




physikal
Members
-
Joined
-
Last visited
Everything posted by physikal
-
Thank you! Would you mind clarifying what you mean make sure the config is on a share? If it's on a share how would I direct the container to use it? Any additional details you can provide would be helpful. Thank you!
-
@KluthR Any info you can provide here? Thanks!
-
I'm actually having the same exact problem as you. Any chance you found a resolution to it? Thanks!
-
Ok ty. I'll reboot it and see if that helps. Thanks!
-
I tried that and it didn't seem to fix it. I did uninstall it via going to plugins, selecting it, then clicking remove. Then I reinstalled it via the dropdown/popup from the right. That should be good right?
-
I'm experiencing something different. First the myserver plugin was logged out, but now when I attempt to re-sign in it's telling me the login and password is wrong. But I know it's right because I can login to the website and check myservers where it says mine is signed out. It's very odd.
-
Is this the case if I was to upgrade to a NEWER SuperMicro 24 bay server, from an older supermicro 24 bay server? Is it as simple as shutting the server down, pulling all the drives and putting them in the same physical location in the new server and moving the USB drive? Thanks!
-
I am getting similar errors and am curious if this is your issue.
-
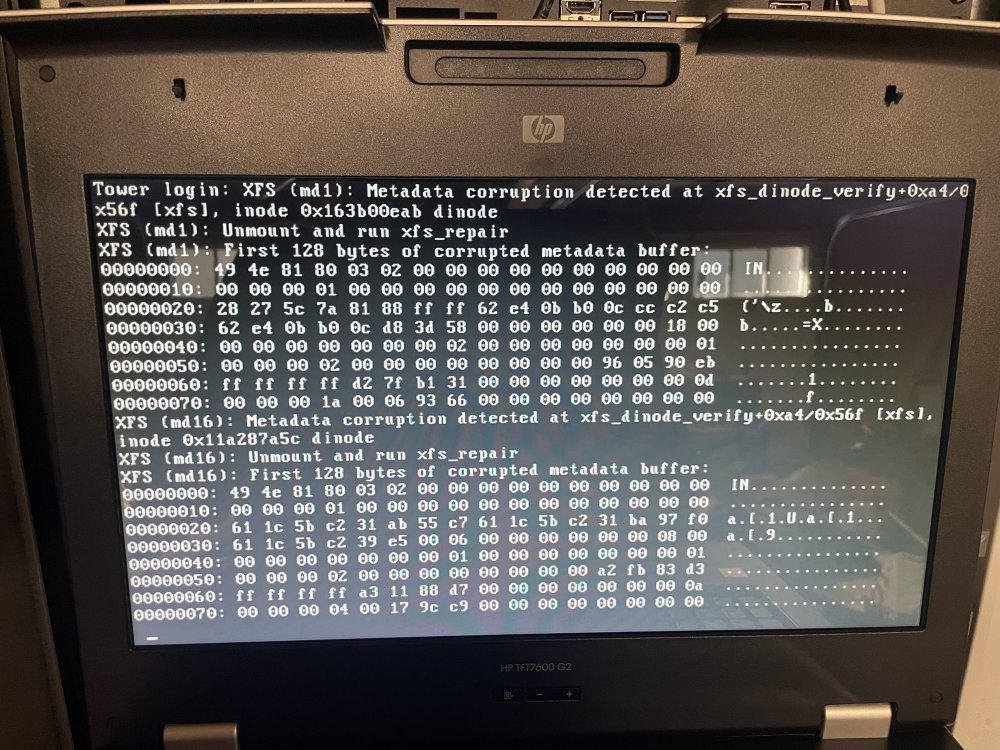
This is the result: Phase 1 - find and verify superblock... - block cache size set to 8461064 entries Phase 2 - using internal log - zero log... zero_log: head block 1998769 tail block 1998769 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 bad CRC for inode 5967449771 bad CRC for inode 5967449771, would rewrite Bad atime nsec 2173239295 on inode 5967449771, would reset to zero would have cleared inode 5967449771 - agno = 3 - agno = 4 - agno = 5 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 4 - agno = 3 - agno = 1 - agno = 5 bad CRC for inode 5967449771, would rewrite Bad atime nsec 2173239295 on inode 5967449771, would reset to zero would have cleared inode 5967449771 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Tue Aug 30 20:34:12 2022 Phase Start End Duration Phase 1: 08/30 20:32:49 08/30 20:32:49 Phase 2: 08/30 20:32:49 08/30 20:32:58 9 seconds Phase 3: 08/30 20:32:58 08/30 20:33:54 56 seconds Phase 4: 08/30 20:33:54 08/30 20:33:55 1 second Phase 5: Skipped Phase 6: 08/30 20:33:55 08/30 20:34:12 17 seconds Phase 7: 08/30 20:34:12 08/30 20:34:12 Total run time: 1 minute, 23 seconds
-
Thank you so much for your help. I'll do that asap.
