




caplam
Members
-
Joined
-
Last visited
Everything posted by caplam
-
Last month my 9207-8e died. I received it's replacement : LSI 9400-8e It seems files available to update it have changed. updating firmware seems to be done with storcli utility. Can it be donne with unraid ? here are the rel notes for the packages i can download for latest version P24 *********************************************************************************************************************** Package for SAS3.5 Phase 24 Firmware BIOS UEFI ************************************************************************************************************************ LSI Host Bus Adapter(HBA) - LSI SAS9400_8e Package Contents- Readme first note : README_9400_8e_Pkg_P24_SAS_SATA_FW_BIOS_UEFI.txt Component : Path Version Release Date ============================================================================================================================================ Firmware : \Firmware\HBA_9400-8e_SAS_SATA_Profile.bin 24.00.00.00 25-JULY-22 BIOS : \SAS35BIOS_Rel\mpt35sas_legacy.rom 09.47.00.00 09-JULY-22 Readme for BIOS : \SAS35BIOS_Rel\ReadMe_MPT35SAS_BIOS.txt NA NA UEFI BSD Signed : \UEFI_BSD_HII_SAS3.5_IT\Signed\mpt35sas_x64.rom 24.00.00.00 08-JULY-22 UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\mpt35sas_x64.rom 24.00.00.00 08-JULY-22 Driver Sign Info for UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\DriverSignInfo.txt NA NA Readme for UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\readme_SAS3.5_UEFI_BSD_HII_X64.txt NA NA UEFI BSD Signed : \UEFI_BSD_HII_SAS3.5_IT\Signed\mpt35sas_ARM.rom 24.00.00.00 08-JULY-22 UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\mpt35sas_ARM.rom 24.00.00.00 08-JULY-22 Driver Sign Info for UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\DriverSignInfo.txt NA NA Readme for UEFI BSD : \UEFI_BSD_HII_SAS3.5_IT\readme_SAS3.5_UEFI_BSD_HII_ARM.txt NA NA -------------------------------------------------------------------------------------------------------------------------------------------- Note: Please use STORCLI utility for flashing the firmware which is posted under "Management Software and Tools" section. I suppose i only need the bin file for it mode. and for the storcli package: ********************************************************* Broadcom SAS3.5 StorCLI Utility ********************************************************* Supported Controllers: SAS3004 SAS3008 SAS3108_1 SAS3108_2 SAS3108_3 SAS3108_4 SAS3108_5 SAS3108_6 SAS3216 SAS3224 SAS3316_1 SAS3316_2 SAS3316_3 SAS3316_4 SAS3324_1 SAS3324_2 SAS3324_3 SAS3324_4 STORCLI utility for LSI SAS3.5 Controllers is designed to run from a host. Phase 24 GCA Release Version 007.2307.0000.0000 Release Date : 22-JULY-22 Package contains binaries for Windows x86/x64, Linux x86/x64/PPC64/ARM, EFI, FreeBSD x86/x64 Release Notes: MR_SAS_Unified_StorCLI-v007.2307.0000.0000 pdf binaries in the package are: Description: =========== This is a StorCLI readme file mentioning instructions to use: 1. StorCLI on all the supported operating systems. 2. StorCLI's JSON Schema files. 3. StorCLI's logging feature. Please read before you start using StorCLI executable. Privileges: ========= 1. StorCLI should be installed / executed with administrative / root / super user privileges. 2. Installed/Execution location should have Read/Write/Execute permissions. Windows: ======== Installation / Execution: 1. StorCLI is a executable. Copy-Paste the executable from where you want to execute. Sign verification: command : signtool.exe verify /v /pa <storcli executable name> Notes: 1. signtool.exe is required to validate the StorCLI's signature. Windows-ARM ============ Installation / Execution: 1. StorCLI is a executable. Copy-Paste the executable from where you want to execute. Linux: ====== Installation / Execution : 1. Unzip the StorCLI package. 2. To install the StorCLI RPM, run the rpm -ivh <StorCLI-x.xx-x.noarch.rpm> command. 3. To upgrade the StorCLI RPM, run the rpm -Uvh <StorCLI-x.xx-x.noarch.rpm> command. StorCLI RPM Verification: 1. Import the public key to RPM DB. Command : rpm --import <public-key.asc> 2. Verify the RPM signature. Command : rpm -Kv <storcli-rpm> 3. Install the StorCLI RPM. If imported public key is for the RPM being installed, No warnings should be shown during installation. 