




RoTalk
Members
-
Joined
-
Last visited
Everything posted by RoTalk
-
I had the exact same issue, possibly the same, or similar, I ended up buying 2 more flash drives, and for 2 weeks, I was testing various versions from 6.x to 7.1.2 and well I'll post in another thread but very disappointed and bummed for lack of "best guidance" specs when building a Unraid, buy this and that don't wing it with AMD. So far I've been up and running for 2 days with no issue but I had to go inside BIOS and adjust the CPU voltage by 0.25 and sure enough that fixed my "bad" usb drive and my cpu bank reboot fail, I would have random reboots upon boot/login or in a matter of minutes, and I have not had any issues prior to 7.0.1/xetc.
-
Something that was addressed already and the issue I saw. - Disks not showing up in the GUI but get alerts that array is good/normal and nothing found nightly. - Terminal window / shell if you click the button, shows up for few seconds and self closes, so you'll have to putty in. Haven't had a chance to review the fixes yet. Answer/Fix: - Clearing cache/cookies (all time) fixed both issues above.
-
Update: Read the following: [7.0.0-beta.1] Error on VM Start - Prereleases - Unraid What fixed it for me: Issue: Users are experiencing VM startup errors due to incompatibilities with certain machine types and QEMU versions in unRAID. Possible Cause: The machine type specified in the VM configuration (i440fx-7.1 or i440fx-7.2) may not be supported by the version of QEMU/KVM included in your unRAID installation. Suggested Fixes: Use an older, compatible machine type., The 7.1, didn't work, I switched to 6.x (6.2) and worked.
-
Same here, year + with no issue but suddenly, I started getting this from the last update, I have plenty of ram and cache as the vm run on the cache drives. My 128gb/ram is barely 20% used. It happens to all my VMs, my last fix was to go in and delete the *.log /var/log/libvirt/qemu/<vmname>.log One of them started and haven't attempted to reboot or shut down, my other one still doesn't fire up. I'm in a middle of parity check so I will wait before I attempt to reboot entire system. Watching this as well.
-
I started looking at the router that the server is connected to. Noticed that the lights were off on that particular port. Disconnected, unplugged the ethernet cable and putting it back in did not work, but what worked is disconnecting the ethernet cable from back of the server/PC and re-inserting it got the lights back in, and I can connect immediately back to RDP, SSH, and the GUI. Going through logs there is / was a docker that was messing with the same lan adapter or something to that extend.
-
I get the same issue here, the odd thing is, I use Ubiquiti as well, and I have the server plugged right into the switch. When I loose access, I can see the switch having no lights blinking. If you disconnect the "ethernet" cable from the switch nada. If you disconnect the ethernet cable from the back of the server/tower, bham, it lights up and everything back to normal. Same pattern, such as: Jun 27 09:00:19 Tower kernel: veth6b32b85: renamed from eth0 Jun 27 09:00:19 Tower kernel: br-986610407cef: port 1(veth9b6cc1b) entered disabled state Jun 27 09:00:20 Tower kernel: device veth9b6cc1b left promiscuous mode Jun 27 09:00:23 Tower kernel: eth0: renamed from veth576eedf Jun 27 09:00:23 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vetha27e76b: link becomes ready Jun 27 09:00:23 Tower kernel: br-986610407cef: port 1(vetha27e76b) entered blocking state Jun 27 09:00:23 Tower kernel: br-986610407cef: port 1(vetha27e76b) entered forwarding state Unsure if related to the drivers, of the NIC. ASUSTeK COMPUTER INC. TUF GAMING X570-PRO (WI-FI) , Version Rev X.0x American Megatrends Inc., Version 5003 AMD Chipset. And uses the Intel igcIntel(R) 2.5G Ethernet Linux DriverInusenet/ethernet/intel/igc Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) I am on the latest public release for Unraid, but the nic might be lagging. - igc driver and firmware are up version is 6.1.79-Unraid, and the firmware version is 1057:8754. I do see a Firmware as of 2 months ago, so I'll give that a shot, I'd check on that as well and see if it fixes your issue, and I'll report back on mine.
