alturismo
Moderators
-
Joined
-
Last visited
Everything posted by alturismo
-
ok, sounds like you are using hard links and not moving after the job is done, you can check if you have like a "double" folder view, inside /torrents and inside /library never checked on this situation as the usecase here is totally obscure using hardlinks, makes only sense when you always already download to hard disk show a screen from your Share setting page for /media, what is primary and what is secondary about the hard link situation, may even shouldnt bother but woul dmake sense about your cache mover behaviour ;)
-
ok, it doesnt respect the excluded folder /torrents, your setup is looking fine as far as i can tell. i look into that, what wonders me as you are in media server only mode (which is the recommended way) the plugin is only triggereing watching content from your jelly server, in my world, there shouldnt be any processed files anymore in your torrent dir when watching media from jelly, are you may linking files instead moving ? background, plugin checks if you are watching media, if its part of movies or tv, it checks the real file location, /mnt/disk1, 2, 3, ... and then creates a copy to your pool ssd, /mnt/downloadcache/... then changing the file descriptor to the new location. one more question, is your pool "downloadcache" also part of your /mnt/user/media Share ?
-
Fehler sollten im log erscheinen, aber ... USB ist halt leider USB ;) bei einer VM ist immer empfohlen, eine pcie (USB) Karte komplett an die VM zu reichen anstelle einzelne USB devices, das nur als Tipp.
-
would need some more context 1/ what is your issue actually 2/ how does your overall setup look in terms of -- cache, array setup -- jellyfin mount setup -- plugin setup then i may could say something about it ;)
-
@Tarawa nur mal angemerkt, wenn ich mich mit einer KI unterhalten will kann ich das selbst, dazu brauch ich das hier sicher nicht ;)
-
was auch nicht nativ integriert ist, da ist die einfache nginx http Implementierung wohl einfacher wie webdav.
-
das ist recht ambitioniert. meine lokalen 2 n100m Systeme n100m, pico PSU, 1x nvme, 2x sata, 1x 2.5G NIC, idle MIT docker Service 12 Watt (max c8 Unraid) n100m, sfx 300 PSU, 1x nvme, 3x sata, 1x 2.5G, asm1064 (bios flashed), MIT docker service 16 Watt (max c8 Unraid) Docker Service kostet ca. 2 Watt mit laufenden Dockers hier (ohne Last) immer auch alles unnötige im BIOS deaktiviert, onboard NIC, sata bei dem 2. sys da 3x an asm1064 hängt, usw ich hab das sfx vs. pico auch mal getestet, sind 3 Watt direkt im 1:1 Vergleich hier gewesen, sprich, die asm1064 mit 3. hdd sata hat 1 Watt idle ausgemacht, das pico macht halt was aus ... aber für 3 Watt nehme ich jetzt nicht 80,- in die Hand ;) das sfx war noch da. mit den Controllern, Platten usw im idle unter 10 zu kommen wenn auch Dienste laufen sollen halte ich für sehr ambitioniert, deine 12W oben sind schon die Richtung was geht, dazu noch mit einem nicht wirklich effizienten Netzteil in diesem Szenario. Nachtrag, Lüfter, sind bei diesen Messungen im idle immer off, Lüfter laufen hier nur im Betrieb HDD Lüfter wenn hdd aktiv, cpu Lüfter nur wenn CPU Temp > 65°
-
jetzt mal gefragt, mega war meines Wissens nach easy im setup, username (email), password, fertig, oder wo bist du hängen geblieben ? RcloneMegaRclone docs for Mega
-
mal abgesehen davon dass das furchtbar zu lesen ist ... und der Transfer "lokal" von VM <> pool nicht am NIC hängen sollte, ein paar Anmerkungen 1/ Tiny VM überdenken, vielleicht fehlt ja was ;) 2/ du schreibst 10G NIC, deine bond mit 2 NIC's welche jeweils 5G können und mit 1G verbunden sind ... (wobei du evtl. nur die lokale VM NIC meinst) 3/ DNS, du nutzt google und CF ? vielleicht mal lokalen Router testen 4/ den ganzen multichannel Kram deaktivieren bzw, revidieren, sollte nicht nötig sein für single NIC und normale transfers sofern die CPU nicht im bottleneck wäre rein von speed her sieht es ja fast so aus als würde es irgendwie über die 2x 1G Leitung laufen, da ich jetzt noch in Erinnerung hatte "VM mit eigener xml ohne libvirt da du deine eigene xml ...." und ich mir das oben nicht im Detail anschaue, vielleicht mal wirklich erstmal alles Standard testen, dann custom ? aus Erfahrung, einfache 10G lokal zu einem schnellen pool, ohne irgendwas einstellen zu müssen, kein Problem.
