




aurevo
Members
-
Joined
-
Last visited
Everything posted by aurevo
-
The disk was displayed as missing, after restart I could select it back fot the slot and than it said I have to format it. The disk long before that had SMART errors, so I thought it would be a good idea to replace it. Yes, I fomated the disk and started rebuilding. After that I recognised that it was incredible slow in rebuilding and that the disk was empty, which was admittedly a mistake on my part. What would be the most appropriate steps to take to try to access my data? In addition, the hard disks are encrypted, does this make a difference?
-
That was on the replaced (new) disk. I still have the old disk, but that one was faulty I think so I replaced it.
-
Yes, system said I had to format it to use it again, so I did that. Would that not be the right step? Any chance to get back the data?
-
Hello everyone, The other day I noticed on my backup system that a hard disk was showing errors. After a restart, the hard disk was shown as ready for formatting. Today I replaced the hard disk and the parity recovery started. Now the log shows me dozens of errors and a speed of less than 1 MB/s when restoring. And I think the disk I replaced has lot more free space than the disk before. Is there anything left to recover or what is the best way to proceed? I still have the old disk. Thank you! backup-diagnostics-20231222-1346.zip
-
Hello, after a power failure during the night I just rebooted the system and all docker containers are gone. The Docker image is still there and I can't see from the log why this would be corrupt or what could be the reason that the containers are all no longer displayed. Is there any way I can avoid this behavior in the future, it is very idle to create a new image every time and restore all the containers, even though I am familiar with the procedure and it generally works fine. For me, the question is whether the image is really corrupt, or I can still save this. If it is not salvageable, could I prevent such behavior by switching from vdisk to directory? Otherwise I am grateful for any help or tips. tower-diagnostics-20230912-1000.zip
-
I have now rebuilt the image and am currently reinstalling the containers. Can you tell from the logs or other information why the system hung, or could this also be related to the corrupt Docker image?
-
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_ifree 18672, counted 24267 sb_fdblocks 118931100, counted 100300833 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 inode 47039578 - bad extent starting block number 4494803742481198, offset 2280176868672639 correcting nextents for inode 47039578 bad data fork in inode 47039578 cleared inode 47039578 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 entry "docker.img" in shortform directory 47039576 references free inode 47039578 junking entry "docker.img" in directory inode 47039576 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (995:311495) is ahead of log (1:2). Format log to cycle 998. done Now I can ls the /mnt/cache again but all my docker container are gone. Any chance to reverse the change or to rebuild it at the state before the corruption? docker.img itself is at the correct place.
-