-
I know this is old, and should have been updated on the next OS release, but same exact happens if you have compose and have a docker updated, running latest but up to shows "apply update" and if you click, says same, "Configuration not found. Was this container created using this plugin? Version : Version 6.12.10 2024-04-03 Docker is: Uptime Kuma As of latest version right now is/should be: Version: 1.23.12 I'm fine but an eye sore, at times, thinking there is an update now., but have to remind myself to check monthly to see if there is actual update.
-
I have my current: GeForce GTX 1660 SUPER passthrough to one of my VMs for some light video editing. I am noticing that my Plex taking my 4k/6gb-10gb videos captured on DJI buffers every few seconds and can't play stream @ 1080p because my card's being used. I thought of buying another Nvidia 3060 or alike to passthrough and use the 1660 super to transcode for plex. I had it working awhile back, I wanted to stick with Nvidia because of the plugin, and prior GTX worked, even though I am running AMD, AMD Ryzen 7 5800X 8-Core @ 3800 MHz w/Mobo | ASUS TUF GAMING X570-PRO (WI-FI), I don't game on this at all, just video, or some light video edit, so if there is a better video card out there to handle my video editing that's an option. I looked at several, cards, like: AMD Radeon RX 6800 ASUS TUF Gaming Radeon RX 7600 XT OC Edition GTX 3060, 3080 or Lower. Thanks,
-
I have the same issue since last update, at times the server was unresponsive, and before force reboot, let me unplug ethernet and reconnect and that'd fix it. I did check docker ipvlan and still there but haven't dived into diags yet. Wondering if anyone else has this and if maybe Ubiquiti is also adding to it.
-
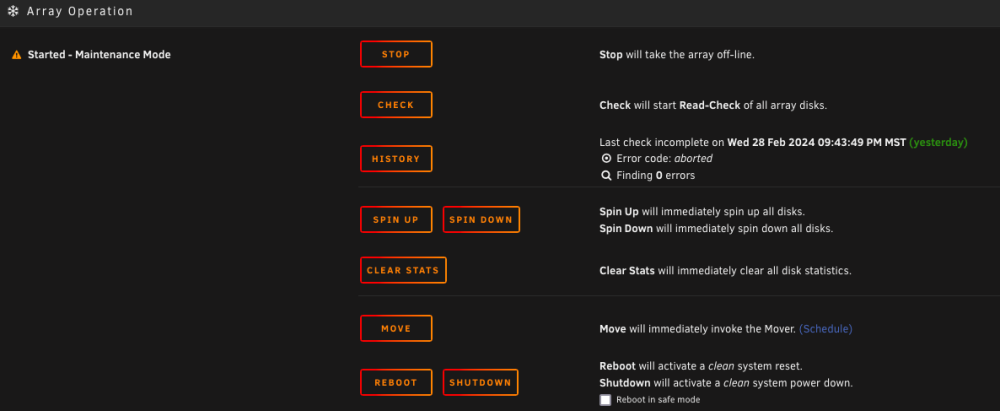
Thank you for the fast reply, I started the in maintenance mode but there is no option to sync, only check. Is the proper way to remove the parity 1, and 2, and after start array, remove, re-add and start the array in maintenance mode to get the sync? -
-
I have been replacing some drives in my box and had a 16,12tb parity drives, later I replaced the 12tb with another 16tb parity and moved the 12tb below and replaced few other 4tb. Suddenly both my parity were disabled at the same time, which is odd. I might have done few things that might have caused this or possibly not. I did a parity (16tb) + 12 tb rebuild at the same time, where documentation states not best practice. I started getting VM Autostart disabled: 27-02-2024 vfio-pci.cfg errors VM Autostart disabled due to vfio-bind error My older config:BIND=0000:0a:00.0|10de:21c4 0000:0a:00.1|10de:1aeb 0000:0a:00.2|10de:1aec 0000:0a:00.3|10de:1aed My other one, forgot which was more recent had: BIND=0000:00:14.0|1022:790b 0000:00:14.3|1022:790e 0000:06:00.0|1022:1485 0000:06:00.1|1022:149c 0000:06:00.3|1022:149c 0000:04:00.0|8086:2723 0000:09:00.0|10de:21c4 0000:09:00.1|10de:1aeb 0000:09:00.2|10de:1aec 0000:09:00.3|10de:1aed 0000:0a:00.0|1022:148a 0000:0b:00.0|1022:1485 0000:0b:00.1|1022:1486 0000:0b:00.4|1022:1487 I went in and edited the /boot/config/vfio config and old had a blank, the new had some stuff in it. I removed it and rebooted. I noticed the issue with parity drive going bunkers when I spun up a old vm but might not be related. My ask is which is the safest and fastest way to rebuild the array without loading any drives to make it faster and as I am unprotected to finish. edit/Adding some pics, of a cable(s) that these 2x12tb drives that I added to array had these additional cables in order for them to spin up. They seem fine now my other 2x16tb parity are the issue.


