bobobeastie
Members
-
Joined
-
Last visited
Everything posted by bobobeastie
-
I started having this issue after updating from the latest 6.16 (where all was good) to 7 beta 3. I have an encryption password, so the main tab looks fine until I enter the password. One attempt had the main tab keep reloading/flashing, eventually it went back to the blank array view. I tried some restarting nginx command/scripts with no effect. Have tried different themes and nothing helps. I also woke up to this box being unreachable on my network. EDIT: Thanks JorgeB I didn't know chrome was trying to protect me. flags-diagnostics-20241011-1011.zip
-
Both of my instances of this container broke this morning, they were fine yesterday. Normally it doesn't ask me to log in, but today it's asking to log in and admin/adminadmin is not working which was in my password manager. I can use: Adding this line under [Preferences], in the config file, works, for setting the default password manually to: adminadmin WebUI\Password_PBKDF2="@ByteArray(ARQ77eY1NUZaQsuDHbIMCA==:0WMRkYTUWVT9wVvdDtHAjU9b3b7uB8NR1Gur2hmQCvCDpm39Q+PsJRJPaCU51dEiz+dTzh8qbPsL8WkFljQYFQ==)" to get past the login, but none of my torrents are present, it's like a fresh install, I noticed the download path changed to point somewhere on appdata. EDIT: Just remembered I have a third instance on another UnRaid box, it appears to be unaffected, it came back fine after restarting. EDIT 2: Don't know what happened with the passwords being forced all of a sudden, but the 2nd instance came back after the admin/adminadmin fix. I changed the paths on the first instance, which I guess worked, it just took 5+ minutes for it's torrents to show up. EDIT 3: What happened is I was moving the contents off of one of my cache drives so I could replace it, container paths are hardcoded to that cache drive, I'm an idiot, forgot about appdata. So I'm all good, leaving this here ion case it helps anyone.
-
For anyone still having trouble, I found a post on reddit which fixed my db issue: $ sqlite3 sonarr.db ".dump" | sqlite3 new.db then I delete sonarr.db and rename new.db to sonarr.db I'm getting a terminal in the correct place by navigating in Krusader.
-
No, but I'll keep an eye on it to try to get some timestamps and new diagnostics, thank you. I've been thinking maybe it's qBitTorrent filling up the space, but the "Pre-allocate disk space to all files" box isn't checked. That is the only thing writing to this drive.
-
I'm having an intermittent issue where the free space on a 1 TB nvme drive keeps disappearing. Every 20 minutes to an hour or two, it will switch back and forth between showing the real amount of free space, and showing the same used number but no free space. and it's not that only the display is wrong, nothing is able to write to the drive at the time it's says it's full, I think. flags-diagnostics-20231209-1357.zip


-
I'm trying to set up a second instance of qbittorrent, I found this link and followed A4. Now I can get the webui to work, but only briefly. When IO open settings successfully, I can't save, chrome says: "Unable to save program preferences, qBittorrent is probably unreachable." Or, It doesn't load and I see: "Error: n". Then I have to log back in. I was able to add a torrent from a plugin on firefox, and see it in the webui. What can I do to fix this? Thanks EDIT: I deleted and restarted on the second container, had the same issue. Currently both containers seem to be functioning after stopping the 1st container, restarting the 2nd, which at this point started working, I could save settings, and then start the 1st container. I don't know if they are fixed or the order the start in might have top be like this? I'd still like to get the webui button to have the right port.
-
Sorry, my solution was buying a used SFF desktop from ebay to run proxmox on. Bonus of now having an intel igpu for transcoding, my 2 nasses are AM4 Ryzen based.
-
It was successful on a smaller directory. I just realized I had the Scan Images or whatever checked and the setting that says 1 is most stable was at 2. I think the 2 was my fault. I'm trying the whole thing with those two issues fixed. EDIT: It just finished on the whole thing! Thanks.