-
Disc4 is rebuilding because it was a drive that was running crazy hot (up to 54c) so I replaced it with a newer drive that I think would (and is) running cooler. I'm starting to wonder if temp was a reason for the kernel panic. So it was more of a preventative thing. Only my UnraidOS is running on USB. Correct - nothing assigned to disc 7-10. Thanks!
-
Alright here are the diags. tower-diagnostics-20220828-0833.zip
-
Roger that. As soon as I get home I will.
-
I know it says unmount and repair but unmount what?
-
Anyone else getting the error: ERROR contact:service ping satellite failed {"Satellite ID":
-
I am experiencing this same issue.
-
Any chance the jar file issue will be resolved? @hernandito
-
Any thoughts on creating a container for this? https://github.com/upfiring/upfiring-update/releases Hope all is well @Jcloud !
-
@Jcloud so is your repo going to have an update soon that fixes a lot of this and works w/ the main repo? Or are we supposed to remove yours and start over with the main repo again? I"m asking because something is definitely not right. My peers is still really low and I'm not getting additional data as frequent as I used to on the other repo. Thanks!
-
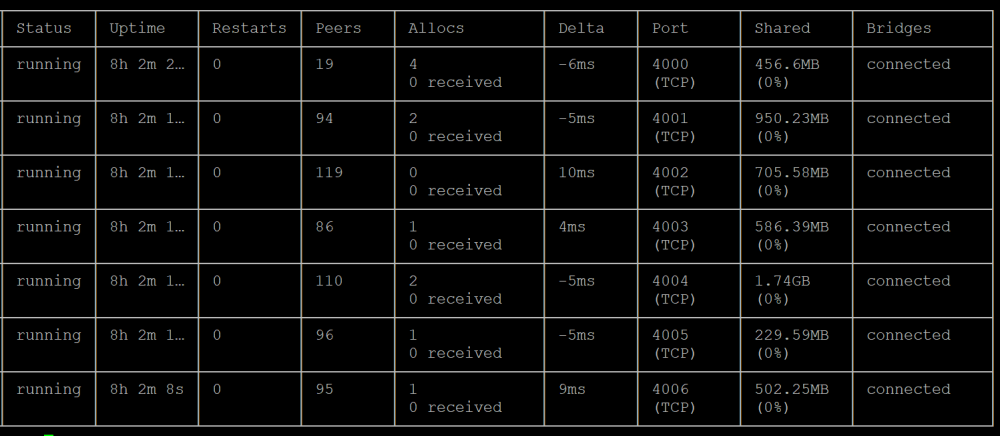
Was there an update or something that isn't current on this docker? Seems like my peers are super low.
-
FWIW I also noticed an issue using the CA Backup plugin the StorjMonitor docker doesn't start up on it's own properly. I didn't capture any error logs or anything - sorry I'm not more help lol.
-
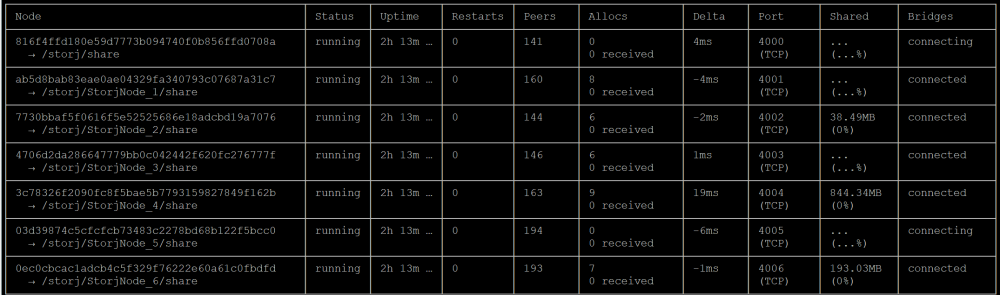
oh interesting, just checked and now only 1 is "connecting", the rest are connected. I'll just give it more time
-
br0 w/ fixed IP. Worked fine for my other version (and the rest of the nodes). Just odd those 2 won't connect.
-
Anyone else experiencing this? all but 2 nodes are connected and working fine. The other 2 are "connecting". Odd right?
-
@Jcloud you're a badass...I forget if you sent me your ETH address or not. If not, please send. I need to donate.



