





SolidFyre
Members
-
Joined
-
Last visited
Everything posted by SolidFyre
-
Thanks @bmartino1. I think I managed to solve it eventually. What I did was: 1. Disable/remove my empty cache sata ssd 2. Populate the other M.2 slot with another 1TB Nvme 3. Make a pool of the new drive. 4. Configure Default appdata path in docker settings 5. Move Plex, Docker image, appdata, VM folder to new pool drive 6. Clear old Nvme and add it to the pool in a Raid 1 config 7. Setting all Docker/VM shares to default appdata path and pool as primary storage 8. Unbalance Gather everything into /mnt/user/appdata on pool 9. Removed link /mnt/user/appdata/appdata as it was pointing to the old nvme that is now in the pool. 10. Prayed... Still testing, but it seems to work as intended now.
-
Hi, I'm in a bit of a pickle that I don't know how to get out of. Kinda wish I could go back to initial default docker config or perhaps do clean install of Unraid and restart from scratch. Not sure if that's an option at this point. I don't even know how to explain my problem... Some years ago I had an issue with permissions in the appdata folder which I "solved" by not using the default path /mnt/user/appdata (maybe because of the cache) but instead used the direct path to my nvme drive (/disks/Samsung_SSD_970_EVO_Plus_1TB_S4EWNF0M532569N/Docker/appdata), wich probably was a stupid fix but it worked at the time. Now, as I am spring cleaning on the server, I would like to migrate everything to the correct location, but I am getting confused by the multiple appdata folders that exists on the system now for some reason. Some are probably links, virtual or direct paths? Anyway, as I did a migration today, to what I though was the correct folder (/mnt/user/appdata), got everything up and running and then ran the common errors scan and got this: - Default docker appdata location is not a cache-only share - Invalid folder appdata contained within /mnt As I check the shares it seems the appdata is now spread across multiple drives in the array instead. I have a cache drive designated (a 256gb sata ssd), but I don't really want to use it for docker purposes as I feel it adds a layer of complexity and confusion that I don't need. I am not sure why docker started using the cache as it was not setup to use it from the beginning. It was only supposed to be used as a cache for the array at the initial copy from the older server over the network. So, what I would like to do is, 1. I would like all "Appdata" to run directly from my nvme (the samsung above) where my docker.img is located, and the mount point /mnt/user/appdata to be pointing towards that folder and not the cache as it seems to be doing now, since the cache drive is considerably slower and less reliable. 2. I would like to remove the cache from the system completely, as I don't really need it, and it just adds confusion for me in the folder structure. The folders I have now is "/mnt/appdata" <-- shows everything that I copied to /mnt/user/appdata but is now spread all across the array. I have no memory of ever creating this folder. "/mnt/user/appdata" <- Where I copied everything to from the bellow folder, hoping everthing would be ok, which spread everything across the array, probably because the cache settings were set to "array". So this folder seems to be on the cache drive somehow? "/mnt/user/appdata/appdata" <- link to "/disks/Samsung_SSD_970_EVO_Plus_1TB_S4EWNF0M532569N/Docker/appdata" which I have been using as the "fix" and my default docker template appdata install directory. I don't even know where to start to fix this. What I am thinking of doing right now is either, - Copy everything to "/disks/Samsung_SSD_970_EVO_Plus_1TB_S4EWNF0M532569N/Docker/appdata" and then somehow go from there to restore the link "/mnt/user/appdata" to that folder. Or - Copy all appdata to an external drive, deleting all appdata folders and redoing the whole docker config again somehow. Also want to make sure the cache is not invovled ever again. Not sure if any of the above are the correct approaches and how not to get the cache mixed up in this all over again. Any idea's are welcome. Thanks.
