




shEiD
Members
-
Joined
-
Last visited
Everything posted by shEiD
-
@JorgeB The disk is in a NetApp DS4246 disk shelf, so no cables involved (per single disk) and I have already tried changing to another slot - did not help (same result/error and no SMART data).
-
Long story short - I've had a power outage while not adequately prepared. I wasn't able to shutdown my server in time and the UPS ran out of juice. The server and the NetApp DS4246 disk shelf got their power cut. The disk in question was in the disk shelf. When I powered on the server after power outage was over - I found one disk (located in the NetApp disk shelf) was missing from the array. That same disk was showing up in the Disk Devices list with format button. And it was not reporting any SMART data. Here's a snippet from the syslog related to this disk: Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3393 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3393 Sense Key : 0x3 [current] Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3393 ASC=0x11 ASCQ=0x0 Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3393 CDB: opcode=0x88 88 00 00 00 00 04 8c 3f ff 80 00 00 00 08 00 00 Jul 25 23:13:01 thePit kernel: blk_update_request: critical medium error, dev sdaa, sector 19532873600 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3394 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3394 Sense Key : 0x3 [current] Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3394 ASC=0x11 ASCQ=0x0 Jul 25 23:13:01 thePit kernel: sd 8:0:24:0: [sdaa] tag#3394 CDB: opcode=0x88 88 00 00 00 00 04 8c 3f ff 80 00 00 00 08 00 00 Jul 25 23:13:01 thePit kernel: blk_update_request: critical medium error, dev sdaa, sector 19532873600 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Jul 25 23:13:01 thePit kernel: Buffer I/O error on dev sdaa, logical block 2441609200, async page read Jul 25 23:14:02 thePit kernel: sd 8:0:24:0: [sdaa] tag#7063 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0sI tried only a couple of simple things - I restarted both the server and the disk shelf and tried swapping the disk to another slot in the shelf. That did not help. I did nothing else - I powered everything off until I had time to deal with it. I do not have/use parity on the array. I understand I have lost all the files on that disk if it's dead/borked for good. Questions: What happened to that disk? Why is it showing up like it's not dead, while not even reporting SMART data? If its only a borked filesystem problem, is there any XFS magic that can be used recover the files? Here's the diagnostics file: thepit-diagnostics-20260725-2206.zip Thanks in advance for any help.


-
running env $(cat /boot/config/plugins/unbalanced/unbalanced.env | xargs) /usr/local/emhttp/plugins/unbalanced/unbalanced --port 7090 gives /usr/local/emhttp/plugins/unbalanced/unbalanced: /lib64/libc.so.6: version `GLIBC_2.34' not found (required by /usr/local/emhttp/plugins/unbalanced/unbalanced)
-
Running the command above I get this: env: ‘/tmp/unbalanced’: No such file or directory
-
Help, please - unbalanced does not start at all 😢 Is there a minimum OS version, perhaps? I am running unRAID 6.10.3. I am reluctant to uninstall the older unBALANCE plugin (because it works), until I get this new plugin working... Or should I uninstall the older one?

-
@dlandon thank You, it worked.
-
Getting an error, when trying to update the plugin. plugin: updating: unassigned.devices.plg plugin: downloading: "https://raw.githubusercontent.com/dlandon/unassigned.devices/master/unassigned.devices-2023.08.17.tgz" ... done plugin: bad file MD5: /boot/config/plugins/unassigned.devices/unassigned.devices-2023.08.17.tgz
-
Nice and simple - love it. Never used reiserfs before 😀 I thought I'd mention me not using parity, because with parity you would need to zero out the disk?
-
I am using unRAID v6.10.3 My array is data disks only - NO PARITY. What would be the correct procedure to re-format array disks? I would love to be able to do it fast and simple: - stop the array - remove the disk from an array slot (it appears in the Unassigned Devices) - delete the partition with UD - put the disk back in it's array slot - start the array and hopefully the disk gets formatted 🤞 without zeroing out? Or do I need to do it long way round: - new config - remove disk - pre-clear - new config - add disk back - auto-format on array start (the usual unraid behavior when adding a new disk to the array)
-
How can I find out which array disks are actually formatted the "old" and "new" way? I mean, can I get that info without emptying the disks to see how much free space they take up "on empty". Also, what would be the easiest and fastest way to re-format the array disks using the "new" xfs format? I am constantly using hardlinks - I probably have tens of thousands of them on my array, and I am not 100% sure, but it seems, like I am getting way faster results when searching for hardlinks on the "newer" disks, than older ones. or am I just imagining this?
-
Just wanted to confirm, that this explains some pretty huge difference in used space on empty array disks. I emptied 3 identical 10 TB disks on my array and - 2 older ones have ~10GB used space, while the newest one has ~70GB. I assume, the 3rd disk was formatted with the newer version of xfs? Same with the newest 18TB drives, I guess? They all have 126GB used space freshly formatted, instead of ~18GB... Would very much appreciate, if anyone could confirm, that I'm understanding this correctly.
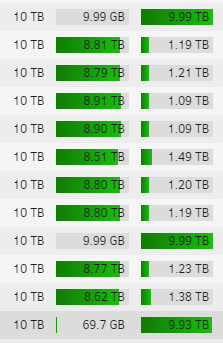