4. Please adhere to the steps in the above mentioned order only. Linux-ARM: ========== Installation / Execution : 1. Unzip the StorCLI package. 2. To install the StorCLI RPM, run the rpm -ivh <StorCLI-x.xx-x.aarch64.rpm> command. 3. To upgrade the StorCLI RPM, run the rpm -Uvh <StorCLI-x.xx-x.aarch64.rpm> command. VMware: ====== Installation: 1. The StorCLI VIB Package can be installed using the following syntax : esxcli software vib install -v=<Filepath of the StorCLI VIB> 2. The installed VIB Package can be removed using the following syntax : esxcli software vib remove -n=<VIB Name of StorCLI> 3. All the installed VIB Packages can be listed using following command: esxcli software vib list Notes : 1. VIB under directory "VMwareOP" : This binary is for versions from ESXi6.0 to ESXi6.7. 2. VIB under directory "VMwareOP64" : This binary is for versions from ESXi7.0 and later. FreeBSD: ======== Installation / Execution: 1. Extract the tar archive and execute the StorCLI. Usage policies / Privileges: 1. StorCli or StorCli64 application will not function if the user is trying to run it in CSH, the default shell in FreeBSD. 2. Please ensure that the user has entered the bash shell by executing the command "bash". EFI: ==== Installation / Execution: 1. From the boot menu, choose EFI Shell. 2. Goto the folder containing the StorCLI EFI binaries. 3. Execute StorCLI binaries. EFI-ARM: ======== Installation / Execution: 1. From the boot menu, choose EFI Shell. 2. Goto the folder containing the StorCLI EFI binaries. 3. Execute StorCLI binaries. Ubuntu: ======= Installation: 1. Debian package can be installed using following command syntax : sudo dpkg -i <.deb package> 2. Installed debian package can be verified using following command syntax : dpkg -l | grep -i storcli PowerPC: ======= Open Power Big Endian Distribution: ----------------------------------- Installation / Execution: 1. Unzip the StorCLI package and execute the storcli binary. Open Power Little Endian Distribution: ----------------------------------- Installation / Execution: 1. Unzip the StorCLI package and execute the storcli binary. 2. To install .deb package,Use "dpkg" command. JSON-Schema: ============= Installation: 1. Create a folder under /home/JSON-SCHEMA-FILES. 2. Unzip the JSON-SCHEMA-FILES.zip and copy all the schema files to /home/JSON-SCHEMA-FILES (In any of the operating systems). Command to Schema mapping: 1. Please refer to the Schema_mapping_list.xlsx for command to schema mapping. Logging: ======== 1. While executing StorCLI, Logging is enabled by default. 2. To Turn-off the logging, Place the storcliconf.ini in the current directory and change the DEBUGLEVEL to 0. 3. To change the log level, Place the storcliconf.ini in the current directory and change the DEBUGLEVEL to any desired log level. 4. In case of application crash, Place the storcliconf.ini in the current directory to capture logs. I booted with the hba. It's seen by unraid and so are the disks. But i'd like to verify firmware version and upgrade if needed. I would also like to remove mpt rom edit: i guess i have to go with efi. My server is a hp Z620. As far as i know it's booting in legacy mode for now. Can it boot unraid in efi ? I have no experience with efi. If i understand correctly, i have to : - make a bootable efi boot disk and place storcli.efi and bin file on the disk -disable legacy boot and change boot order to efi disk.
-
Unfortunately, i don't have room for that all the pcie slots are occupied.
-
do you think dell tg93gd would suit in my hp z620 ? It's the only one i found with bigger heatsink.
-
Without the hba the server boots normally. I tried another pcie port for the hba but no luck. I repasted the hba chip as the pad was completly dried but it still doesn't boot. There has been no hardware or software changes. What a dead cmos battery would do ? Is there a way to reflash the hba ? I will probably buy another hba. Any recommendations for a hba which doesn't heat too much ? I have a 9300-8e in my main server and it heats up quite a lot.