-
The Matrix unraid template seems to need a bit of love, or I am doing something wrong, but I can't get it deployed. First run only creates the appdata folder, and then errors out and kills the container. So I do the chown 991:991 on the folder and then the next run I get 4 files, but all the subfolders errors out with permission errors instead for some reason. socket: Protocol not supported socket: Protocol not supported socket: Protocol not supported socket: Protocol not supported Traceback (most recent call last): File "<frozen runpy>", line 198, in _run_module_as_main File "<frozen runpy>", line 88, in _run_code File "/matrix/venv/lib/python3.13/site-packages/synapse/app/homeserver.py", line 419, in <module> main() ~~~~^^ File "/matrix/venv/lib/python3.13/site-packages/synapse/app/homeserver.py", line 409, in main hs = setup(sys.argv[1:]) File "/matrix/venv/lib/python3.13/site-packages/synapse/app/homeserver.py", line 318, in setup config = HomeServerConfig.load_or_generate_config( "Synapse Homeserver", config_options ) File "/matrix/venv/lib/python3.13/site-packages/synapse/config/_base.py", line 841, in load_or_generate_config obj.parse_config_dict( ~~~~~~~~~~~~~~~~~~~~~^ config_dict, ^^^^^^^^^^^^ ...<2 lines>... allow_secrets_in_config=config_args.secrets_in_config, ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ) ^ File "/matrix/venv/lib/python3.13/site-packages/synapse/config/_base.py", line 869, in parse_config_dict self.invoke_all( ~~~~~~~~~~~~~~~^ "read_config", ^^^^^^^^^^^^^^ ...<3 lines>... allow_secrets_in_config=allow_secrets_in_config, ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ) ^ File "/matrix/venv/lib/python3.13/site-packages/synapse/config/_base.py", line 443, in invoke_all res[config_class.section] = getattr(config, func_name)(*args, **kwargs) ~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^ File "/matrix/venv/lib/python3.13/site-packages/synapse/config/repository.py", line 157, in read_config self.media_store_path = self.ensure_directory( ~~~~~~~~~~~~~~~~~~~~~^ config.get("media_store_path", "media_store") ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ) ^ File "/matrix/venv/lib/python3.13/site-packages/synapse/config/_base.py", line 292, in ensure_directory os.makedirs(dir_path, exist_ok=True) ~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^ File "<frozen os>", line 227, in makedirs PermissionError: [Errno 13] Permission denied: '/media_store' These are the only files I get:

-
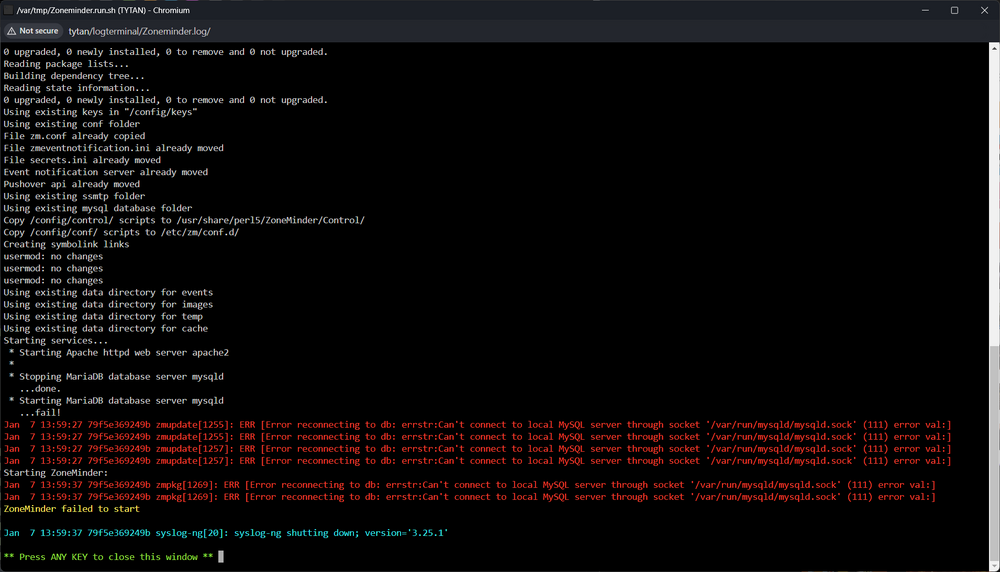
So, it appears lots of tables in InnoDB got corrupted somehow. I found clues in /var/log/mysql/error.log I tried to force an InnoDB recovery but never got it to work. Instead I bypassed InnoDB by skipping it using "skip-innodb" and "default-storage-engine = myisam" under [mysqld] in my.cf and mysql finally starts, however, is seems ZoneMinder is reliant on InnoDB and wont start because of it. I guess it's possible to do a backup now since mysql is started, but I will instead just try and delete the whole thing and reinstall from scratch since my ZM install isn't that big. Edit: My issue is solved. I deleted /appdata/ZoneMinder/mysql in the docker image and redeployed and now everything starts fine.
