




KoNeko
Members
-
Joined
Everything posted by KoNeko
-
i tried it again. but all i got now is 2020-11-16T18:50:19.072503Z qemu-system-x86_64: -device vfio-pci,host=0000:0b:00.0,id=hostdev0,bus=pci.3,addr=0x0,romfile=/mnt/cache/system/vbios/Palit.GTX980.4096.rom: Failed to mmap 0000:0b:00.0 BAR 3. Performance may be slow 2020-11-16T18:50:19.386211Z qemu-system-x86_64: vfio: Cannot reset device 0000:0d:00.3, depends on group 21 which is not owned. 2020-11-16T18:50:20.438181Z qemu-system-x86_64: vfio: Cannot reset device 0000:0d:00.3, depends on group 21 which is not owned. and the log is filling up VERY quickly with these lines. like matter of seconds and the /var/log/syslog is full. Need to reboot to get it cleared. 2020-11-16T19:36:52.808331Z qemu-system-x86_64: vfio_region_write(0000:0b:00.0:region3+0x10eb41c, 0x0,4) failed: Device or resource busy 2020-11-16T19:36:52.808344Z qemu-system-x86_64: vfio_region_write(0000:0b:00.0:region3+0x10eb420, 0x0,4) failed: Device or resource busy 2020-11-16T19:36:52.808356Z qemu-system-x86_64: vfio_region_write(0000:0b:00.0:region3+0x10eb424, 0x0,4) failed: Device or resource busy 2020-11-16T19:36:52.808368Z qemu-system-x86_64: vfio_region_write(0000:0b:00.0:region3+0x10eb428, 0x0,4) failed: Device or resource busy
-
with vnc it works normaly. With the gpu passthrough it does work but it seems a little bit laggy. even when i just click on file explorer.
-
i got a threadripper 2950x
-
I also have a problem with passing my GPU to my windows 10. runnin unraid 6.8.3 when i do all the above i get 2020-11-14 21:29:10.154+0000: Domain id=16 is tainted: high-privileges 2020-11-14 21:29:10.154+0000: Domain id=16 is tainted: custom-argv 2020-11-14 21:29:10.154+0000: Domain id=16 is tainted: host-cpu char device redirected to /dev/pts/0 (label charserial0) 2020-11-14T21:29:10.225526Z qemu-system-x86_64: warning: This family of AMD CPU doesn't support hyperthreading(2) Please configure -smp options properly or try enabling topoext feature. libusb: error [udev_hotplug_event] ignoring udev action bind in the log file. before when i didnt do that i got that vfio-pci 0000:0b:00.0: BAR 3: can't reserve [mem 0xd0000000-0xdfffffff 64bit pref] i can do the same for ubuntu VM without any of these things. It just works. Edit: It works it just Takes a very long time to get into windows. and it does not feel smooth. I gave it 12 core and 16 gb so should be smooth.
-
I have a new unraid server its a AMD threadripper 2950x with a 980 GPU i had to install the windows VM via VNC and that all works fine. but once i add the videocard in the template and start it. I see it starting and saying booting from hdd. and black screen and when i check the log i see kernel: vfio-pci 0000:0b:00.0: BAR 3: can't reserve [mem 0xd0000000-0xd1ffffff 64bit pref] anyone an idea how to fix this ?
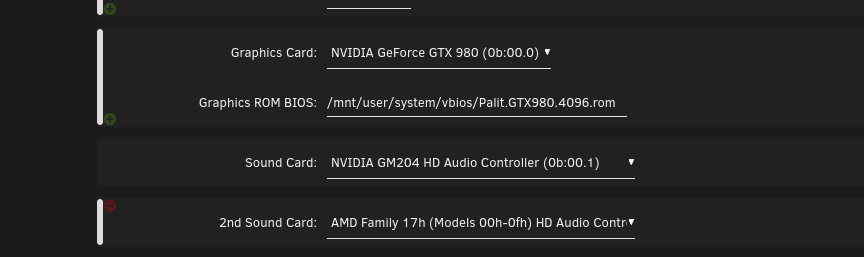
-
ok so i should set it to the Tdie for correctly showing the cpu temp. nice thx
-
i got this mainboard up and running with a 2950x running nicely. but got a question about the temperature measurement which i should use it shows here 2 different temps for the cpu. It says 32.5C and the k10temp tctl = 58 C when i check the ipmi it says CPU 58C.
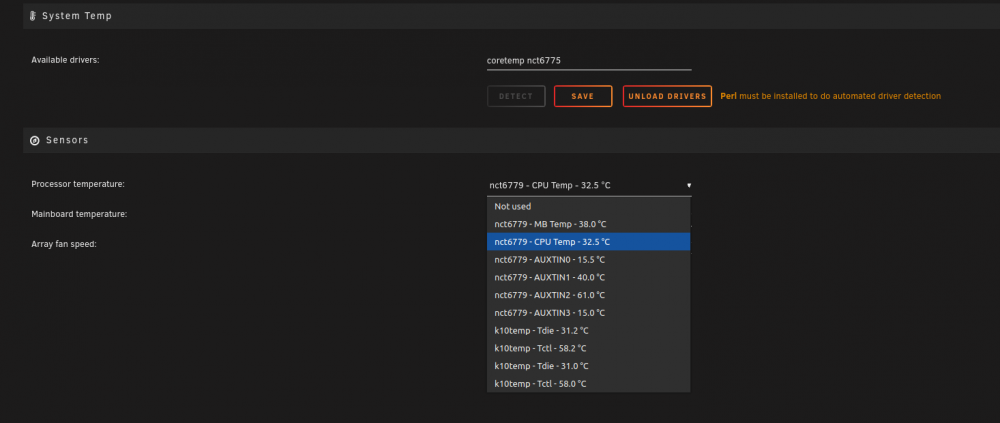
-
Currently 16 gb DDR3. New setup soon to be build will have 64 gb ddr4 ECC. All parts are in except the CPU.