-
Hello, This morning i wanted to start my backup server. As i did not seen it on the network i plug a monitor and a keyboard. First image is when i do nothing. The second is when i hit keyboard at startup. If you have an idea of what is wrong.... edit: it boots when i unplug lsi hba (9207-8e). I modified some bios settings and it wasn't booting at all. After a clear cmos it booted but as soon as i plug the hba i have the weird display. Do you think the hba is dead ? It is the same hba since the setup of the server 5 years ago. It has 20.000.07 it firmware if i remember correctly and has not been reflashed since.
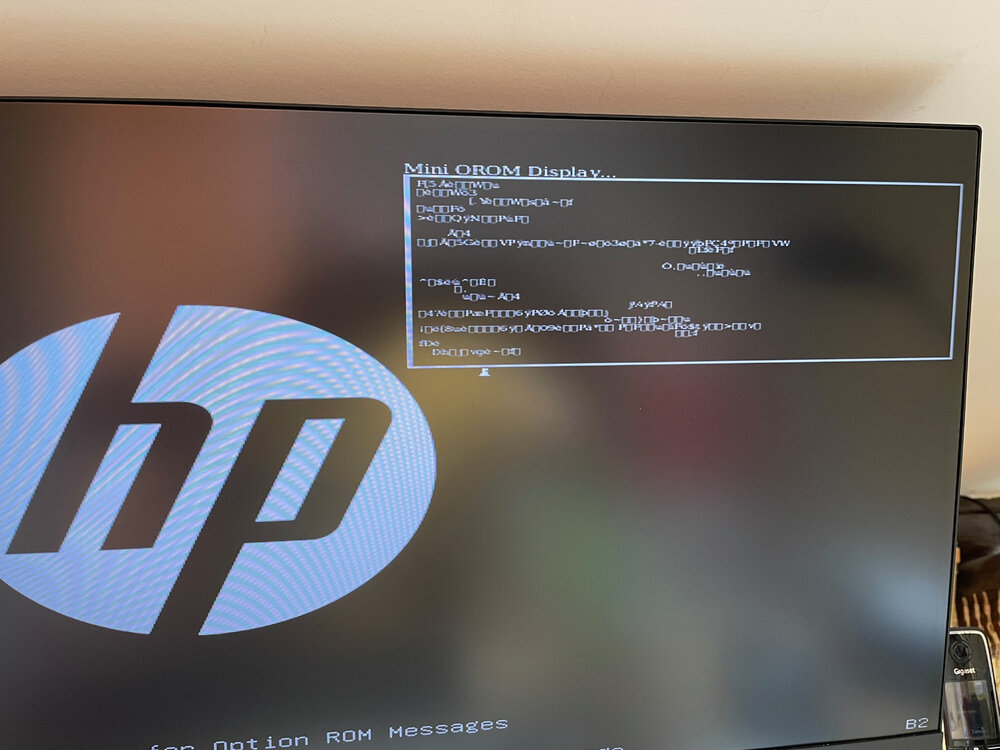

-
if they are flashed with genuine lsi firmware that should not interfere. Perhaps you should try to connect one port at a time. How long are your sas cables ?
-
You should provide more details (diagnostics, expander model, hba). Are the drives visible in bios? If only sata drives are not detected that suggest a cabling issue (multipath) Since you have both sas and sata drives do you have interposer on sata drives?
-
I backup all my things to a share except media files of the array. Then i backup that share to another unraid server with luckybackup. Since luckybackup is based on rsync i guess you could do the same to backup to synology. I also use luckybackup to backup certains media files. For the first backup ( to a share) i use several apps depending on the data to be saved: - appdatabackup for docker appdata and flash backup - home assistant samba backup - borg backup included in nextcloud aio - and soon a backup of a remote proxmox server synced with proxmox backup server I found easier to centralize all backups to a share and then rsync that share to another server. For vm i use easybackup. I wait for unraid 7 to reevaluate that point.
-
i manage networks, servers and home automation for family members. It would be convenient to connect these networks to have easier way to connect to servers, backup the different servers on mine. My unraid is behind an unifi dream router. I have one remote network managed by a freebox server (delta model). Another network has an asus router (xd6) (in dmz of a livebox) I have wireguard access to remote networks from my phone and my macbook. I'd like to go further and setup lan to lan access for the 2 remote networks with split tunnel. On the freebox server i can setup vpn client (pptp, wireguard, openvpn) and server ( pptp, wireguard open vpn routed or bridged and ipsec ikev2) On the unifi i can setup vpn server (openvpn, wireguard or l2tp), client (wireguard or openvpn) and site2site (openvpn or ipsec) On the asus i can setup vpn server (pptp, openvpn, ipsec or wireguard) and fusion which i think is client (pptp, l2tp, openvpn, wireguard and surfshark) So far i tried to connect unifi with asus without success. I wonder if i could use unraid (behind unifi ) as a hub for lan to lan access for the 2 remote lans. Behind asus xd6 i have a proxmox host. Could you give me hint for the best way to setup tunnels. I'd rather that only traffic for remote lan goes trough tunnel.
