




caplam
Members
-
Joined
-
Last visited
Everything posted by caplam
-
back in unraid 6.8.3 i had a similar issue. Docker was running from a btrfs pool. Writes on the pool killed my ssds in 8 months. I managed to lower writes by - using directory for docker instead of image - use a single xfs pool - add --no-healthcheck as extra parameters for most of my containers - and use a ram disk for dockers logs. This one is great thanks to @mgutt: link to the topic Besides of this i also bought longer life ssds. Depending of my activity i have around 50 running containers.
-
Compare the mac address of the bonded interface with the one in your arp cache on your desktop.
-
i had that problem too. I think to have logout from connect and log back.
-
My new unraid server is a ms01 so i want to do better usage of networking interfaces (2x2,5G 2x10G). one 2,5G is not used reserved for vpro My old unraid server is now a backup server. (2x1G 1x10G). one 1G is not used reserved for vpro. I also want to improve my networking skills. I bought some chinese switchs for upgrading to 10G (definitely too expensive to keep an all unifi gear for this kind of stuff) The simplest way to do is to use 10G interfaces for both servers. Eventually make a 2x10G bonding on main server. But as i want to learn networking i plan to create vlans. If i understood correctly unraid doesn't like to have more than one interface in a network. I could setup main server as follow: 1x10G :etho default vlan all unraid traffic 1x10G: eth1 vlan10 traffic to backup server backup server 1G: eth0 default vlan all traffic 10G: eth1 vlan10 traffic from main server I tried with direct connection between the 2 servers (no vlan, no dhcp, no gateway, static adresses). It works ok at 2Gbs with luckybackup on main server (without cache involved). As the 2 servers won't be in the same room i will have a backbone fiber link between switches. Network is as follow: switch0--------10G-------->switch3-------10G----->switch4 there is another link: switch0-------1G-------->unifi dream router------>ISP switch0 is in the basement switch3 is on 3rd floor switch4 is on 4rd floor Am i correct to assume i have a trunk (to allow all vlans) to create on 1 port of each switch ? For the 2 servers i will have 1 interface in default vlan and 1 in vlan 10. To put an interface in a vlan i can make it with the switch config. For what use is the option in unraid "enable vlans" ? can you create subinterfaces in differents vlans? Later when i will be more familiar with vlans i plan to creates others: iot, voip, cameras. Is it a correct way to enhance my network usage and security ? What should i do differently?
-
I had issues too with btrfs. So now i have a btrfs pool which holds appdata and a xfs pool which holds docker directory.
-
no raid pool in unraid with xfs. I guess you have to go with btrfs perhaps zfs too.
-
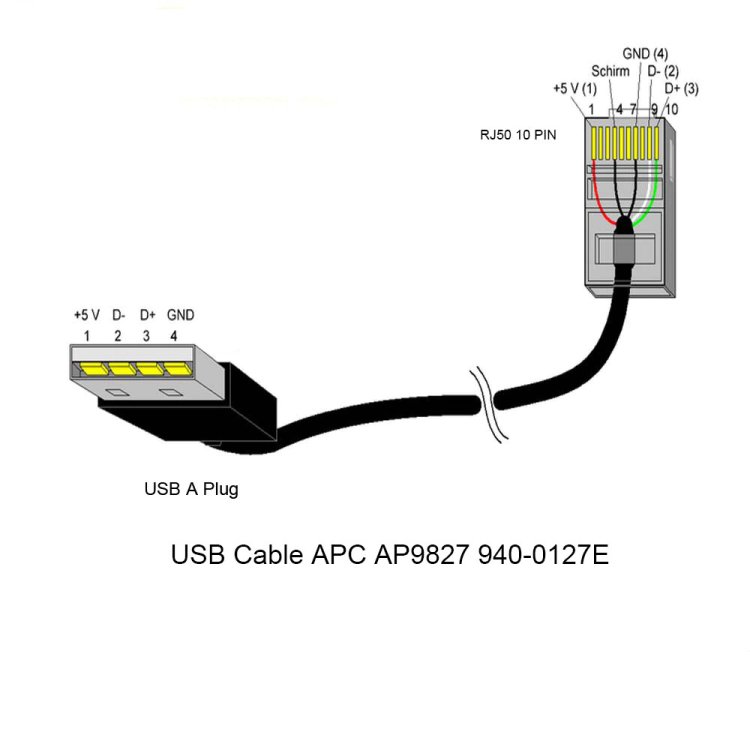
You have to make sure you use the right cable.
