Everything posted by caplam
-
Did you check that you have no others access to disks? It may seem a stupid question but a few weeks ago the same kind of thing append to me and the culprit was my time machine backup which running at the same time. Parity rebuild was stuck at low speed (12MB/S). Speed went up few minutes after i cancelled tm backup.
-
My main unraid server is a ms01. As said by @jorgeB it works in uefi with secure boot disabled. I just have a problem with it : on every boot it needs bios password to be entered. Did not find how to disable that. It can be an advantage to enter bios more easily.
-
you have to setup all dockers for these apps like network, port, path but settings of the app itself should be in appdata folder assuming you install the same docker image.
-
Is speed set to auto ? And how is set other end ?
-
godzilla-diagnostics-20240515-1025.zip
-
rebuild is still in the go. However i'm wondering why disk1 is still showing as emulated. All disks are 16TB ones except disk1 which is 8TB. parity check is at 14.3TB. Disk 1 should be reconstructed.

-
when you loose access to gui the simplest is to reboot with gui so you can make your network settings adjustments. I would begin with a single interface to test network speed. I also have 2x10Gbe interface on my main server. For now only using one. I have a 10Gbe interface on my backup server and a chinese 10G switch. with iperf i tried from or to main server and speed is around 9,6G. For now i didn't tried with bonding as my primary intention was to dedicate 1 10G interface to backup to remote server.
-
right now it's a bit better as i didn't pay attention my mac choose this time to do a time machine backup. So i stopped it but it's still far from ideal speed i'd expecting. godzilla-diagnostics-20240514-1400.zip edit: it's odd but suddenly speed went up and now syncing at 260MB/s.
-
i did that and now it's syncing. But it's super slow. Estimated time for finish: 15 days speed is 12MB/s. Till now with these disks it was around 180MB/s.
-
hi, I made mistake while trying to reset my nmc card on apc ups. The power cord from my das unplugged. I rebooted and now i have parity 1 and disk 1 disabled. How can i proceed? godzilla-diagnostics-20240514-1231.zip
-
I've done something similar. First add the 2nd parity drive and let the system build the parity2. Then replace a 4tb drive with a 14tb. You could replace 2 4tb at the same time since you have now 2 parity drives but i find it more secure to replace a single disk at once. When your 2 14 tb drives are reconstructed. You have to move data from the 4tb to a 14tb drive and follow the procedure documented in storage management (clearme script). I've done it 2 times with success and very little downtime. Don't forget to setup your shares accordingly (disks included or excluded) Depending on the number of ports usable on your computer you could do it differently but i think it's the safest way to go. It's quite long but there is very little downtime (only the time to stop and start array) each time you have to change disk assignment and your data remain protected. Also don't hesitate to see the doc of storage management it's very helpful (https://docs.unraid.net/unraid-os/manual/storage-management/)
-
You have to stop docker engine in settings/docker/enable docker If you have other containers you will have to redownload them. You can go to the doc which is really helpful for understanding the different ways to configure docker.
-
Your docker image size is 20GB so it's too small to download a 22GB docker image. You have to make it bigger.
-
Although i have no zfs pool i experienced very slow transfer to array or unassigned disk. The culprits were smr disks.
-
thanks. Sometimes you don't think to the simplest solution.
-
Hello, I have 2 unraid licenses: 1 pro and 1 plus. The pro is attached to my main server (8 devices attached) and the plus to my backup server (11 devices attached). On my main server i use big drives (16TB) and on my backup server i have a mix of 4 and 6TB drives. I can only add 1 drive to backup server. Can i switch licenses between servers ?
-
Imho in unraid, docker data you want to back up need to be bind mounted to a host directory. Aio doesn't support modification of volumes except for data and backup directories. If you use a docker.img file it's mounted to a loop device when docker engine is started. In theory after installing aio you could try to start docker engine with all containers stopped and browse volumes inside. By default aio create named volumes so they could more easily identified. You could install portainer for locating these volumes. But i seriously doubt it's possible to restore your data in that way.