-
Currently 38 tb will be more when i get my new system running. Going to replace the 3 tbs for larger ones and i can add more in the new one.
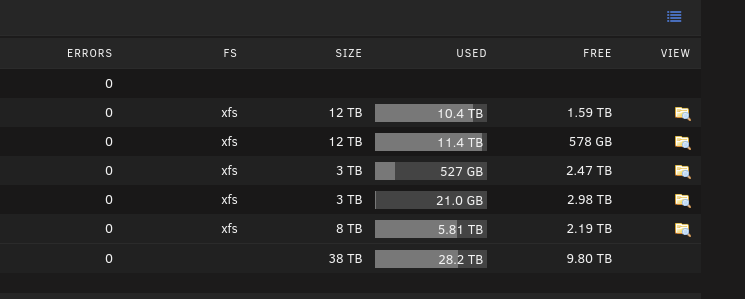
-
sounds a very big hassle? How to do that ? or is there a other way.
-
Found 25 files with BLAKE2 hash key mismatch warning BLAKE2 hash key mismatch (updated), blah/blah/aom-u-move/kowai/catacodec.data was modified BLAKE2 hash key mismatch (updated), blah/blah/aom-u-move/kowai/local_files.data was modified i had in the plugin excluded teh aom-u-move directory but it still shows the directory under that. these files change often zo i excluded the whole directory but that didnt seems to work.
-
That it will takes WAY to much time. for i guess very little performance increase.
-
i only tested my 2x 12 tb ones dont want to defrag those. fs_db> frag actual 52445, ideal 50533, fragmentation factor 3.65% Note, this number is largely meaningless. Files on this filesystem average 1.04 extents per file xfs_db> frag -d actual 1629, ideal 1510, fragmentation factor 7.31% Note, this number is largely meaningless. Files on this filesystem average 1.08 extents per file xfs_db> frag -f actual 50816, ideal 49023, fragmentation factor 3.53% Note, this number is largely meaningless. Files on this filesystem average 1.04 extents per file xfs_db> frag actual 49875, ideal 42765, fragmentation factor 14.26% Note, this number is largely meaningless. Files on this filesystem average 1.17 extents per file xfs_db> frag -d actual 1514, ideal 1471, fragmentation factor 2.84% Note, this number is largely meaningless. Files on this filesystem average 1.03 extents per file xfs_db> frag -f actual 48359, ideal 41292, fragmentation factor 14.61% Note, this number is largely meaningless. Files on this filesystem average 1.17 extents per file
-
got a question i had a few blake2 corruptions now i replaced those files. and did a normal check which says ok. SO i did a check with the plugin again it took 19 hours to do all 45k files. The check says finish and it has less corruptions now but when i check the disk2.export.20201011.bad.log it still shows the old count and the date is also not updated on it. While it finsh the check files this morning. Is there something i missed why it didnt updated this bad.log file? i also dont see any other with a newer date.
-
Pfsense, on a intel I7 box with extra network connections.
-
Icon URL:
-
The plugin "Fix common problems" said the letsencrypt has a error because the name change to SWAG. and ask it it could change a It changed a url of something. So i click ok change it. and it changed the logo etc and some text. Tried a few times and it gave a error that a certificate could not renewed while everything it said was correct. it did said success ful added dns records etc ( using dnsplugin) and also removed it again but still fail and the docker didnt want to start. It also said “Plugin legacy name certbot-dns-transip:dns-transip may be removed in a future version. Please use dns-transip instead. “ I think i use the correct plugin. So I clicked apply again for the Xth time so that refresh/rebuild the docker. Finally after the XTh time ( lost count) all error were gone and the certificate works and the docker finally works. Only thing it shows in the log is the following error tho but everything seems to work again it does not break the container just yet.. nginx: [alert] detected a LuaJIT version which is not OpenResty's; many optimizations will be disabled and performance will be compromised (see https://github.com/openresty/luajit2 for OpenResty's LuaJIT or, even better, consider using the OpenResty releases from https://openresty.org/en/download.html)
-
I do like the recycle plugin but i got 1 thing where it does not get into the recycle bin. Might be a setting. But here it is. my work station OS is ubuntu and if i remove a file there from a share it gets nicely put in the Bin and i can see it retrieve it etc. Now i have on unraid a ubuntu VM. In that ubuntu VM i have made a " Unraid Mount tag: " and i added that in the VM so the VM sees that directory as 1 of its own directory so i have direct access on that share inside the VM. https://wiki.qemu.org/Documentation/9psetup Now if i remove a file in the VM on that share its just gone. Is this a setting i can set or anything?
-
i do like graphs and lines
-
kinda a prtg ish something or 1 of the other tools.
-
i did use the previous apps section. i found the file with some settings and did it manually
-
1 of the docker settings got messed up and failed to update etc so it was removed when i readd it all settings on the docker are gone. I did a restore of yesterday and checked but still all settings of that docker are gone. i even tried the backup of the day before yesterday. Some problem.. How can i get those settings back, are they in a file or so. the files it self in the docker are still there just not the settings when you edit the image.
-
If your parity the biggest Disk in the array ? i think if the parity is not the Biggest disk i can go wrong. i might be wrong so feel free to correct me.
-
How do i use it with unraid gui?. With compose i can follow the examples to add it.
-
I turned on Privileged and it works for the website and bitwarden. bitwarden only on the login part it still shows the site.


