jmztaylor
Members
-
Joined
-
Last visited
Everything posted by jmztaylor
-
Hardware: https://www.tcl.com/us/en/products/home-theater/5-series/75-class-5-series-4k-qled-hdr-smart-roku-tv-75s535 https://www.lg.com/us/sound-bars/lg-s75qr-sound-bar https://www.amazon.com/gp/product/B07WNM2NJ5/ref=ppx_yo_dt_b_search_asin_title?ie=UTF8&th=1 Nvidia Shield I have the Shield hooked up to the TV using the monoprice cable linked above. The TV is hooked up via the same cable through earc to the soundbar. Shield is hardwired via ethernet Plex is always playing via direct play so transcoding is not happening. Randomly, the audio cuts out for about 5 secs and the display on the sound bar makes it seem like the audio format was changed by displaying HDMI and then displaying Dolby Atmos. It is random and doesn't happen in the same spot again. So if it happens and I rewind to that spot again it doesn't happen. Its always random. Unfortunately, I have no other dolby compatible devices to try somewhere else. Any help with diag on this issue would be helpful. I am completely out of ideas with Dolby. General Unique ID : Complete name : Format : Matroska Format version : Version 4 File size : 50.0 GiB Duration : 2 h 22 min Overall bit rate mode : Variable Overall bit rate : 50.2 Mb/s Frame rate : 23.976 FPS Movie name : Encoded date : 2020-04-01 11:19:41 UTC Writing application : mkvmerge v43.0.0 ('The Quartermaster') 64-bit Writing library : libebml v1.3.10 + libmatroska v1.5.2 Cover : Yes Attachments : small_cover.jpg / small_cover_land.jpg / cover.jpg / cover_land.jpg Video ID : 1 Format : HEVC Format/Info : High Efficiency Video Coding Format profile : Main [email protected]@High HDR format : SMPTE ST 2086, HDR10 compatible Codec ID : V_MPEGH/ISO/HEVC Duration : 2 h 22 min Bit rate : 41.9 Mb/s Width : 3 840 pixels Height : 2 160 pixels Display aspect ratio : 16:9 Frame rate mode : Constant Frame rate : 23.976 (24000/1001) FPS Color space : YUV Chroma subsampling : 4:2:0 (Type 2) Bit depth : 10 bits Bits/(Pixel*Frame) : 0.211 Stream size : 41.7 GiB (83%) Title : Writing library : ATEME Titan File 3.9.0 (4.9.0.0) Language : English Default : No Forced : No Color range : Limited Color primaries : BT.2020 Transfer characteristics : PQ Matrix coefficients : BT.2020 non-constant Mastering display color primaries : BT.2020 Mastering display luminance : min: 0.0001 cd/m2, max: 1000 cd/m2 Audio #1 ID : 2 Format : MLP FBA 16-ch Format/Info : Meridian Lossless Packing FBA with 16-channel presentation Commercial name : Dolby TrueHD with Dolby Atmos Codec ID : A_TRUEHD Duration : 2 h 22 min Bit rate mode : Variable Bit rate : 4 363 kb/s Maximum bit rate : 6 249 kb/s Channel(s) : 8 channels Channel layout : L R C LFE Ls Rs Lb Rb Sampling rate : 48.0 kHz Frame rate : 1 200.000 FPS (40 SPF) Compression mode : Lossless Stream size : 4.34 GiB (9%) Title : Language : English Default : Yes Forced : No Number of dynamic objects : 13 Bed channel count : 1 channel Bed channel configuration : LFE
-
Everything worked out with the pool after downgrading to 6.12.11. But array will no longer start on boot even though setting is yes. Even after upgrading back to 7.0.0-beta2 as I need Arc support. Would this be because I broke parity and it needs to be redone?
-
Its a btrfs pool
-
In the current state is there any risk to downgrade?