-
Got the same problem over here. Tried force update and removing the container + image, no dice.
-
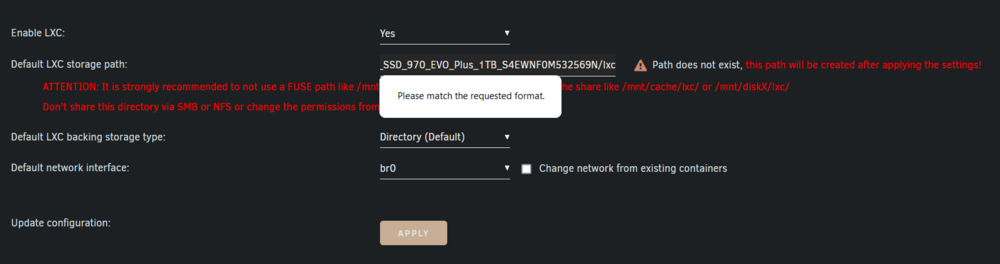
Is it possible to have the lxc path set to something else than the cache or the array? I am trying to put it on a separate nvme that I use for all my docker containers and it doesn't accept the path. /mnt/disks/Samsung_SSD_970_EVO_Plus_1TB_S4EWNF0M532569N/lxc
-
Ah, alright. Guess I have to bite the bullet and migrate all my containers to the "correct" path then. uhh.... Thanks
-
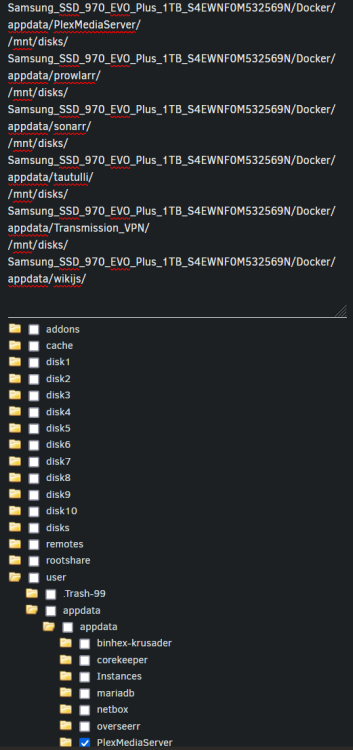
Tried to set it several times, but it reverts to absolute path and then regards it as "external path", and as a result it skips it completely unless I explicit set it to backup external paths further down. Right now it's only backing up the template settings. Is it fetching these paths from the container settings even though I explicitly tells it to target these folders?
-
@KluthR Whenever I try to change my source directories to my actual "internal appdata path" it changes back automatically to the absolute path regarded as "external" by the plugin (/mnt/disks/XXXXX/docker/appdata). is it possible to somehow change whats regarded as being "internal" path? All my appdata is regarded as external paths since I setup my server at a time when I had a weird bug with the appdata folder access rights, so I am using another path (/mnt/user/appdata/appdata). Stupid yes, but it was the only way I managed to solve it at the time. I could use "external paths" but then it backs up stuff I don't want, like the external transcode directory for plex etc. Otherwise I would need to migrate all my 38 containers back to the default appdata path 😅
-
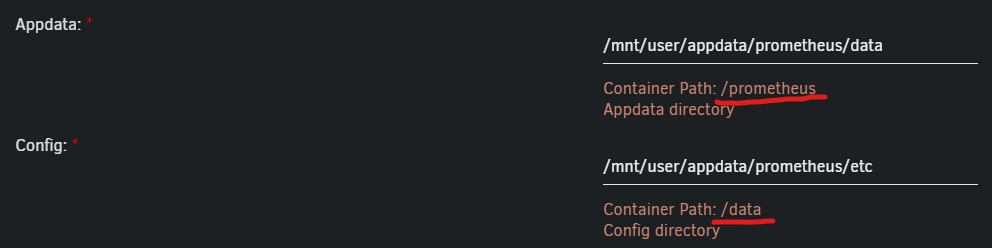
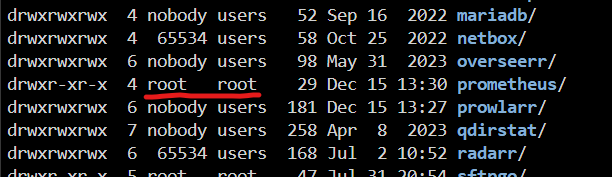
@Kilrah @Rusty6285 Not sure if I am late to the party but, I had issues deploying Prometheus and managed to fix the broken template and got it running. I saw that you had issues in September and maybe you fixed it by now. Appears the template is still not updated though. I identified two issues with it. 1. The mappings to the yml file is indeed wrong. The correct Docker path for the config should be "/data". 2. For some reason (at least for me) the appdata folder for Prometheus installs with owner root:root:, which is incorrect and hinders it from starting. Viewing the log shows denied permissions etc. Should be changed to "users" group and your user uid. Example: "chown -R 65534:users prometheus/" And its up! Might be more to fix to get it completely up, for example chmod the appdata folder with correct attributes etc, but at least it's running. Cheers 🍻
-
The sas/sata cables are completely new, so they should be fine. I have also ordered new sata power cables as well, will try and reintroduce the drive again whenever they arrive. Thanks for the help guys
