




Everything posted by caplam
-
thank you for your answer. i think i'll go for it.
-
Currently my array is set up as this: 6TB drives for P1&P2 4TB for disk 1&2 (used for personnal data i don't want to loose) 4TB disk3 6TB disk4 4Tb disk5 Disks 3, 4 & 5 are for media files i also have 3 single ssd xfs pools. I want to upgrade drive capacity. Currently it seems that 16TB drives have the best price/capacity ratio. For the array the final situation would be: 16TB for P1 & P2 6TB for D1 (replacing former D1 &2) 16TB For D2 (replacing former D3, 4 & 5) What would be the less stressful (for the disks) and most secure (for the data) path to migrate ? As i now have a good connection at home (8Gb/s download, 700Mb/s upload) i plan to migrate my nextcloud data (currently on spinners) to a ssd pool but i want them to be protected. In the past i had trouble with btrfs pool which destroyed my ssd in a few months (reason why i have one ssd xfs pools) So i think of making 1 or 2 zfs mirror pool. I know i have to wait for a future release to have zfs integrated in unraid. Currently data on ssd only are docker img, libvirt img, appdata, domains and system; downloads are on ssd too but mover takes action. I have backups for ssd only data and for data on D1 & D2. Will the zfs integration allow zfs pools to act as cache of the array ? any release date leaked ? For the zfs pool i bought entreprise grade ssds with 1,3 dwdp for 5 years. edit bonus question: if i have a share set as cache only and i modify it to be cache yes or no, will the mover take action ?
-
it was a good opportunity (250€ for the 6 drives). and i have spare. i was also looking at ssd with better endurance than traditionnal 600TBW of mainstream products. I don't have nvme slots so the only way to use nvme drives is to use pcie slot. The motherboard don't have bifurcation ability so i have to use a plx chip base card. I'm not looking for the absolute best transfer rate. I need space for docker img (60GB), libvirt, vm (240GB), download (new as speed will normally dramatically increase), nextcloud data (250GB, new as with my current connection it's not possible)
-
Hello, At present i have 3 pools of 1 ssd formatted in xfs as i had problems of write amplification in 6.8.3 with 2 ssd btrfs pool which killed my ssds in 6 months. Until now my ssd are sata ones and of course i have no data protection with 1 drive pools. I bought 6 1tb nvme drives with better endurance specs. The server itself is a hp Z620. So pcie is Gen3 It has : -2 pcie3 x16 slots -1 pcie3 x8 (x4 electrical) open ended -1 pcie3 x8 open ended For the moment i have: 1 quadro P400 (plex transcoding and tdarr) 1 quadro FX380 (passtrough to a windows vm) barely used 1 card with 1 nvme port and 2 sata port (only using sata for now) 1 HBA 9207 8E for my jbod case But fiber connection is about to come so i also bought a 10Gbps card with SFP+ module. So better download speeds, possibility to expose plex and nextcloud outside the lan. I have to buy a plx chip based card to plug 4 nvme ssd. ssd are hynix pe4010 (so pcie gen3 and about 2,5G read and 950 Mb write max) What would be the best usage of the server slots ? Should i set up 1 or 2 ssd pools ? Which plx card to choose ? The best is x16 -> x4x4x4x4. It also exists a cheaper x8 -> x2x2x2x2
-
an intel core 13th gen on a mobo with w680 chipset. Expensive and hard to find mobo and ddr5. You need a serious budget. But you can also go for an older gen with xeon (for ecc support). I wouldn't take older than coffe lake xeon which integrate the uhd P630 igpu which is fine for transcoding hevc files. I'm also considering a new server and like you i want ecc ram (and also ipmi). I think i could go for a micro atx mobo (X12STH-LN4F) and a E-2356G. I need to complete with ram and a case. CPU+mobo is around 1k€.
-
You are right, a T400 is just fine. Is it limited to 2 streams like the P400 without hack? I would buy the 4Gb version rather the 2Gb. An intel GPU ARC could also be an option. It's not yet supported but if i remember driver should be available when unraid integrate linux 6 core; and intel arc take care of AV1 encoding.
-
if you have room for a gpu go for a P400 or P2000. I also think that compatibility for transcoding for an amd igpu is not good. So if you go for an amd cpu you would probably need an external gpu. The logical way would be to add a quadro (P400 or P2000) ans if it's not enough change mobo and cpu.
-
thank you i had the same problem
-
I think you should be able to use igpu for plex. Take a look at the options concerning gpu, onboard gpu,... in the bios.
-
i lost access to webgui. With ssh i stop docker influxdb and now i'm back in gui. But parity check is running at 200 ko/s. What can possibly go wrong? I didn't make any change on my server. edit: after stopping my entire monitoring stack (telegraf, influxdb, grafana, unraid api, varken, parity check speed up to 5Mo/s and it continues to speed up. As influxdb was eating cpu (i have to determine the cause), i wonder if mover is running. Is there a wqay to monitor mover ?
