




dalben
Members
-
Joined
-
Last visited
Everything posted by dalben
-
I have a small NAS that wakes up at 2am and shuts down at 7am. I setup a mount in Unassigned Devices and it works well. I would see it /mnt/remotes. This morning it wasn't mounted. I check Unassigned devices, the green dot was there but I needed to manually mount. I check the settings and automount was on, as was sharing. Is Unassigned Devices designed to remote in this scenario, or was I assuming it does something it doesn't do?
-
now I feel stupid. Thanks for pointing out the obvious I just didn't see. I am after yq, the yaml version of the jq parser.
-
Not sure if I asked this previously but this has me stumped. root@tdm:~# un-get search yq Please wait, performing search... Found the following package(s) for your search 'yq' in repositories: pyquery-2.0.1 PyQt-builder-1.19.0 PyQt5-5.15.11 PyQt5_sip-12.17.1 python-doxyqml-0.5.3 root@tdm:~# un-get install yq Can't find package(s): yq! What am I doing wrong?
-
I did a bit more digging around and it does seem to be my end. Edge gives me this behaviour. Edge incognito, Chrome and Chrome Incognito display the correct behavior. I'll keep hunting at my end until it's sorted. Just odd it only started happening after the 7.2 upgrade
-
Dunno then. All I can tell you is that on 7.1.4 (I think) it worked. After the upgrade to 7.2 it didn't. The console errors show its trying to pull data https://servername and it fails. I edit the command in dev mode to http://servernane and it works. When I go via caddy reverse proxy to the https URL, it works. Thats about the extent of my technical knowledge.
-
OK, looking at those logs I worked out what it is. Connect to Unraid Web UI with HTTPS and all is good. When I connect with HTTP I get the Please wait message. When I'm at home I normally hit http://servername to reach the Web UI. The Dashboard tile seem to hardcode https://url when trying to pull data rather than use what, which fails when someone is accessing without a cert. From my console I see the gpustat has the same issue.
-
Not sure if this has already been reported or not. Upgraded to 7.2 today. NUT seems to work fine but the dashboard tile never loads. It's been like that for about 4 hours now. I have disabled it and re-enabled it without much luck.

-
I ended up, using the LSIO/ffmpeg container. Standalone ffmpeg that only starts up when you call it.
-
I tried that, and for some reason un-get thinks it' already installed, but it's not. a "find / -type f -name 'ffmpeg' 2>/dev/null" found nothing. I guess I need to find a docker with it in there and easy to use
-
Transmission_VPN has anyone been able to add an External Providers config thats available on haugene/transmission-openvpn? I want to add the ExpressVPN config but I can't workout how to add that to the current template. I tried copying the deluge-vpn instructions but that seems quite a different setup.
-
Just set this up and it looks good. I can reach it internally but when I try to reach it externally, via Nginx Proxy Manager reverse proxy, I get 500 Errors. Anyone else see this? Most like misconfigured on my side but most of the options have been tried. Dug around a bit and the logs show *10086 invalid port in upstream as the issue. Not sure what else to try. The config files look like the others. *All sorted now. BDU error. One does not need http:// when nginx requires only the host address.
-
Agree, another Unraid user here and I like being able to see each docker individually on reserved IPs. A quick trial with IPvlan had the Unraid console completely confused and close to unusable for Docker listing.
-
I found these entries in /boot/config/ident/cfg USE_WSD="yes" WSD_OPT="" WSD2_OPT="-4 -i br0" Can anyone tell me what they are for or what they do? I've searched the forum with no luck
-
But why would samba want br0? That doesn't make much sense to me.