-
Do you have a backup and associated password ? If so don't bother with volumes other than the one i mentionned. Setup mastercontainer, restore the backup and you are done. See here the backup part. The whole point of aio is to build a whole instance of nextcloud without dealing with interaction between containers. Before aio i was using separated containers. I always failed to add fulltextsearch or redis and each update was a nightmare (50% of time nextcloud stayed in maintenance mode or there was an update error). Not to mention multiple errors as "/.well-known/caldav" i was never able to solve. You certainly loose control over certains things but with aio you spend considerably less time making it work.
-
I think your best bet is to recreate the data volume paying attention to permissions, reinstall mastercontainer and then restore the lastbackup. Assuming of course you have the backup and the password associated. When i installed aio i followed this : https://myunraid-ru.translate.goog/nextcloud-aio/?_x_tr_sl=auto&_x_tr_tl=en&_x_tr_hl=de&_x_tr_pto=wapp
-
I don't really understand your question. If you followed the guide for setting up aio your data are on a share outside of docker file. probably /mnt/user/aio/data The best way would probably be to restore your borg backup. I had to restore once. After setting up the mastercontainer you restore the backup. I don't think you can reinstall all dockers with your data and databses without using borg.
-
it's perfectly fine to expose services through a reverse proxy. For unraid gui itself it's generally advised to access it through a vpn.
-
I had the same problem. You don't need a static ip but a public ip. My isp charge 30€/month for static ip but 3€ for public ip.
-
good idea this container. I'll be able to keep a trace of the hundred of bookmarks i have. I installed it with the compose plugin.
-
thanks. It looks like it's the right diag. Changed the port to the ahci controller for theses 2 disks (they were the only ones on the scu controller). No issue at booting and currently running diskspeed benchmark. Never had a glitch in years with the scu controller. Luckily i don't need these 4 ports. What drove you to scu in diags ? I made the same deduction but only when i saw that the 2 drives were the only one attached to the scu.
-
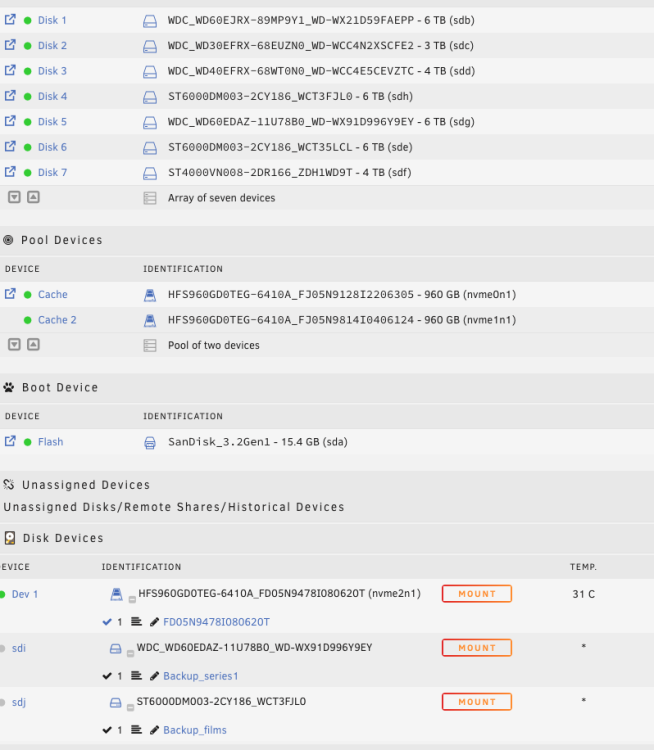
Hello, Recently i repurposed my main server into a backup server with a plus license. The array has 7 disks with no parity. Cache pool is 2x1Tb ssd btrfs pool. I have a strange issue (see the picture). 2 disks are visible both as array disks and unassigned devices. I can't stop the array. 1 disk has read errors. For the other one with issue i don't know. Perhaps a connection. Before repurposing the server disks had no problems. 2 disks are in a sas das (disks 6&7). The other ones are on internal sata ports. z620-diagnostics-20240410-1357.zip