-
I don't know how I would know that the number of files is the cause for sure. I would/do choose to scan all of them preferably, rough estimate for me is 230K files. I scan the same directories successfully with the Windows version. It takes about a day to finish, and I generally start it at night and close everything so it has enough memory. I noticed that this container only uses a bit more than a gig or RAM, which seems low in comparison. I guess I'll run a test on a single small directory...
-
I have no clue what any of it means, see attached. Thanks. VDF.log
-
"...\appdata\VideoDuplicateFinder\log\nginx\error.log" is empty right now. I just starting running a scan, I'll check again if/when it crashes. I think I checked previously and it didn't look useful, but I may not know what to look for. EDIT: I had the warning "Fix Common Problems: Warning: Docker application VideoDuplicateFinder has volumes being passed that are mounted by Unassigned Devices, but they are not mounted with the slave option". I fixed that, don't know if it could be the cause.
-
This isn't working for me, it runs for a while but eventually I check and the container has stopped running. Maybe I have too many files, but don't we all? I have been using this on windows for years and it's great now, except for some groups of 50+ false duplicates. In it's early days I'd have to run it a bunch of times to get anything, because each run made a little more progress before crashing. Maybe that's what's happening here? I'd much rather run this in a docker container on the system that the files are on, than my Windows PC.
-
I just started having this same issue after changing all of my cache mounts from referencing user to the cache drives name because I saw a youtube video about IO Wait. Changed the 2 path settings in the VM config back and still have the issue. it's a home assistant VM if anyone cares. I was having rebooting issues before today, but I found a message regarding insufficient memory, which I think I solved by changing the memory settings for the VM, so probably unrelated. Reboot didn't do anything. Tried creating a new debian VM and that wont start either. Diagnostics attached are from after reboot and Debian attempt/test. nastheripper-diagnostics-20230119-1642.zip
-
Mine is using over half my CPU and the log repeatedly mentions changing a secretkey.
-
Is anyone else having an issue where you can manually recheck finished files and the files are found to be incomplete? I have had to recheck/downloads up to 3 times in a row at times. I have seen the percent done go from 100% to 80% on some files. I'm seeing very noticeable glitches in video files downloaded through deluge. UnRaid isn't reporting any issues with my array/fs. It started around a month ago, seemed to get better, but is now worse for me.
-
I had: ...too. Found a backup a couple of weeks old that didn't result in errors. There was an update I installed after having the issue, but I think I still had the error after it. Now I need to find a way to make a backup every day for X days. Default of every 3 days for Plex's internal backup isn't cutting it. I tried following the directions here: reddit: database_errors_seemingly_unrepairable but am not smart enough to translate from their example to my environment.
-
I think this container was slowing and then killing the unraid web ui after filling up logs after updating to 6.10. A reboot of unraid fixes the issue temporarily. My log is filled with this: May 29 08:49:08 NAStheRIPPER nginx: 2022/05/29 08:49:08 [error] 8928#8928: *1899305 limiting requests, excess: 20.348 by zone "authlimit", client: 172.17.0.15, server: , request: "POST /login HTTP/1.1", host: "192.168.1.10" I see here that we are supposed to use the hash URL, I wasn't using the MyServers plugin previous to updating to 6.10. I'm not sure I got the hash URL correct, I recently rebooted to get things working more quickly, otherwise pages to 5-10 minutes to load, and I'm still seeing errors, 2st is docker log, 2nd is unraid log Get Main Details for ip: https://NUMBERS.CENSORED.myunraid.net:444/ Failed May 30 10:38:49 NAStheRIPPER nginx: 2022/05/30 10:38:49 [error] 8994#8994: *64073 limiting requests, excess: 20.086 by zone "authlimit", client: 192.168.1.1, server: NUMBERS.CENSORED.myunraid.net, request: "GET /login HTTP/1.1", host: "NUMBERS.CENSORED.myunraid.net:444" Note: The censored "NUMBERS" after server is my unbraid local IP, and for host it is different and matches the hashed URL. I may have initially had the wrong url, like I hadn't removed https://, and I may have included too much at the end. Now I am using NUMBERS.CENSORED.myunraid.net in the unraid api web ui, and checking the https box. The list there is populated, and I can, for example, pause a container, after being asked for username and password again. But at the same time I'm still getting the errors which leads me to believe I'm back on my way to having a full log file and slow to no web gui response. I'm at 3% log file after around an hour. I have a second unraid box that seems like it should have the same issue, but I don't see anything in the syslog and it hasn't had any slow or unresponive web ui issues, I updated the unraid api settings and now its log has the same errors. nastheripper-diagnostics-20220530-1054.zip