-
das ist ja eher ein hardware Problem, angefangen beim RAM ... bz.... verify passiert nach dem laden im RAM, wenn die Datei defekt wäre (USB fail) käme normal eine Fehlermeldung dass die nicht in Ordnung ist, wenn "harte" Neustarts passieren, eher reine hardware, RAM, PSU, CPU, ... leider schwer zu debuggen.
-
gemäß Konfiguration wenn /mnt/media der besagte zfs pool wäre, ja ;)
-
vorweg, das libvirt.img hat nichts damit zu tun wie du deine vm's betreibst, sprich ob per nvme pass oder vdisk.img, sprich, falscher Denk Ansatz. in dem libvirt.img sind persistent die xml Dateien hinterlegt, diverse VM (kvm qemu) Grundsettings, Bios TPM files, usw ... Lösungsansatz, 1/ VM Dienst stoppen 2/ das libvirt image löschen 3/ VM Dienst starten evtl. auch zwischen 1 und 2 oder 2 und 3 Neustart falls das nicht gehen sollte, danach ist alles "blank", schätze du hast mit deinen Eingriffen was kaputt gemacht. Um deine vorhandenen vm's per xml halbwegs sauber einzuspielen, Beispiel 1/ VM anlegen und NICHT starten jetzt hast du eine xml welche du im Form view komplett editieren kannst mit deinen speziellen Einträgen (was auch immer du da machst, wird seinen Grund haben), dabei aber die uuid nicht verwerfen !!! sprich, wenn du stumpf einfach deinen xml Inhalt rein kopierst, den uuid Eintrag aus der vorhandenen übernehmen, ebenso die Bios file settings falls die auch manuell sind. Danach kannst du die dann sauber starten sofern das alles korrekt ist was du da machst.
-
ganz ohne wird es nicht gehen ... entweder eine app (docker) deiner Wahl oder setz zumindest eine separate nginx Instanz als fileserver auf (eine nginx conf mit server auf anderem port) kann man dann beim boot nach array start mit starten (Beispiel) dazu aber einlesen und nicht "out of the box" erwarten ;) das auth system aushebeln wird nichts werden ...
-
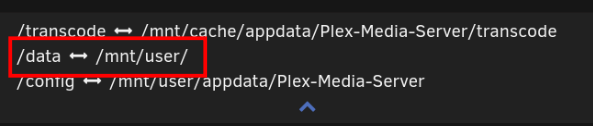
hast du es denn mal versucht, einfach 1:1 zu übernehmen wie du auch deinen Plex Docker konfiguriert hast ? da ist kein .../movie drin, fertig ... später im kompletten Pfad, ja, aber im mount, Nein, das plugin macht den Rest zum Pfad finden und korrekt zuweisen. kurz, innerhalb plex ist dein Pfad /data/movie/was auch immer in real auf dem host ist der Pfad /mnt/user/movie/was auch immer mit deinem rewrite schaut das plugin nach auf dem host nach /mnt/user/movie/movie/was auch immer ... was nicht mehr passt. du hättest nur das rewrite im plugin anpassen sollen, sonst nichts ... wenn du jetzt das mapping am docker verstellst ist es klar dass das nicht passt, egal wie. wenn du es mir nicht glaubst, alles gut, aber dann brauchen wir auch nicht weiter schauen ;)
-
192.168.1.14 ist die Unraid IP ? config.php ist auch konfiguriert mit trusted wie hier aufgezeigt ß natürlich angepasst, evtl. noch die 172er Masken mit dazu und NPM ist auch in der Standard bridge ? ich nutze weder NPM noch NC aio (NC lsio und swag hier), nur wenn es in der custom:eth0 mit eigener IP geht, sollte ...