Hi, after the system ran for weeks without a single problem, unfortunately since a few days the problems are piling up and I have no starting point where to start looking. After I repaired my Plex database and tried to browse the media library, the web interface of the UnRAID was no longer accessible. I could still connect via SSH, but I couldn't really do anything anymore. Even diagnostics retourned nothing, or just ran without end. The whole system seems to hang, I can't stop the Docker service and I can't access the webinterface of any Docker. Attached is the diagnostics from yesterday, today unfortunately I could not create in the webinterface, nor via CLI. I could only copy the complete syslog from flash. From this a short excerpt, maybe this has relevance. Aug 29 15:25:04 Tower kernel: ------------[ cut here ]------------ Aug 29 15:25:04 Tower kernel: WARNING: CPU: 0 PID: 20516 at net/netfilter/nf_nat_core.c:594 nf_nat_setup_info+0x8c/0x7d1 [nf_nat] Aug 29 15:25:04 Tower kernel: Modules linked in: vhost_net vhost tap kvm_intel kvm md_mod xt_mark xt_comment bluetooth ecdh_generic ecc udp_diag macvlan veth xt_nat nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter xt_CHECKSUM xt_MASQUERADE xt_conntrack ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 tun vhost_iotlb nvidia_uvm(PO) xfs cmac cifs asn1_decoder cifs_arc4 cifs_md4 oid_registry dns_resolver dm_crypt dm_mod zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) i915 drm_buddy i2c_algo_bit ttm drm_display_helper intel_gtt agpgart tcp_diag inet_diag ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs af_packet 8021q garp mrp bridge stp llc nvidia_drm(PO) nvidia_modeset(PO) intel_rapl_msr intel_rapl_common iosf_mbi x86_pkg_temp_thermal intel_powerclamp coretemp nvidia(PO) crct10dif_pclmul crc32_pclmul crc32c_intel Aug 29 15:25:04 Tower kernel: ghash_clmulni_intel video sha512_ssse3 aesni_intel drm_kms_helper crypto_simd cryptd rapl drm mpt3sas i2c_i801 intel_cstate mei_me backlight i2c_smbus intel_wmi_thunderbolt mxm_wmi ahci syscopyarea raid_class sysfillrect input_leds sysimgblt intel_uncore e1000e i2c_core mei led_class libahci scsi_transport_sas fb_sys_fops wmi button unix [last unloaded: kvm] Aug 29 15:25:04 Tower kernel: CPU: 0 PID: 20516 Comm: kworker/u48:19 Tainted: P D W O 6.1.38-Unraid #2 Aug 29 15:25:04 Tower kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X99 Extreme4, BIOS P3.80 04/06/2018 Aug 29 15:25:04 Tower kernel: Workqueue: events_unbound macvlan_process_broadcast [macvlan] Aug 29 15:25:04 Tower kernel: RIP: 0010:nf_nat_setup_info+0x8c/0x7d1 [nf_nat] Aug 29 15:25:04 Tower kernel: Code: a8 80 75 26 48 8d 73 58 48 8d 7c 24 20 e8 18 1b 43 00 48 8d 43 0c 4c 8b bb 88 00 00 00 48 89 44 24 18 eb 54 0f ba e0 08 73 07 <0f> 0b e9 75 06 00 00 48 8d 73 58 48 8d 7c 24 20 e8 eb 1a 43 00 48 Aug 29 15:25:04 Tower kernel: RSP: 0018:ffffc90000003c78 EFLAGS: 00010282 Aug 29 15:25:04 Tower kernel: RAX: 0000000000000180 RBX: ffff8887bbcb5300 RCX: ffff888173a62900 Aug 29 15:25:04 Tower kernel: RDX: 0000000000000000 RSI: ffffc90000003d5c RDI: ffff8887bbcb5300 Aug 29 15:25:04 Tower kernel: RBP: ffffc90000003d40 R08: 00000000900a0a0a R09: 0000000000000000 Aug 29 15:25:04 Tower kernel: R10: 0000000000000098 R11: 0000000000000000 R12: ffffc90000003d5c Aug 29 15:25:04 Tower kernel: R13: 0000000000000000 R14: ffffc90000003e40 R15: 0000000000000001 Aug 29 15:25:04 Tower kernel: FS: 0000000000000000(0000) GS:ffff88905f800000(0000) knlGS:0000000000000000 Aug 29 15:25:04 Tower kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Aug 29 15:25:04 Tower kernel: CR2: 000014d41cb5069c CR3: 000000000420a002 CR4: 00000000001706f0 Aug 29 15:25:04 Tower kernel: Call Trace: Aug 29 15:25:04 Tower kernel: <IRQ> Aug 29 15:25:04 Tower kernel: ? __warn+0xab/0x122 Aug 29 15:25:04 Tower kernel: ? report_bug+0x109/0x17e Aug 29 15:25:04 Tower kernel: ? nf_nat_setup_info+0x8c/0x7d1 [nf_nat] Aug 29 15:25:04 Tower kernel: ? handle_bug+0x41/0x6f Aug 29 15:25:04 Tower kernel: ? exc_invalid_op+0x13/0x60 Aug 29 15:25:04 Tower kernel: ? asm_exc_invalid_op+0x16/0x20 Aug 29 15:25:04 Tower kernel: ? nf_nat_setup_info+0x8c/0x7d1 [nf_nat] Aug 29 15:25:04 Tower kernel: ? nf_nat_setup_info+0x44/0x7d1 [nf_nat] Aug 29 15:25:04 Tower kernel: ? xt_write_recseq_end+0xf/0x1c [ip_tables] Aug 29 