-
i have an apc ups (smart ups 1000). I have to choose ups type: modbus to be able to pull data.
-
There was a time i had many devices and servers on my network. All that stuff was quite power hungry. I moved and dropped most of the stuff i had. I kept network devices (unifi gear ) that i'm willing to sell to have smaller and savier devices. I'm replacing my main unraid server which is a HP Z620 with sfp connect x3 10Gb card with a small minisforum ms01 (2xSFP+, 2 x 2.5G). I use one of the 2 2,5G port fort vpro management (corresponding interface is down in unraid). In my basement i have a switch (unifi 48 poe) with uplink to 1st and 3rd floor (1G link from switch sfp cages to transceivers). There is only 5 ports on 52 used and it consumes around 65W. On the basement switch there will be the minisforum MS01 and a rpi. The Z620 will be moved to third floor and will be a backup server. As a good geek i'd like to leverage the capacity of ms01. So i was thinking on using a 10G interface for dockers, vms, unraid gui and the other 10G interface for the link with backup server. Is it possible ? and does it make sense? i would need to replace the us48 switch with a smaller one with at least 4sfp+ cages (hassivo seems to be a good option) and the 3rd floor transceiver with a sfp+ switch.
-
After updating to 6.12.8 my unraid gui is bound on port 80. The problem is that it's set on port 3080. It's also bound on port 3080. As a result nginx proxy manager can't respond and my nextcloud instance can't be joined. godzilla-diagnostics-20240304-1636.zip edit: netstat doesn't show a socket listening to port 80. it's weird. edit2: after a reboot things are back to normal.
-
if you use plex you need to have clients able to handle your media files without transcoding. Your server cpu is to weak for that.
-
just hbas: lsi9207-8e in the old and lsi 9300-8e in the new. For now i'm fighting with the minisforum ms-01. It's tricky to have it running as i want.
-
My plan is to move all disks and ssds from the old server to the new. The new server is going to replace the old; so normally i have not to transfer data across the network. I want to keep everything (shares, dockers, vms,...). I have to deal with different hardware for docker (plex and tdarr use quadro p400 on the old server for hardware encoding and it will be quicksync on the new one). I have no hardware passed through to the vms. On the old server parity, disks 1,2&3 are on internal sata ports; the others in a sas enclosure. On the new servers all spinners will be in a external sas enclosure. Then later configure the old as a backup server with other disks probably as unassigned drives. Of course i'm aware i can't have 2 servers with same ip (i have dhcp reservation on the router). I don't need both servers to run at the same time.
-
Few answers here. I will rephrase. I have 3 vm, 50 dockers, 6 disks and 3 ssd to move from one server to another. Hardware is quite different. I will come from a bi xeon E5-2650V2 with quadro P400 to minisforum MS-01 with i9-12900H. I have 2 license keys: 1 pro from the old server and 1 plus not yet installed. I'd rather keep the ip of the old server for the new one so i have not to reconfigure everything. I will use the old server as backup server. What is the best way to do this?
