalten oder braucht der einfach keinen (weil er zb wie ein Laufwerk funktioniert)? Sorry für die späte Antwort und nochmal sorry da meine Behauptung, dass ich den ConBee II im HA Container nutze so gar nicht stimmt.... Der ConBee II steckt im Unraid Server und dort läuft der Deconz Container (https://hub.docker.com/r/marthoc/deconz/). Im Deconz Container habe ich den Stick unter "Extra Parameters:" angegeben mit "--device=/dev/ttyACM0" In HA widerum habe ich die Deconz Integration geladen und verweise auf den Deconz Container. Eine Anleitung für den ConBee II gibts hier: https://forums.unraid.net/topic/92946-support-spaceinvaderone-deconz/ Die bezieht sich allerdings auf einen anderen Container, den es nicht gab als ich meinen installiert habe. Aber das ist ja nicht schlimm, es geht ja hier eher um das "Finden" des Sticks.