-
I can't update this plugin on one of my unraid boxes, I removed it and now also can't install, the error I get is: plugin: run failed: /bin/bash retval: 2 Looks similar, if I run "du -x / | sort -n" the output is attached. The top is cut off but I think the lower the number the less useful in this case. I don't want to buy more RAM, or even temporarily shuffle RAM around. 2nd Edit: I was able to install and update the plugin through Main Plugins Page -> Install Plugin -> Config Folder -> Plugins.Removed -> recycle.bin.plg, and then was able to update normally. du.txt
-
I did look at a couple randomly, the files I looked at had their correct names, I think I even had directories not in the root position that had their correct names. It was the prospect of re-organizing hundreds of thousands of files that made me choose to delete and transfer from the old disk.But I totally understand if that's not normally what happens, and I was going to say file comparing might be an option in cases where the names were lost, but take too long, but files being split makes that likely impossible. Plus in the case of only a directory list you can't file compare.
-
It was pretty much the whole drive which had been full. The old disk7 is mounted on another unRaid system in unassigned devices. I gave up waiting (my problem, not blaming anyone) and deleted lost+found and started copying files over. For anyone in a similar situation, don't do that. Copying in Krusader, I had the transfer stall in at least 1 place, and the drive is up to 65535 reported uncorrect. I'm copying other directories and have transferred about half of the total drive, I'm going to just keep moving anything that will move. I didn't have enough space to not delete lost+found. It occurred to me a good solution would be to have a script move lost+found files around using either a list of file locations saved on a cron, or from the old disk7, therefor skipping transferring most files. Maybe this situation is too rare to make that worthwhile. I will be looking in to creating a daily listing of what files are on which drives.
-
Rebuild finished and xfs check resulted in only a lost+found folder. I put the old disk7 in my other unRaid box and mounted with UD and can see the contents. I'm assuming if I swap the new disk7 our for the old that I might need to create a new config and rebuild parity? Or I could delete lost+found and write the contents from UD over my network to the array? Whats the safest option? Option 2 seems safer and less steps, ultimately I think I don't want the disk in the array. Smart report attached for the old disk7 just in case. Quick version is 6 Reported uncorrect, 16 Current pending sector and 16 Offline uncorrectable. EDIT:Should I run an XFS check on the drive in unassigned devices, and if so how? nastheripper-smart-20211207-0929.zip
-
I suspect it has been causing sporadic issues for a couple of years, I would stupidly swap out disks or sata cables that had probably already been in the mix, I even moved what seemed to be the problem set of drives to a SAS card and it continued. I just did the tape thing and all the drives showed up, so I started the rebuild, and Disk7 shows "unmountable: not mounted". I think the correct procedure is to let the rebuild on to disk7 continue, when finished, put the array in maintenance mode, and run the varying degrees of filesystem checks? As seen here: https://wiki.unraid.net/Check_Disk_Filesystems#Checking_and_fixing_drives_in_the_webGui . Or am I better off replacing the new disk7 with the older one and seeing if there are errors? Or both, in that order? My understanding is that something cause a filesystem issue, probably insufficient power, and that issue is present in the emulated disk7, which is being written to real disk7. Once it is completely on disk7 and not emulated I can then hopefully get the FS check to fix it. If the FS issue was caused by power issues then maybe the original disk7 is free of the errors? flags-diagnostics-20211206-1622.zip
-
Thank you. Disk9 wasn't touched today, however, I have been solving the 3.3 pin issue with molex to sata adapters, and I added a new adapter and I think there is only one molex to plug in to. I'm guessing Disk9 is plugged into that molex and isn't getting enough power. I think therefore the solution is to try taping the pins and spreading out sata power as much as possible. Does that seem likely/possible?