-
In fact the entire server is unresponsive. I can't display htop by ssh. The only thing which reacts is a vm. I'm away for a week so i've not physical access to the server. I've not seen problems in syslog. Last week i had problems with shfs which disappear after a reboot. Have you an idea of what can go wrong edit : i have doubts about influxdb docker which seems unusually power hungry godzilla-diagnostics-20230106-1443.zip
-
Hi, i already have an unraid server based on hp Z620 + sas enclosure. I want another server in another location but i want a smaller one. My idea is to go for silverstone ds380 case. What couple mobo/processor would be ideal? I'ill probably run 1 or 2 vm (1 linux 1 windows), a bunch of dockers (probably the same i have in the existing server around 20 30 dockers). I want a server able to transcode with plex (2 or 3 streams) ans it's better if i have not to add a gpu. My existing server has 128Gig ram but use only 12%. CPU is a dual E5 2650V2 and load is around 15%. I don't know if i go for amd or intel and which gen.
-
with 2.00.15 it seems good to me. it started as soon as i restarted the node docker.
-
up! the problem is still present and i wonder if that's why transfer speeds with smb to macos is pretty damn slow (40min to transfer 5Gb) the mac address detected by the router are the physical adress of the adapter and a mac that seems tied to docker. 289: shim-br0@br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 46:8a:aa:36:26:bf brd ff:ff:ff:ff:ff:ff notice : the address has changed since my last post
-
i changed the name to "godzilla" and i also tried with "godzilla docker" godzilla is the name of my unraid server. Of i course i restarted both dockers.
-
and the other options
-
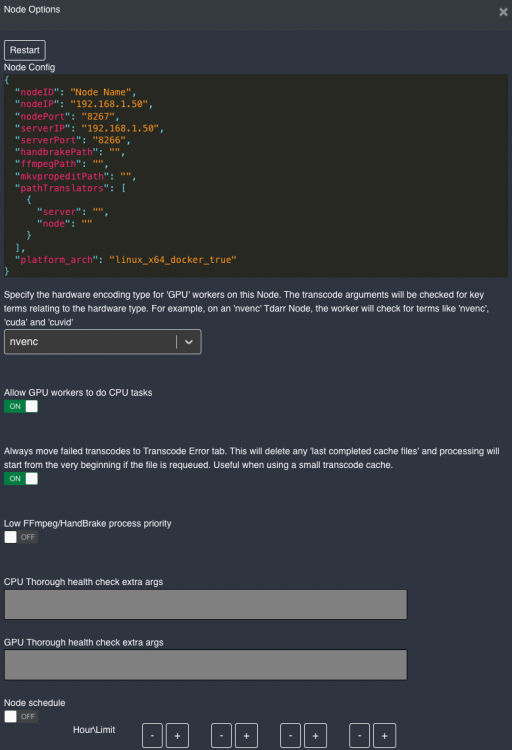
it's not a new node. All was working until i changed node name.
-
i found something strange. I have only one node. Server and node are dockers on my unraid server with default parameters except for ip of course. If i change the node name which is defaulted at "node name", the queue is stuck. As soon as i set it to "node name" back the workers start.
-
it all depends of the load. Nobody can answer your question. It's not the size of your library that matters but the number of clients across your various dockers and/or vm, the need of i/o, disk troughput,...
-
you have no A record. From my understanding you should at least have : A wipzcream.com "your ip" CNAME nextcloud.wipzcream.com wipzcream.com and others depending on what others servers you may have. edit: i don't know how it works with your registrar but with mine A and CNAME records have to be with the complete subdomain name.
-
i guess you don't have shown all your dns zone declarations. Investigate with a dns checker for example
-
try to empty your browser cache
-
I'm far from being expert but i think your dns declaration is wrong. you should use: CNAME Nextcloud dynamix.wipzcream.com you have assigned ip to dynamic.wipzcream.com so cname declarations should match this name for others subdomains.
-
Hello, my router tells me i have 2 devices using the same ip. the ip is used by unraid server. I can't find the other one. arp -a on a lan host return unraid ip with an unknown mac address. I can see the mac address in unraid with ip link and it's attached to shim-br0@br0 i use one physical interface i have only one vm running with a different mac address. I have dockers running and one has a different ip (heimdall) what can be this mysterious device? edit: from my understanding, considering the interface shim-br0@br0 it should be a docker on custom network but i can't find it
-
I don't know, didn't do the math but 1 pass preclear on 6Tb is 24H. 2 disks to rebuild (4 and 6Tb). If it can rebuild 2 disks simultanously at 100MB/s i guess it could be done in 17 hours. For now i'm waiting preclear end on 6Tb replacement drive. 4 tb just finished 1 hour ago. edit: rebuild has started for 2 disks.