-
Hello, I have a server with a pro key. Array has 5 data drives + 2 parity There is also a 2 ssd btrfs pool and 1 ssd xfs pool. The server is a power hungry HP Z620 with a 9207-8e hba and a das attached. Backups are made on unassigned drives (btrfs) and on a external usb (exfat) attached to my macbook air. I moved and now my server is in the basement not very accessible. I have no ipmi and intel amt vpro is not very convenient (no kvm) on the Z620. For power savings purpose i've just bought a minisforum ms01 and a unraid plus key to run my unraid server. The plus key is enough for my arraid and pools. I plan to repurpose the Z620 as backup server. The Z620 has 128Gb ram. The ms01 will have 64Gb ram and also a 9300-8e hba. What is the best way to set-up the ms01 to make it my principal server ? edit: in the Z620 i have a nvidia P400 used for transcoding in plex and tdarr in the ms01 i will use quicksync. I want my vm and dockers to be configured from the 1st server. So in these conditions what's best? -configure the ms01 as new server with new key, the later reconfigure backup server -use the actual usb key for the new server
-
Hello, i'm facing a problem i can't solve. My unraid server has 3 nics. 2 are integrated and i keep only one active for amt purpose. The 3rd is a mellanox 10G bound to eth0. Bridging and bonding are inactive. For docker i use custom network on eth0 with macvtap. My network gear is unifi. The gateway is an usg3. I want my unraid on 192.168.1.50 reservation is made in unifi controller. In unifi controller is see eth0. It takes the right ip but after some time the ip change to 192.168.1.34. This ip (34) is also the adresse of an interface on the mellanox card which is listed in unraid as vhost0 interface. What is this interface ? Why eth0 keeps changing ip ? Can i delete the route to my lan with vhost0 as gateway as it has a smaller metric than the one with eth0 as gateway? godzilla-diagnostics-20240110-1202.zip
-
the settings are ok. Several reboots fixed the problem but that's strange. I may have a problem on my server. I had to reboot several times to have the server back online. My server is on the basement and i'm on the third floor. I don't have ipmi only intel amt which only permits reboot.
-
This night my unraid server crashed. This morning i couldn't access it nor with webgui nor with ssh. It only answered ping. So i had to hard reboot. When it came back online my NPM docker refused to start because port 80 is already in use. typing "netstat -tulpn | grep 80" tells me that unraid is listenning to port 80 with the same pid that used for webgui which is set to port 3080. Whenever i kill this pid it's started again and listen to port 80 and 3080. The process is nginx worker. I never had this problem before. Could this be a bug? edit: ihave this lines in syslog at the time of reboot: 10:43:47 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 127.0.0.1:3080 failed (98: Address already in use) Jan 4 10:43:47 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 192.168.178.50:3080 failed (98: Address already in use) Jan 4 10:43:47 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 127.0.0.1:3080 failed (98: Address already in use) Jan 4 10:43:47 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 192.168.178.50:3080 failed (98: Address already in use) Jan 4 10:43:48 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 127.0.0.1:3080 failed (98: Address already in use) Jan 4 10:43:48 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 192.168.178.50:3080 failed (98: Address already in use) Jan 4 10:43:48 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 127.0.0.1:3080 failed (98: Address already in use) Jan 4 10:43:48 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 192.168.178.50:3080 failed (98: Address already in use) Jan 4 10:43:49 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 127.0.0.1:3080 failed (98: Address already in use) Jan 4 10:43:49 godzilla nginx: 2024/01/04 10:43:47 [emerg] 15223#15223: bind() to 192.168.178.50:3080 failed (98: Address already in use) but webgui is accessible trough port 80 edit2: the webgui is also accessible trough port 80. i don't understand what's happenning.
-
I will try that. I often a tab open with unraid gui.
-
All was running fine and suddenly i had to reboot twice in 2 days because log was getting full. errors logged are the same as in this topic. godzilla-diagnostics-20231220-1149.zip edit: i suspect plugin folder view. I deleted it. will see
-
trying to upgrade from 6.12.4 and stuck on "trying to unmount disk share target is busy" docker daemon is stopped; all vm are stopped no file open on the disk share the share is on a 2 ssd btrfs pool. fuser tells me there is no process using the disk share. godzilla-diagnostics-20231204-1101.zip edit: libvirt.img is still mounted edit2: umount /etc/libvirt solved it
-
thank you it worked. 😀 Parity check has been triggered. I'll wait for the end and i will manually clear the drive.
-
I was trying to shrink array with the clear-me script. I think i forgot to update the script and it throws an error (i think it try to write zero to md3 instead of md3p1) As stated in the log i tried to stop array but it's impossible an now unraid is stalled in the retry unmounting disk share loop. It tries to unmount disk3 which is not mounted. What should i do ? godzilla-diagnostics-20231019-1204.zip
-
deleted docker.cfg, network.cfg and rebooted. custom docker network eth0 with macvlan driver, ipv6 enabled and parent interface vhost0 get created upon reboot. I had to set up docker parameters and it started correctly. I'm on the way to try to enable ipv6 on my entire network. Until now i had ignored ipv6 but now i'm trying to understand how it works and how i can use it.
-
i've been able to create a custom docker network with macvlan but ipv6 is not enabled for it. Can i delete network.cfg and docker.cfg ?