-
I stopped array, unassigned drive and restarted array. Waited for operations to finish then stopped array again, changed slots to 2 and couldn't start the array saying invalid expansion. I had to do a new disk config to get the array started with just the 2 cache drives again. tower-diagnostics-20240727-0938.zip
-
Attached is the log after running extended test. tower-smart-20240709-0946.zip
-
The other day I got errors on the array. Ran parity check and nothing was corrected. Woke up today and there are more errors. Just trying to find out the cause. Nothing has been changed or touched inside the machine. One drive is audibly heard, so it might be failing but wanted to get input before moving forward with anything. Server has not been rebooted since the first error appeared. tower-diagnostics-20240707-1041.zip
-
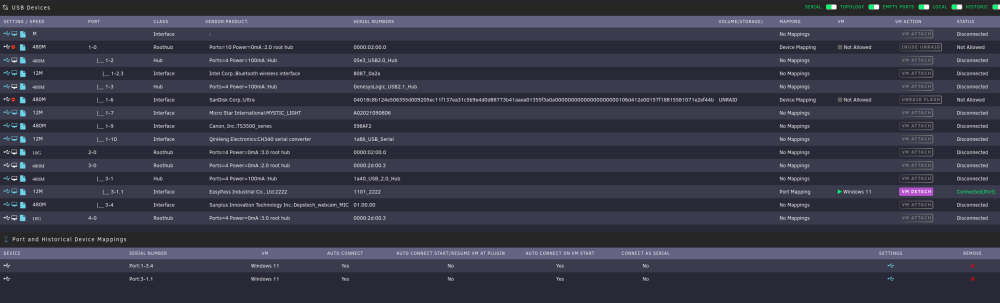
Ultimately, I think it comes down to just cheap usb hub and reusing device Ids or something. As using 2 of the same hubs, 1 always doesn't work but if i switch it out to another it works.
-
It works perfectly fine in all other scenarios. As unlikely as it is, is it possible since both hubs are identical its just breaking something internally?
-
Any tips on what to check?
-
Dmesg shows nothing at all when plugging the hub in. Or when plugging a device into the hub. But plugging the device into the same port the hub was plugged into, it shows up and functions normally.
-
I have a linux VM and passing through a USB controller. It is working fine with 1 USB hub. If I plug a second one in, nothing is detected. Either by the VM or Unraid. If I plug a device into that same port it is seen in the VM. Is this just a limitation with KVM or am I just missing something? tower-diagnostics-20240617-1932.zip
-
Yes please lock
-
Looking through my purchase history I was incorrect. Mine is a different chipset. This is the exact one I purchased and haven't had a single issue with it https://www.amazon.com/gp/product/B0BYXKPMBV/ref=ppx_yo_dt_b_search_asin_title?ie=UTF8&psc=1
-
I have this exact one and it works without issue. I do not know the tech specs of what is required. But I just checked and they do not show in my BIOS either. But they all show in Unraid without issue. I think I remember mine saying it cannot be used for boot devices. This is just my experience and it might not help you at all.
-
Sounds good. Thanks
-
Extended smart passed without issue and parity check ran without new errors. So I assume just a hiccup and good to go now? tower-diagnostics-20240302-1917.zip
-
Ok. I cancelled the one pending and started it from scratch. I will report back if anything new shows up
-
Parity never finished as its set to partially run overnight. Should I just continue it and see what happens at the end?
-
Parity check started and has some errors on the parity drive itself. Wanted to get input before doing anything. tower-diagnostics-20240301-0927.zip
-
I can confirm it is not showing like that anymore.
-
Why is this plugin showing up as blacklisted now?
-
Depends if you are using a controller presently or in the new server. Sometimes they modify the reported serial number. Take screenshot of current disk assignments with their serial numbers and slots. But in a perfect world yes, just swapping the drives over and the usb drive should just work. If Unraid detects anything strange with the drives in the new machine it won't start the array to prevent data loss. So it won't destroy anything if it doesn't detect the right drives.
-
This is deprecated in favor of @ich777 all in one solution.
-
So I did the port instead and it will not show up in the VM unless I stop and start the VM. Not sure why this one thing is being so odd with USB.