-
i have the same situation. Try to connect with "connect to server " from "go" menu of the finder.
-
out of idea for now. It seems your 10G interface is not active. Did you try to reboot ? I'd try with default parameters (mtu 1500, duplex auto, speed auto ...) for both 10G interfaces.
-
there is something strange you have no ipv4 (except localhost) in routing table. can you ping any other ipv4 on your lan ?
-
type ifconfig to see if your 10G interface is up. and netstat -nr to see routing table
-
it happens quite often on my server. You can check the last post of this topic or alternatively these 2 commands work on my server: /etc/rc.d/rc.nginx stop /etc/rc.d/rc.nginx start
-
i would reboot first. I often have a problem with gui frozen and docker &vm running normally. I have seen some posts suggesting reloading or restarting nginx (doesn't work for me ). What is working in my case is stopping and starting nginx trough ssh.
-
sorry i didn't pay attention to gt1030 capabilities. For your ssd you shouldn't had to "clear" it before use unless you added it to array and that's not appropriate. I suggest you read the docs as your choices in setting up storage devices will deeply affect the way you can use your server. And for the usb key 2.0 is fine, you won't gain anything with 3.0 but i think 4GB is too small. If i remember correctly the recommendation is usb2.0, a size between 8 and 32 GB and of course a good and robust key.
-
Web gui is fine. Don't forget to take a flash backup before proceeding. I don't know if it's useful for others but i took the habit to deactivate automatic startup of array.
-
i don't know if i get the way you installed unraid. Unraid has to be installed on usb stick; For now it has to have at least 1 drive in array. In my precedent post i assumed you have an array (probably on spinning drive). If you have no ssd involved in your unraid setup you'll probably need one. But we have no idea on what you installed (except plex) If you more detailed answers you'll need to provide diagnostics.
-
from what i see you are using /mnt/user as transcode path which is located on your array (probably spinning drives). you should use a ssd (/mnt/user/cache/plex-transcode)for that path or ram (/tmp/plex-transcode) if you have enough. Your problem doesn't seem related to gpu as it's used.
-
I'm using this script for a while now and completly forgot to update it. Still using the version 1.4 with unraid 6.12.11 and i have no errors in logs.
-
Are the snapshots provided by qcow2 format attributes or by underlying filesystem ? Is there a way to export snapshot to backup vm ? I'm glad editing a vm is now done fully in gui. We can now expect there is no more bug when switching between gui and xml like vdisk type switching from qcow2 to img.
-
i rebooted and parity sync started from scratch. No more read errors. Smart attributes are fine. I wonder if i could have caused that when closing the case. edit: i forgot to enable syslog on backup server. I changed that. I now use my main server as syslog server. z620-diagnostics-20240702-1848.zip
-
It's my backup server. it was running with 8 disks without parity. Today i added a parity disk and during parity sync it started throwing read errors on disk5. I tried to cancel parity with no luck. i see reads (150MB/S) on disks 1,2,3,4,6,7,8 and nothing on parity and disk5. disk 5 is sdg and in attributes i have: - Smartctl open device /dev/sdg failed all disks are btrfs formatted. edit: disk5 also appear as sdk under unassigned devices z620-diagnostics-20240702-1801.zip
-
i'm also using a ms-01 with no major trouble. I have 2x32GB ram. I used to have troubles until using external fans. MS-01 is heating a lot if you are using it without additional fan with turbo boost on or with a pcie add-in card. I can suggest to monitor temp (cpu and ssd) and put a 120mm or 140mm blowing fan underneath and a 80mm above. You can find more details on serve the home There are also other threads about comaptibility
-
you can set this with docker restart policy. you can add the --restart unless-stopped (or --restart always) into the extra parameters section of the template (in advanced view).