-
Running 6.12.0 RC5 but I'm not sure if this is release related or some other random warning in my syslog. The only related changes I can think of is I reconfigured my network settings, removing bro from eth0, and moving all Dockers to a second nic which is configured with br1. I checked smb-extra.cfg but everything in there is commented out. Diagnostics attached May 5 12:51:36 tdm ool www[32701]: /usr/local/emhttp/plugins/dynamix/scripts/emcmd 'cmdStatus=Apply' May 5 12:51:36 tdm emhttpd: Starting services... May 5 12:51:36 tdm emhttpd: shcmd (5160097): /etc/rc.d/rc.samba restart May 5 12:51:38 tdm root: Starting Samba: /usr/sbin/smbd -D May 5 12:51:38 tdm root: /usr/sbin/nmbd -D May 5 12:51:38 tdm root: /usr/sbin/wsdd2 -d -4 -i br0 May 5 12:51:38 tdm root: Bad interface 'br0' May 5 12:51:38 tdm root: May 5 12:51:38 tdm root: WSDD and LLMNR daemon May 5 12:51:38 tdm root: Usage: wsdd2 [options] May 5 12:51:38 tdm root: -h this message May 5 12:51:38 tdm root: -d become daemon May 5 12:51:38 tdm root: -4 IPv4 only May 5 12:51:38 tdm root: -6 IPv6 only May 5 12:51:38 tdm root: -u UDP only May 5 12:51:38 tdm root: -t TCP only May 5 12:51:38 tdm root: -l LLMNR only May 5 12:51:38 tdm root: -w WSDD only May 5 12:51:38 tdm root: -L increment LLMNR debug level (0) May 5 12:51:38 tdm root: -W increment WSDD debug level (0) May 5 12:51:38 tdm root: -i <interface> reply only on this interface (br0) May 5 12:51:38 tdm root: -H <name> set host name (tdm) May 5 12:51:38 tdm root: -A "name list" set host aliases () May 5 12:51:38 tdm root: -N <name> set netbios name (TDM) May 5 12:51:38 tdm root: -B "name list" set netbios aliases () May 5 12:51:38 tdm root: -G <name> set workgroup (RADIKAL) May 5 12:51:38 tdm root: -b "key1:val1,key2:val2,..." boot parameters: May 5 12:51:38 tdm root: vendor: unknown May 5 12:51:38 tdm root: model: unknown May 5 12:51:38 tdm root: serial: 0 May 5 12:51:38 tdm root: sku: unknown May 5 12:51:38 tdm root: vendorurl: (null) May 5 12:51:38 tdm root: modelurl: (null) May 5 12:51:38 tdm root: presentationurl: (null) May 5 12:51:38 tdm root: /usr/sbin/winbindd -D May 5 12:51:38 tdm emhttpd: shcmd (5160101): /etc/rc.d/rc.avahidaemon restart tdm-diagnostics-20230506-0959.zip
-
From what I can work out, with Docker setup to Host Access to custom networks, you get a second network appearing on the same Server IP address. I have 2 NICS, one for the docker vlan one for the server management, both show two networks/MAC addresses at the same IP. Hasn't degregaded performance. What would be nice, and I'm not sure if possible, is to fix/lock a MAC address in for br0 so that my network controller can label it properly. It seems to change at every reboot. It's not a performance thing or show stopper, just helps my OCD cope with my network controller better.
-
A quick that must probably has been answered before but my search fu isn't working today. Due to a catastrophic mobo error, I have to quickly replace my board and get my server up again quickly. The board that's arriving is an ASUS TUF B365M-Plus Gaming. After recently upgrading to 18Tb disks I can use the 6 onboard SATA + 2xM.2 with ports to spare. I also have an LSI 9211-i8 controller that's in the current dead server and a recently purchased 2nd hand Dell HBA, which is an LSI 9207-i8. What's going to give me the best performance, all on the onboard SATA, or on an LSI running on the x4 PCIe slot? Would using the x16 slot make a difference? If we're talking miniscule differences I might go the LSA simply because the cabling will be neater. Any advice would be most welcome.
-
@JorgeB All reformatted and finished playing shuffle files. No more errors. Thanks
-
Thanks. No errors prior to NUT losing the USB connection.