-
@trurl Thank You.
-
Does doing a New Config mean that all the settings, Docker containers and VMs will be gone? I mean, does New Config reset ONLY the disks (array/cache/pools), or does it reset everything? I need to replace 1 failing drive with a new one, and I do NOT have parity. Everything from the failing drive is already copied over to the new drive (rsync). And, no parity means there's nothing to rebuild. Preferably, I would love to simply swap the drives and keep all my setup intact...
-
It seems fio does not work... I only get "Illegal instruction" on any command. unRAID Version: 6.9.2 NerdPack Version: 2021.08.11
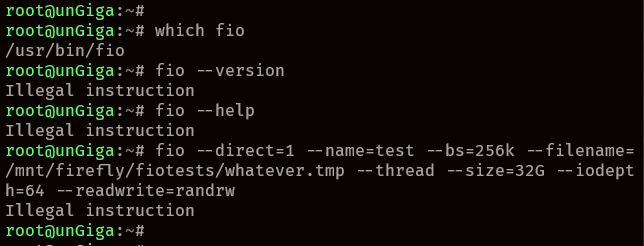
-
Yes, I have jq in my system, but I think I installed it with NerdPack, iirc. Or am I misremembering? I could swear, jq was in NerdPack before 🤔, but maybe I'm wrong... Does this mean, that now jq comes with unRAID as standard, so it was removed from NP?
-
Same here - jq is missing - has it been removed? Please, add it back 🙏
-
Here's the diagnostics with a running array. ungiga-diagnostics-20210904-0125.zip Although, I have already rebooted normally one more time, without starting the array - just to avoid the parity check. I mean I decided enough is enough - 2 parity checks in 2 days (0 errors), I feel 3rd time would be the same. There should have never actually been any writes to the array, when the server hanged... Sorry, if that messed up the diagnostics... did it? I actually thought, if you don't capture stuff before restart - all the info is useless anyways, as unraid is always loaded to memory and completely resets on reboot? Yep, that's how have set them, by using the units: from the smallest 3GB to the largest of 500GB. I usually tend to not fill any drives past 90% on my main server. And yes, on this backup server 500GB is normally way to much for 3TB drives, but meh - this was just temporary. This is as much a backup server, as it is a testing server. That's why I'm copying everything out to the main one. I want to create and properly test multiple btrfs cache pools using these drives. I would love sooooo much to use btrfs pools, if it wasn't so "anecdotally scary unreliable" and did not have so much warnings not to trust in it, all over the internets 😟
-
I had to force reboot to get the diagnostics. ungiga-diagnostics-20210903-2357.zip
-
My secondary/backup/testing server just "hanged" for a 3rd time in 2 days. This never happened before and it was working perfectly. I am in the process of copying all the files of that backup server (about 8-9TB) onto my main server. My plans was to copy in stages, one large folder (about 0.5TB - 1TB) at a time. All those 3 times the backup server "hanged" was during a large rsync transfer. At first everything was perfectly fine - I did 2 or 3 rsync transfers, about 1.2TB in total. I fired up another rsync and went to sleep. The next morning I noticed that the backup server has "hanged". My SSH session to the backup server was disconnected. WebUI was not working, I tried to ping it: Pinging 192.168.1.22 with 32 bytes of data: Reply from 192.168.1.11: Destination host unreachable. Reply from 192.168.1.11: Destination host unreachable. The monitor on the backup server showed black screen and keyboard did nothing. All I could think of at this time, was to force shutdown with a power button. I turned it off and on again. Server booted normally and did a parity check (~9 hours) - no errors. Although I had no idea what happened, I was happy that parity check returned with 0 errors. The only linux experience I had is unraid, so after a couple of hours of googling, all I could think of, was to setup remote syslog. So that's what I did. I've setup both of my unraid machines to act as a remote syslog server for each other, hoping this could help me to find out what was the problem. I fired up another rsync and went on with my day. A couple of hours into the transfer the backup server hanged again. Exactly the same - unresponsive and unreachable. I looked at the remote syslog - and did not see anything that explained what happened, at least to me (as linux illiterate as I am). Well, something weird - there was a ton of those share cache full messages, and it was the last message in the syslog before the backup server hanged: Sep 2 19:19:39 unGiga shfs: share cache full Sep 2 19:19:39 unGiga shfs: share cache full Sep 2 19:19:39 unGiga shfs: share cache full Sep 2 19:19:39 unGiga shfs: share cache full Sep 2 19:19:39 unGiga shfs: share cache full Sep 2 19:20:47 unGiga ool www[5686]: /usr/local/emhttp/plugins/recycle.bin/scripts/rc.recycle.bin 'empty' Sep 2 19:20:48 unGiga Recycle Bin: User: Recycle Bin has been emptied Sep 2 19:20:53 unGiga ool www[5810]: /usr/local/emhttp/plugins/recycle.bin/scripts/rc.recycle.bin 'clear' Sep 2 19:27:14 unGiga shfs: share cache full That did not help at all... My cache pool on backup server was actually pretty empty. Again, I did some googling. And again, I forced-turned-off my backup server with the power button, and turned it back on. But this time, I logged in on the server itself and launched syslog tail, hoping that the monitor will stay working and I could see the errors, if same crap happened again. tail -f /var/log/syslog Parity check - 0 errors. 👍 I was always using rsync on the backup server itself, to copy files into the locally mounted main server's share. Because those multiple log messages said something about share, I decided to switch it up. I fired up another rsync transfer, but this time I was copying over SSH, and not into the mounted share. And went to sleep. When I woke up, I found that the backup server has hanged again, for the 3rd time. And... everything was the same. Remote syslog showed nothing informative (at least to me) again, ping failed again, and the monitor was black again. The keyboard did not work, I tried CTRL+C, any other keys - nothing. Then I came here and started writing this post, asking for help. 🤪 The server is still "powered on". I decided to not force power down this time, in case there's anything can/need to be done in the process of trying to find out what the hell is going on. I have ran a ~24 hour memory test on the backup server about 6 months ago - perfectly fine, no errors. I've attached the whole remote syslog. Thanks in advance for any help. syslog-192.168.1.22.zip
-
@Iker I tried to make sense of it, but failed miserably. 15TB total space says I have a normal RAID1. 10TB free space says I have RAID1C3. How can I actually see what type I have - a console command or webUI? EDIT is this it? Data, RAID1: total=799.00GiB, used=787.33GiB System, RAID1: total=32.00MiB, used=128.00KiB Metadata, RAID1: total=1.00GiB, used=930.06MiB GlobalReserve, single: total=512.00MiB, used=0.00B @tjb_altf4 Omg, thank you. Although that does not particularly inspire confidence in btrfs whatsoever 😉 Fingers crossed, I won't get punished for going with btrfs over zfs 🤞
-
Like the title says. The weirdest thing - there's %33 of free space is magically missing on a brand new and empty cache pool. 15TB total - 537MB used = 10TB free 🤪 Help please. thepit-diagnostics-20210902-0010.zip