-
Does NerdTools have or can we request any of the following for disk management to wipe prior to decommission, donate or sell a hard drive? Shred - A command-line utility available in most Linux distributions for overwriting and deleting individual files. NWipe A command-line tool that allows for secure erasing of disk drives, a fork of the DBAN software. Secure Erase - A set of commands for the ATA interface to erase all data from a hard disk or solid-state drive. BleachBit - A free and open-source disk space cleaner, privacy manager, and computer system optimizer that includes file shredding and disk wiping features. Scrub - A command-line tool for Unix-like systems that writes patterns on files or disk devices to make retrieving the data more difficult. Wipe - A secure file wiping utility for Unix-like systems that uses a variety of overwrite patterns to ensure data is unrecoverable. dd - While not specifically a data wiping tool, dd can be used to overwrite a disk with random data or zeros, effectively wiping it. hdparm - A command-line tool to set and view ATA hard disk drive hardware parameters, including initiating a Secure Erase command. GParted - A free partition editor that can be used to manage disk partitions, and can also securely wipe partitions using various algorithms. Any of the top, would be appreciated it.
-
I was on the same boat for months, unclean shutdown, freezes, forced reboots, replaced, USB Thumb drive, stopped Docker and VMs, on and on and only to be fixed by a single line in the go file, why was this it? Why is AMD susceptible to this issue? #!/bin/bash # Start the Management Utility /usr/local/sbin/zenstates --c6-disable /usr/local/sbin/emhttp & Since I disabled the zenstates and also doing that in CMOS/BIOS my server hasn't had any issues, for a week or so now, where as before, it would be a hourly or daily events. Didn't even know I could have looked for this but searching further, multiple posts regarding this and AMD, a bit old but you'd think all these plugins would notify you to check on it i.e. tips and tricks, common problems, base os, etc. Glad I fixed it because it was becoming a burden and regret jumping into Unraid and not the out of box NAS boxes but it did take premium support to narrow it down, but worth every penny. --------------------------------
-
Shouldn't this be caught in the syslogs, if enabled and to write to array + usb? I might be having the same issue as well, replaced, usb, mem test for 2 days all good since day 1, I also noticed I cannot boot in GUI mode, and always used web.
-
I am watching this because I might be experiencing the same thing. I kept on seeing 1 logical core in same env. and noticed the that suddenly I can't connect or get into the server, I'd try it from another laptop only to freeze. Went as far as the docker/vlan settings, replaced my thumb drive and will attempt your fix and report back.
-
Boy all these up time are awesome, cant wait for prem support to narrow issue and let me know why my new build is freezing. My most uptime was 7 days.