-
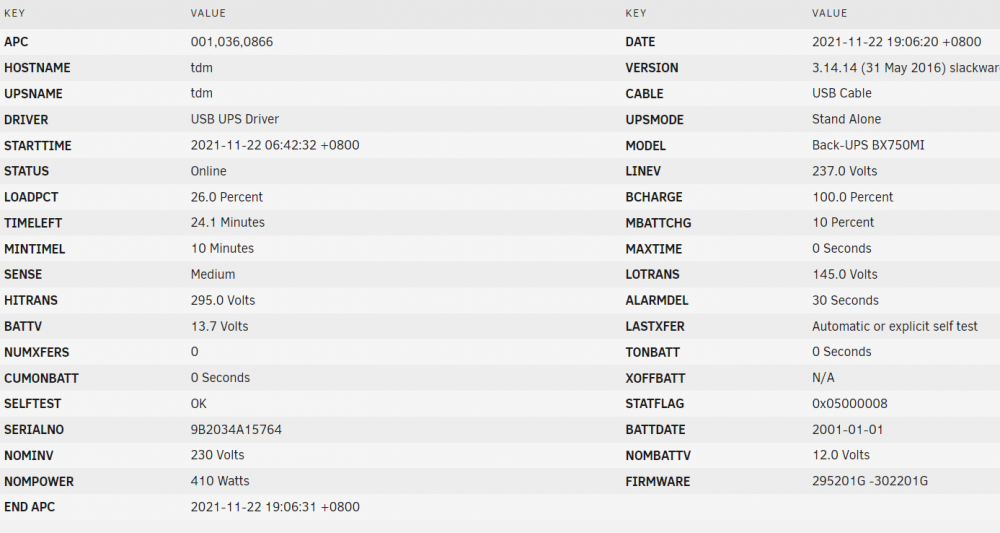
Still getting this error with the latest update on my APC MODEL Back-UPS BX750MI. Once it loses connection I need to pull the USB cable and plug it in again for it to work. Tried switching to the native Unraid UPS monitor while in this states and it complains of connection error. After resetting the USB cable the Unraid UPS monitor works fine without any issues.
-
Thanks @JorgeB. Appreciate the troubleshooting and testing. Yeah, but 18Gb drives for me. What fun
-
I've started seeing parity tuning errors in syslog. Mar 21 06:40:20 tdm root: RTNETLINK answers: File exists Mar 21 06:40:20 tdm Parity Check Tuning: PHP error_reporting() set to E_ERROR|E_WARNING|E_PARSE|E_CORE_ERROR|E_CORE_WARNING|E_COMPILE_ERROR|E_COMPILE_WARNING|E_USER_ERROR|E_USER_WARNING|E_USER_NOTICE|E_STRICT|E_RECOVERABLE_ERROR|E_USER_DEPRECATED Mar 21 06:40:20 tdm emhttpd: nothing to sync Mar 21 06:40:20 tdm sudo: root : PWD=/ ; USER=root ; COMMAND=/bin/bash -c /usr/local/emhttp/plugins/controlr/controlr -port 2378 -certdir '/boot/config/ssl/certs' -showups Mar 21 06:40:20 tdm sudo: pam_unix(sudo:session): session opened for user root(uid=0) by (uid=0) Mar 21 06:40:20 tdm Parity Check Tuning: PHP error_reporting() set to E_ERROR|E_WARNING|E_PARSE|E_CORE_ERROR|E_CORE_WARNING|E_COMPILE_ERROR|E_COMPILE_WARNING|E_USER_ERROR|E_USER_WARNING|E_USER_NOTICE|E_STRICT|E_RECOVERABLE_ERROR|E_USER_DEPRECATED Mar 21 06:40:21 tdm kernel: eth0: renamed from veth505b9c4 They are fairly regular throughout syslog. Noticed them today while running RC3, still there after RC4
-
Not sure if it was addressed in RC4 and if so there was any expectation of the error going away, but it's still there Mar 21 06:40:06 tdm kernel: XFS (md1): Mounting V5 Filesystem Mar 21 06:40:06 tdm kernel: XFS (md1): Ending clean mount Mar 21 06:40:06 tdm emhttpd: shcmd (34): xfs_growfs /mnt/disk1 Mar 21 06:40:06 tdm kernel: xfs filesystem being mounted at /mnt/disk1 supports timestamps until 2038 (0x7fffffff) Mar 21 06:40:06 tdm root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Mar 21 06:40:06 tdm root: meta-data=/dev/md1 isize=512 agcount=32, agsize=137330687 blks Mar 21 06:40:06 tdm root: = sectsz=512 attr=2, projid32bit=1 Mar 21 06:40:06 tdm root: = crc=1 finobt=1, sparse=1, rmapbt=0 Mar 21 06:40:06 tdm root: = reflink=1 bigtime=0 inobtcount=0 Mar 21 06:40:06 tdm root: data = bsize=4096 blocks=4394581984, imaxpct=5 Mar 21 06:40:06 tdm root: = sunit=1 swidth=32 blks Mar 21 06:40:06 tdm root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 Mar 21 06:40:06 tdm root: log =internal log bsize=4096 blocks=521728, version=2 Mar 21 06:40:06 tdm root: = sectsz=512 sunit=1 blks, lazy-count=1 Mar 21 06:40:06 tdm root: realtime =none extsz=4096 blocks=0, rtextents=0 Mar 21 