




Msan
Members
-
Joined
-
Last visited
Everything posted by Msan
-
For anyone having the issue with it just showing 3 non exiting containers.. Try changing the Network Type to Host in the dockersocket setup..
-
I just starting having a very similar issue, Cant get into the GUI, can't SSH in either. none of the dockers can be accessed via their webpages. But they do respond via their native apps.. ie. Emby, Homeassistant.. In my case this started happening once I turned on "detect episode intros" in Emby and started the task for it. Once I stopped the task the server returned to normal. I tried it again today, started the task and it was fine for a while.. Now everything is "stuck" again and the task is about 25% done. Can't get into the server to check usage or logs until I get back home after work and can try from the console..
-
Updated from 6.12.14 to 7.0.0 without issues. Uninstalled Nerdtools and installed the phyton3 from the apps section..
-
Has anybody been able to run LocalAI with an AMD cpu? I have a Radeon RX 6750XT This is what I get: docker run -d --name='LocalAI' --net='bridge' -e TZ="America/Los_Angeles" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="LocalAI" -e 'DEBUG'='true' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8080]/' -l net.unraid.docker.icon='https://github.com/go-skynet/LocalAI/assets/2420543/0966aa2a-166e-4f99-a3e5-6c915fc997dd?raw=1' -p '6060:8080/tcp' -v '/mnt/user/appdata/local_ai/models':'/build/models':'rw' --device='/dev/dri' --device='/dev/kfd' --gpus=all -e DEBUG=true -e REBUILD=true 'localai/localai:latest-aio-gpu-hipblas' 775b8e6066a85fc1ac7d4008420f77286b7c4f7d38b435c08c6a378982af1988 docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. The command failed.
-
Did you get anywhere with this? I am trying to do the exact same thing without success so far..
-
I just updated and am getting this error
-
It also seems to miss a lot of files on my system on a regular basis.. Here is a wierd display issue.. I am running a manual build, but the icon's don't update see attached..
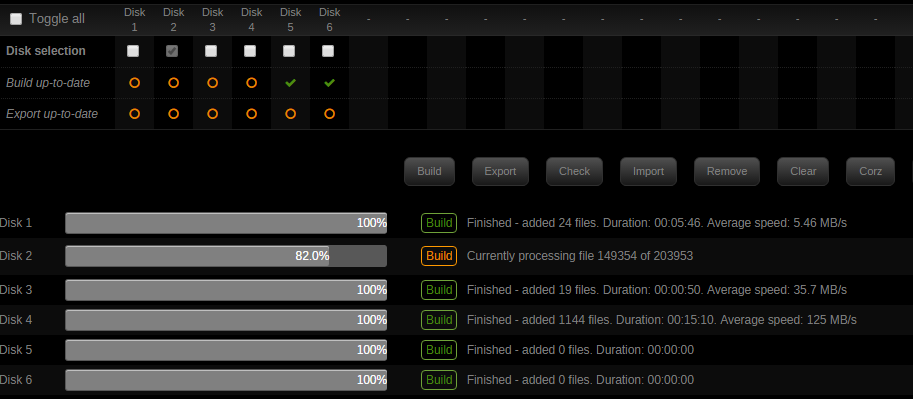
-
It should look something like this in Emby.. (see attached..)
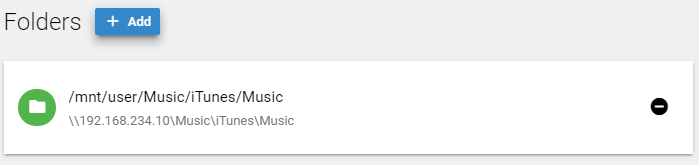
-
He's posting all over the place.. You just had to rain on my parade, didn't you What can I say, it's a gift..
-
He's posting all over the place..
-
Will do.. I doubt my CPU temp will be affected (motherboard only shows low/med/high) and I had it running at 100% cpu usage for 8 hours and it was still at low So far I have 2 doubled up drives.. they seem to be about 1C higher in temp than the ones that are just by themselves in the bay.. I should have all bays filled by christmas
-
I currently have 2 x 3TB WD Red's for parity and 3 x 3TB WD Red's for Data Drives and 2 x 1TB WD's for Cache. Average HDD temp is 26 Celsius. When running parity check average is 27.8C - Case temp is 34C - Ambient temp 20.5C I did add 2 be quiet! Pure Wings 2 120mm 1500RPM 51.4CFM fan's to the top back (I could add one more) for exhaust. cost was 12 bucks each.. Can only hear the server if I'm very close to it..
-
I just got this one: http://www.newegg.com/Product/Product.aspx?Item=N82E16811146216&cm_re=h440_nzxt-_-11-146-216-_-Product and love it.. room for 11 3.5" HDD's and 2 2.5"
-
I'm glad I could help out.. That's the whole point of these forums
-
I've had this the other day as well.. no docker update and emby kept telling me to update manually.. I ran this on the command line and it updated fine: docker exec EmbyServer update
-
Yes, I'll try to find some time to work on it. But don't expect much. It will be just low, high and medium based on a temp. Even that would be great!
-
Is Fan control for supermicro boards still coming?
-
I'm not using it, so can't test it. 6.3.0-rc2 Didn't work under 6.3.0-rc1 either..
-
6.3.0-rc2
-
I did suggest to chmod -R 755 /mnt/user/docker/smokeping. Nope, didnt work.. tried 777 as well.. if I docker exec into the container, I can see the files and directories in /data just fine..
-
If anyone wants me to test something, let me know.. I have no problem with deleting/modding my smokeping install..
-
Not sure what is different on my system then..
-
Yup, after changing /data to point back to /mnt/user/docker/smokeping/ I get the errors again... FPing: probing 20 targets with step 300 s and offset 48 s. RRDs::update ERROR: mmaping file '/data/USA/Sun.rrd': No such device RRDs::update ERROR: mmaping file '/data/USA/IU.rrd': No such device RRDs::update ERROR: mmaping file '/data/USA/UCB.rrd': No such device RRDs::update ERROR: mmaping file '/data/USA/MIT.rrd': No such device RRDs::update ERROR: mmaping file '/data/USA/UCSD.rrd': No such device RRDs::update ERROR: mmaping file '/data/Europe/Germany/TelefonicaDE.rrd': No such device changing /data back to /mnt/cache/docker/smokeping/ now..
-
All cache only shares are also seen under /mnt/user. The only possibility I see and it doesn't make any sense is the format of the cache drive itself. Mine is XFS, what's yours? I have 2 drives as the cache drive.. it's using btrfs @CHBMB - I just checked all the disk shares and there is no stray /mnt/diskX/docker/smokeping/ directory anywhere. I'll try and revert my /data entry again to see if the issue comes back..
-
So setting the /data path to /mnt/cache/docker/smokeping/ worked.. This is strange, as /mnt/user/docker/smokeping/ points to the same place and when inside the docker I could see /data and the files just fine? It's not really strange. /mnt/cache is a disk share and /mnt/user is a fuse (or how it's called) share. Support for hardlinking in user share is still new, so there might be some bugs still. Seems to work fine mapping both /data and /config to /mnt/user/.... running 6.3RC3 ie: No fault found, and since I don't believe there have been any changes since 6.2 RC4 (since the support for special unix files came into effect), I don't know what the issue may be... My docker share that also is seen on /mnt/user/docker is set to "Use cache disk only".. that might be why..