-
I've just installed and started using the File Integrity plugin today. I manually started a `Build` process on 7 (out of 28) drives in my array disk1 had least amount of files, so it has already finished But, the UI shows some nonsense 🤔 it shows disk1 as a circle, not green checkmark, even though it has just finished the build, and is up-to-date it shows disks 4, 5, 9 and 10 with a green checkmark, even though the builds are clearly still running and aren't finished it shows disks 7, 12, 17, 18, 19, 22, 23, 24, 26, 27 and 28 with a green checkmark, even though the build process has never been run on these disk... I mean, WAT? 😳 Can it be, that am I really not understanding what the circle/checkmark/cross means? Or is this a bug?

-
Linux newb here, so... sorry for a probably silly question: I would like to install fd. But it seems nerdpack has a really old version of fd: ``` fd-6.2.0-x86_64-1_slonly.txz ``` 6.2.0 if from Jan 3, 2018 🤔 Current version is 8.2.1 Basically, how does this work in unraid? Do I need to ask here, in nerdpack thread for someone to "update" the included fd package?
-
@olehj Thank You so much for this plugin. Awesome job 👍 A little feature request, maybe... It would be nice if `Comment` could be displayed more prominently - larger font size and bold.
-
@bidmead Awesome looking annotations 🤩 What program are you using to do this?