06:40:06 tdm kernel: XFS (md1): EXPERIMENTAL online shrink feature in use. Use at your own risk! Mar 21 06:40:06 tdm emhttpd: shcmd (34): exit status: 1 Mar 21 06:40:06 tdm emhttpd: shcmd (35): mkdir -p /mnt/disk2 Mar 21 06:40:06 tdm emhttpd: shcmd (36): mount -t xfs -o noatime,nouuid /dev/md2 /mnt/disk2 Mar 21 06:40:06 tdm kernel: XFS (md2): Mounting V5 Filesystem Mar 21 06:40:07 tdm kernel: XFS (md2): Ending clean mount Mar 21 06:40:07 tdm kernel: xfs filesystem being mounted at /mnt/disk2 supports timestamps until 2038 (0x7fffffff) Mar 21 06:40:07 tdm emhttpd: shcmd (37): xfs_growfs /mnt/disk2 Mar 21 06:40:07 tdm root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Mar 21 06:40:07 tdm root: meta-data=/dev/md2 isize=512 agcount=32, agsize=137330687 blks Mar 21 06:40:07 tdm root: = sectsz=512 attr=2, projid32bit=1 Mar 21 06:40:07 tdm root: = crc=1 finobt=1, sparse=1, rmapbt=0 Mar 21 06:40:07 tdm root: = reflink=1 bigtime=0 inobtcount=0 Mar 21 06:40:07 tdm root: data = bsize=4096 blocks=4394581984, imaxpct=5 Mar 21 06:40:07 tdm root: = sunit=1 swidth=32 blks Mar 21 06:40:07 tdm root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 Mar 21 06:40:07 tdm root: log =internal log bsize=4096 blocks=521728, version=2 Mar 21 06:40:07 tdm root: = sectsz=512 sunit=1 blks, lazy-count=1 Mar 21 06:40:07 tdm root: realtime =none extsz=4096 blocks=0, rtextents=0 Mar 21 06:40:07 tdm emhttpd: shcmd (37): exit status: 1 Mar 21 06:40:07 tdm emhttpd: shcmd (38): mkdir -p /mnt/disk3 Mar 21 06:40:07 tdm emhttpd: shcmd (39): mount -t xfs -o noatime,nouuid /dev/md3 /mnt/disk3 Mar 21 06:40:07 tdm kernel: XFS (md3): Mounting V5 Filesystem Mar 21 06:40:07 tdm kernel: XFS (md3): Ending clean mount Mar 21 06:40:07 tdm kernel: xfs filesystem being mounted at /mnt/disk3 supports timestamps until 2038 (0x7fffffff) Mar 21 06:40:07 tdm emhttpd: shcmd (40): xfs_growfs /mnt/disk3 Mar 21 06:40:07 tdm root: meta-data=/dev/md3 isize=512 agcount=32, agsize=30523583 blks Mar 21 06:40:07 tdm root: = sectsz=512 attr=2, projid32bit=1 Mar 21 06:40:07 tdm root: = crc=1 finobt=1, sparse=1, rmapbt=0 Mar 21 06:40:07 tdm root: = reflink=1 bigtime=0 inobtcount=0 Mar 21 06:40:07 tdm root: data = bsize=4096 blocks=976754633, imaxpct=5 Mar 21 06:40:07 tdm root: = sunit=1 swidth=32 blks Mar 21 06:40:07 tdm root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 Mar 21 06:40:07 tdm root: log =internal log bsize=4096 blocks=476930, version=2 Mar 21 06:40:07 tdm root: = sectsz=512 sunit=1 blks, lazy-count=1 Mar 21 06:40:07 tdm root: realtime =none extsz=4096 blocks=0, rtextents=0 Mar 21 06:40:07 tdm emhttpd: shcmd (41): mkdir -p /mnt/cache
-
-
Who would know then? And would that person know if all large drives formatted with 6.10 need to be reformatted or just the one throwing the error?