-
So I got a new drive, popped it in and rebuilt the array just fine. I took the "broken drive" and hooked it up using USB and went through a complete Pre-clear of the drive without a single issue (drive: sdn). Here's a new log collection, the 2459 CRC errors reported by SMART are the ones I got before the disk was rejected by the Array and I took it out. What to make of this? Can I reintroduce the drive to the array again? 🤔 tytan-diagnostics-20220930-2013.zip
-
Switching around cables doesn't seem to help the issue. I have a new drive arriving tonight. Will replace drive and do some diagnostics on it.
-
Here's the diagnostics after reboot. The SAS/Sata cables are new because I replaced them this summer due to read errors and I had 2 cables not connected, so I switched out the one to the broken drive. I am hearing some very worrisome sounds coming from it though, clicking on boot and other... tytan-diagnostics-20220927-0735.zip
-
Ah, here you go tytan-diagnostics-20220927-0017.zip
-
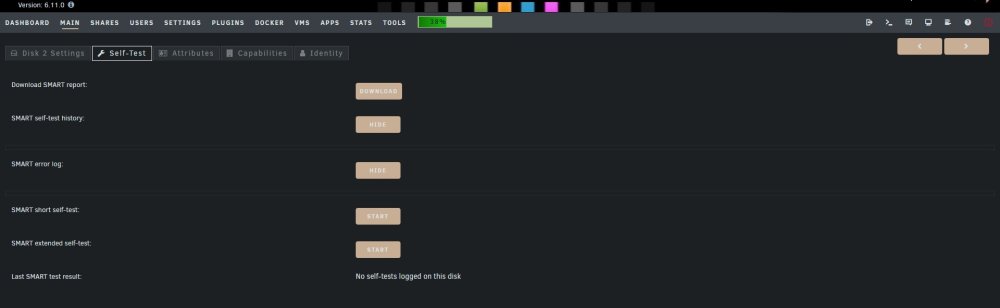
Hello, I am having problems with one of my drives and is looking for some moral support... I got about 50 read errors and thought it was a good idea to run a Smart Self Test. First Short Self Test went fine, no errors, then I did an extended test because this drive has been having temper tantrums before. After about 5 min it got 1074 read errors and the drive was automatically Disabled. Now it's frozen. In the Self Test tab "latest smart test" is just spinning/loading. When I try to download the logs I get a blank file, so I cannot really provide you guys with logs. History and Smart Error Log buttons show nothing either. The other tabs show no information. Nothing happens when I try to Spin Down the drive. Not sure what to do now, what would be my next step here? Should I consider the drive done? I am currently looking online to find a new drive.



-
The config instruction of the Unraid docker image for 'cloudflare-ddns' should probably be updated. It's not possible to use both 'Email Variable' and 'API Key' variable at the same time, it won't start. It will simply say "Invalid Cloudflare Credentials" in the log and then kill all processes. In order to use the API Key variable the Email variable needs to be deleted, it seems.
-
Can confirm, container template for some reason changed to 0 on Public Server.....
-
Thanks, I tried to put it in code field to minimize bloat, apparently that didn't work. Yea, tried 5 characters for password, didn't work. Appears the minimum is 6 characters, no digits. Now it starts flawlessly every time. Thanks for pointing me in the right direction, been banging my head against the wall for hours Maybe update that instruction to 6 instead of 5.