-
Can you have some sales on these, and buy them, like buy 1, and get 2nd hour @ half price or something. Have a Black Friday deal and buy them for rainy day. Cyber Monday as well.
-
Mine was good for 4 days and started again, I also tested with all VMS off and dockers. Same thing, I also spent 2 days on mem86 testing all ram/cpu and cleared. I'm leaning towards maybe a bad USB? Also upgraded the firmware for the motherboard as it was 4 versions behind.
-
I've been plagued by Windows 11/VM Freezing up while the other 2-3 vms were fine, removing <memoryBacking> <nosharepages/> <source type='memfd'/> <access mode='shared'/> </memoryBacking> Fixed my issue now too, the VM has been up for 2 days where as before within hours it would freeze, the CPU/Cores would be 100% in the dashboard and as soon as force shutdown would go back to normal and get me few more hours but so far soo good. I guess In summary, not having this configuration doesn't significantly impact my VM's performance or functionality, and it eliminates potential compatibility issues or freezes. Unsure if that was due to virtios or enabling and disabling things later, I wish there is a tuner addon to check on that and remove unwanted, not needed features/xml formats. Had to do some compare vms, xml and remove additional stuff but glad I found this post to fix my issue.
-
Since I removed virtiofs, and stopped the service on my VM, it no longer hangs daily, and having to force reboot. Fingers crossed.
-
Do we know why this would be an issue? Mine suddenly became unresponsive few weeks back and tried, save mode, save mode, without plugins and the only fix was reboot as I couldn't login via ssh, gui, nor console/video, switched the docker to ipvlan and so far so good, additionally I also disabled docker/vms. Hopefully this sticks and fixed my issue as well.
-
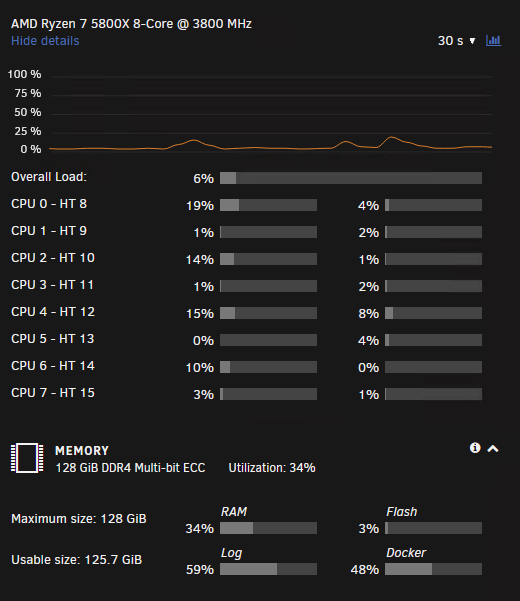
I checked the logs and I have tons of these: May 4 06:10:55 Tower nginx: 2023/05/04 06:10:55 [error] 7965#7965: MEMSTORE:00: can't create shared message for channel /devices May 4 06:10:56 Tower nginx: 2023/05/04 06:10:56 [crit] 7965#7965: ngx_slab_alloc() failed: no memory May 4 06:10:56 Tower nginx: 2023/05/04 06:10:56 [error] 7965#7965: shpool alloc failed May 4 06:10:56 Tower nginx: 2023/05/04 06:10:56 [error] 7965#7965: nchan: Out of shared memory while allocating message of size 10041. Increase nchan_max_reserved_memory. May 4 06:10:56 Tower nginx: 2023/05/04 06:10:56 [error] 7965#7965: *400472 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Right before the above, and I mean 1000s of lines with same patter above, were: May 3 21:39:35 Tower emhttpd: shcmd (901): /etc/rc.d/rc.avahidnsconfd restart May 3 21:39:35 Tower root: Stopping Avahi mDNS/DNS-SD DNS Server Configuration Daemon: stopped May 3 21:39:35 Tower root: Starting Avahi mDNS/DNS-SD DNS Server Configuration Daemon: /usr/sbin/avahi-dnsconfd -D May 3 21:39:35 Tower avahi-dnsconfd[31030]: Successfully connected to Avahi daemon. May 3 21:39:35 Tower emhttpd: shcmd (906): smbcontrol smbd close-share 'drivebackup' May 3 21:39:36 Tower avahi-daemon[31019]: Server startup complete. Host name is Tower.local. Local