-
welche ip / port hast du denn genutztin NPM ? nur um sicher zu sein ... in der Standard bridge funktioniert das per name normal nicht, nur in einer custom bridge. setz den NC mal in die bridge (welche ports sind dann mapped), zeig mal auf wie du NPM zu NC verbinden lässt, dann sieht man evtl. eher den Fehler, sofern dank "aio" nicht eh schon alles kaputt konfiguriert ist ;)
-
sollte nicht ... wird sicherlich an etwas anderem gelegen haben, weil die "neue" xml mit gleichen Einstellungen macht ja nichts anderes, das uuid Thema hat nur was mit der qemu Registrierung am Hut, nichts mit der VM an sich.
-
das kopieren der neuen uuid in eine vorhandene xml wäre auch nur ein Thema wenn die libvirt neu erstellt wird ... hier fehlt mir etwas Kontext um was dazu sagen zu können. das "recovern" im fatal Fall (libvirt zerstört, nur xml und image Backup vorhanden) 1/ VM Dienst stoppen 2/ libvirt (defekt) löschen 3/ VM Dienst starten (neues libvirt image wird erstellt und mounted) 4/ neue VM erzeugen (gleicher Name wie alte VM) > nicht starten 5/ xml ersetzen unter /etc/libvirt/qemu (nur uuid der neuen VM übernehmen, Rest aus der alten) 6/ VM starten und enjoy ... das sollte es gewesen sein ;)
-
genau, so wäre der sichere Weg, ich hab die sogar als im laufenden Betrieb kopiert, aber da steckt ein gewisses Risiko dahinter ;)
-
Moin also, die relevanten Daten (bei laufendem VM Dienst, die VM an sich muss nicht laufen( die xml's (Startparameter) liegen unter /etc/libvirt/qemu und können simpel per script daily, weekly, ... weggesichert werden. >> benötigt für recover nach config Änderungen und man nicht mehr weiß was man gemacht hat. die images liegen meist unter /mnt/user/domains >> benötigt für recover nach Änderungen innerhalb einer VM (Win Update und co) und man nicht mehr starten kann. wenn mir jetzt die disk abschmiert wo die /mnt/user/system/libvirt... wäre, hätte ich erstmal ein "kleines" Problem da die uuid's nicht passen in den xml's, natürlich nur wenn ich nicht das libvirt.img gesichert hätte sondern nur die xml'x. Beispiel aus einer xml was tun, einfach eine neue VM anlegen und NICHT starten (eine uuid wird generiert), jetzt die UUID in die "alte" xml kopieren, die xml passend kopieren, starten, fertig.
-
Nein, ich habe dir doch sogar einen screenshot eingestellt wo man dein mapping sieht, dass das movie oder was auch immer ist macht das plugin dann ... dann hast du als watch dirs Filme Serien stehen, wenn es doch "movies" sind sollte das auch angepasst werden ;) davon ab, hast du noch Platz auf dem cache ? 😬
-
Einfach die /system/libvirt/libvirt.img sichern, da ist alles drin. XML, BIOS Dateien, kann man auch raus kopieren wenn der VM Dienst läuft.
-
Plex and emby check, need to install jelly to make sure it's also working there.
-
exakt.
-
alles gut ;) mal vorne angefangen, je nachdem was für ein pool das ist (zfs ist kritisch), ein config Fehler, dein remapping im plugin ist falsch, das /movie/ ist zu viel. das korrigieren, dann umstellen auf only ... aktuell wird das plugin die Aktivität erkennen (multi mode), aber da das plex rewriting nicht funktionieren kann wird auch nie "umgeschaltet" sollte es "eigentlich" gewesen sein.