-
Trying to deploy a Valheim server. I have no idea what is going on with steamCMD but why is totally hammering the Steam servers to the point where I get temp banned from steam due to excessive logins from my network?? It's doing multiple logins at the same time and just loops until I shutdown the container. Anyone? valheim.log
-
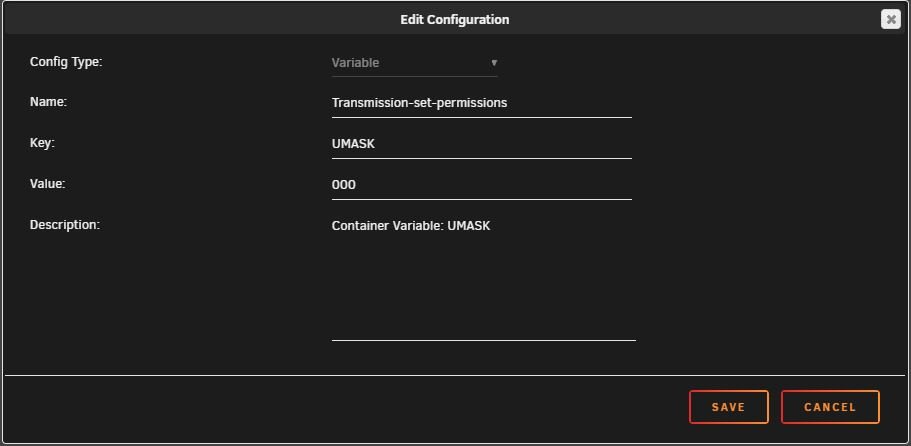
I solved it. I put the JSON through a JSON Position finder online and it whined about my umask settings. 000 which has worked fine for about a year now turned up as "undefiend". So I changed "umask": 000, to "umask": 0, I guess they changed what is expected input on this variable. 😒
-
Haven't touched my container for at least a year now and suddenly last update broke it, anyone else? It doesn't seem to like my JSON anymore, not sure why. I tried changing every entry that starts with "upload-" as it is the only clue in the log, but still nothing Did they change some variables or something? ------------------------------------- Transmission will run as ------------------------------------- User name: abc User uid: 99 User gid: 100 ------------------------------------- STARTING TRANSMISSION CONFIGURING PORT FORWARDING Transmission startup script complete. Wait for tunnel to be fully initialized and PIA is ready to give us a port Thu May 28 18:48:03 2020 Initialization Sequence Completed [2020-05-28 16:48:03.899] JSON parse failed in /data/transmission-home/settings.json at pos 2184: INVALID_NUMBER -- remaining text "00, "upload-" Generating new client id for PIA Got new port 36284 from PIA transmission auth not required waiting for transmission to become responsive [2020-05-28 16:48:19.652] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:48:29.661] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:48:39.670] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:48:49.679] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:48:59.688] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:49:09.697] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:49:19.705] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server [2020-05-28 16:49:29.714] transmission-remote: (http://localhost:9091/transmission/rpc/) Couldn't connect to server
-
Yea, those lists. Problem solves itself by using the "Safe docker permissions" thingy, but as soon as I download something new the rights gets broken. Hmm, well it seems that I was correct using TRANSMISSION_UMASK as I did at the start, I have now switched back, will try with some small downloads. What I have read, 000 is the same as 777 so I am going back to this to try again, maybe I missed something. Thanks, will report back my findings.
-
Hi! I'm having an issue with the Transmission_VPN docker image regarding the UMASK settings that is driving me nuts. Hopefully someone could nudge me in the right direction. I am unsure of the correct variable name, according to some variable chart I found all variables are "TRANSMISSION_WHATEVER" (which worked for all other variables I have set), however that did not seem to work for umask so I switched to just "UMASK" as variable, but still can't get it to work. For some reason I get this in the download folder: Topfolder = drwxrwxr-x 1 nobody users - Can't edit Subfolder = drwxrwxr-x 1 nobody users - Can edit Files = -rw-rw-r-- 1 nobody users - Can edit (and execute...?) How come the same rights, topfolder and subfolder behave differently when browsing samba? Download folder is accessed using a unraid user with R/W access (private samba share), are these settings interfering? Whats the correct variable and setting to use to have it set 777 (or at least 775) on all folders and files? Right now I have the settings like this:
-
Thanks, I will give it a try when I get the chance