service cookie is 716002987. May 3 21:39:37 Tower avahi-daemon[31019]: Service "Tower" (/services/ssh.service) successfully established. May 3 21:39:37 Tower avahi-daemon[31019]: Service "Tower" (/services/smb.service) successfully established. May 3 21:39:37 Tower avahi-daemon[31019]: Service "Tower" (/services/sftp-ssh.service) successfully established. May 3 21:40:02 Tower flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update May 4 00:10:11 Tower sSMTP[2417]: Creating SSL connection to host May 4 00:10:11 Tower sSMTP[2417]: SSL connection using TLS_AES_256_GCM_SHA384 May 4 00:10:15 Tower sSMTP[2417]: Sent mail for [email protected] (221 2.0.0 Bye) uid=0 username=xxx outbytes=768 May 4 00:20:01 Tower sSMTP[29433]: Creating SSL connection to host May 4 00:20:02 Tower sSMTP[29433]: SSL connection using TLS_AES_256_GCM_SHA384 May 4 00:20:03 Tower sSMTP[29433]: Sent mail for [email protected] (221 2.0.0 Bye) uid=0 username=xxx outbytes=1341 May 4 05:00:03 Tower Recycle Bin: Scheduled: Files older than 30 days have been removed May 4 05:27:58 Tower nginx: 2023/05/04 05:27:58 [crit] 7965#7965: ngx_slab_alloc() failed: no memory May 4 05:27:58 Tower nginx: 2023/05/04 05:27:58 [error] 7965#7965: shpool alloc failed May 4 05:27:58 Tower nginx: 2023/05/04 05:27:58 [error] 7965#7965: nchan: Out of shared memory while allocating message of size 10040. Increase nchan_max_reserved_memory. May 4 05:27:58 Tower nginx: 2023/05/04 05:27:58 [error] 7965#7965: *374720 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Now I only have 2 vms running and maybe 5-6 dockers hardly eating any memory and have about 128gb/ecc ram in this thing. Found the following post, Pointing to this GITHUB Fix. - https://github.com/slact/nchan/issues/147 My fix was as follow but will dig for anything huge/logs /etc/rc.d/rc.nginx restart /etc/rc.d/rc.nginx reload /etc/rc.d/rc.php-fpm restart /etc/rc.d/rc.php-fpm reload
-
Wondering if anyone else is seeing this, my server is working fine, my VMs, Dockers and everything just fine. Dashboard shows blank and I know if I stop the array and reboot, all comes back to normal but don't want to do that every time. Another question is why is unassigned plugin being updated 2x a week the last month? Thanks,
-
I did a search for Genius Scan Ultra or Pro, I ended up subscribing but from what I have tried so far and read so far, if someone can clarify is as follows: Genius Scan Pro, Ultra or Free cannot work with Paperless ngx directly. Works cloud, ftp and "webdav". You'd need a middle/app like NextCloud or some other to have the webdav. Do we have a suggested, nice app, paid or free to work straight to smb/share or similar to autoexport to Unraid share for paperless-ngx to process? There was one app Scan pro that there was mentioned that was kicked off the store for having malware few years back. - I need something to auto-export, do OCR and have option to scan 2-4 pictures into one single pdf. Thanks,
-
Looks like so far so good I was able to reboot several times no problem.. I haven't verified the integrity of the shares but I feel like I need to do a boot camp and read the wiki... From start to finish.