-
Have to explain back a couple of steps, disk 9 was not great and I had a drive I thought was better being replaced on my main NAS, rebuilding the "new" disk 9 was going at 30MB/s and I was getting low helium warnings, I thought it would be better to let it finish for some reason, so I did. Then I replaced disk 9 yesterday with another drive that came off my main NAS, it finished rebuilding this morning, it had a normal speed and I think no major issues. Throughout all that action I noticed that disk 7 was having issues, so this morning I replaced it with another drive. I had some issues with rearranging power cables because I have a bunch of WD shucked drives, initially I had a bunch of drives not show up, but I didn't start the array. I finally got every drive to show up, other than disk 7, selected the new drive in that slot and started the array. The number under ERRORS for disk 9 in the Main tab started shooting up, and I see that Log is at 100%, and this was immediately after a reboot. It also wasn't showing that it was reading from disk 9 or writing to disk 7. Is my issue filesystem related or hardware? What is the safest next step? I can put the previous disk 7 drive back in if needed. I have a WD red in the middle of 2 pre-clears as a test, coming off my main NAS, which I can replace a drive with if needed. Docker has been disabled previous to any of this and there are no VM's. I paused the parity rebuild, errors are at 14 million. Thank you. flags-diagnostics-20211206-0936.zip
-
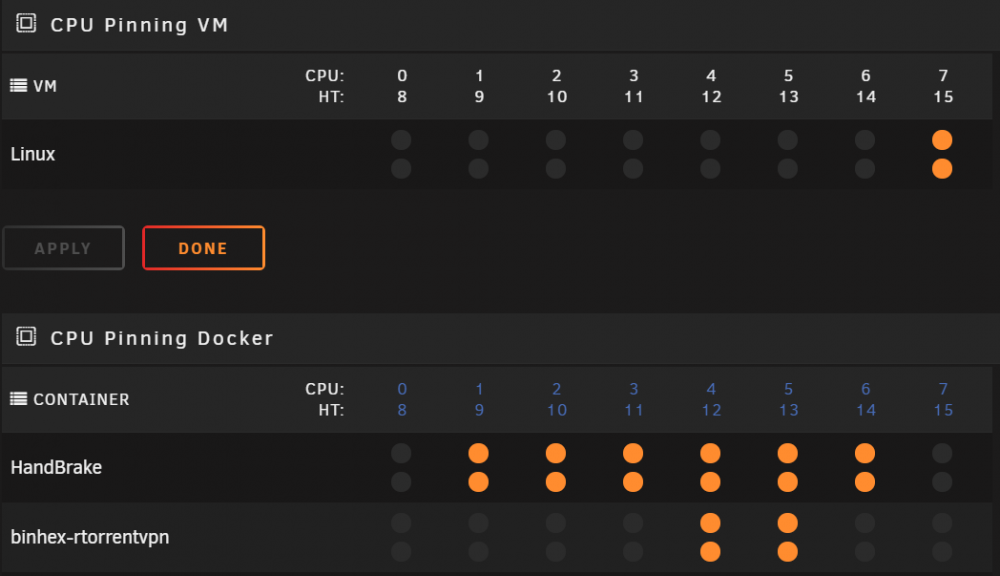
Thanks, things are in the array in both cases. I didn't really change anything before it started working again today on what I'll call Box1... except I did pause handbrake. My other instance of rtorrent (Box2) has not had handbrake running on the same machine until recently when I started having issues. Box 1 has a pinning shown in the attached image, Box2 has no pinning set. Is this my issue? What should I change them to, rtorrent getting x amount of dedicated cores? I'm thinking I might have misunderstood pinning when I set this up.