15:25:04 Tower kernel: ? __local_bh_enable_ip+0x56/0x6b Aug 29 15:25:04 Tower kernel: ? ipt_do_table+0x57a/0x5bf [ip_tables] Aug 29 15:25:04 Tower kernel: ? __wake_up_common_lock+0x88/0xbb Aug 29 15:25:04 Tower kernel: ? xt_write_recseq_end+0xf/0x1c [ip_tables] Aug 29 15:25:04 Tower kernel: __nf_nat_alloc_null_binding+0x66/0x81 [nf_nat] Aug 29 15:25:04 Tower kernel: nf_nat_inet_fn+0xc0/0x1a8 [nf_nat] Aug 29 15:25:04 Tower kernel: nf_nat_ipv4_local_in+0x2a/0xaa [nf_nat] Aug 29 15:25:04 Tower kernel: nf_hook_slow+0x3d/0x96 Aug 29 15:25:04 Tower kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Aug 29 15:25:04 Tower kernel: NF_HOOK.constprop.0+0x79/0xd9 Aug 29 15:25:04 Tower kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Aug 29 15:25:04 Tower kernel: __netif_receive_skb_one_core+0x77/0x9c Aug 29 15:25:04 Tower kernel: process_backlog+0x8c/0x116 Aug 29 15:25:04 Tower kernel: __napi_poll.constprop.0+0x2b/0x124 Aug 29 15:25:04 Tower kernel: net_rx_action+0x159/0x24f Aug 29 15:25:04 Tower kernel: __do_softirq+0x129/0x288 Aug 29 15:25:04 Tower kernel: do_softirq+0x7f/0xab Aug 29 15:25:04 Tower kernel: </IRQ> Aug 29 15:25:04 Tower kernel: <TASK> Aug 29 15:25:04 Tower kernel: __local_bh_enable_ip+0x4c/0x6b Aug 29 15:25:04 Tower kernel: netif_rx+0x52/0x5a Aug 29 15:25:04 Tower kernel: macvlan_broadcast+0x10a/0x150 [macvlan] Aug 29 15:25:04 Tower kernel: ? _raw_spin_unlock+0x14/0x29 Aug 29 15:25:04 Tower kernel: macvlan_process_broadcast+0xbc/0x12f [macvlan] Aug 29 15:25:04 Tower kernel: process_one_work+0x1ab/0x295 Aug 29 15:25:04 Tower kernel: worker_thread+0x18b/0x244 Aug 29 15:25:04 Tower kernel: ? rescuer_thread+0x281/0x281 Aug 29 15:25:04 Tower kernel: kthread+0xe7/0xef Aug 29 15:25:04 Tower kernel: ? kthread_complete_and_exit+0x1b/0x1b Aug 29 15:25:04 Tower kernel: ret_from_fork+0x22/0x30 Aug 29 15:25:04 Tower kernel: </TASK> Aug 29 15:25:04 Tower kernel: ---[ end trace 0000000000000000 ]--- Aug 29 15:27:15 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1046853 Aug 29 15:29:47 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1048894 Aug 29 15:31:23 Tower sshd[9323]: Connection closed by 10.10.10.77 port 51686 Aug 29 15:31:23 Tower sshd[9323]: Close session: user root from 10.10.10.77 port 51686 id 0 Aug 29 15:31:23 Tower sshd[9323]: pam_unix(sshd:session): session closed for user root Aug 29 15:31:23 Tower sshd[9323]: pam_elogind(sshd:session): Failed to release session: Interrupted system call Aug 29 15:31:23 Tower sshd[9323]: Transferred: sent 218648, received 11400 bytes Aug 29 15:31:23 Tower sshd[9323]: Closing connection to 10.10.10.77 port 51686 Aug 29 15:32:18 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1051096 Aug 29 15:32:48 Tower webGUI: Successful login user root from 10.10.10.155 Aug 29 15:34:25 Tower sshd[1560]: Connection from 10.10.10.77 port 52543 on 10.10.10.11 port 22 rdomain "" Aug 29 15:34:28 Tower sshd[1560]: Postponed keyboard-interactive for root from 10.10.10.77 port 52543 ssh2 [preauth] Aug 29 15:34:30 Tower sshd[1560]: Postponed keyboard-interactive/pam for root from 10.10.10.77 port 52543 ssh2 [preauth] Aug 29 15:34:30 Tower sshd[1560]: Accepted keyboard-interactive/pam for root from 10.10.10.77 port 52543 ssh2 Aug 29 15:34:30 Tower sshd[1560]: pam_unix(sshd:session): session opened for user root(uid=0) by (uid=0) Aug 29 15:34:30 Tower sshd[1560]: Starting session: shell on pts/2 for root from 10.10.10.77 port 52543 id 0 Aug 29 15:37:22 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1054479 Aug 29 15:38:57 Tower dnsmasq[12988]: exiting on receipt of SIGTERM Aug 29 15:42:26 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1057614 Aug 29 15:43:50 Tower shutdown[25317]: shutting down for system reboot Aug 29 15:44:11 Tower sshd[1560]: Connection closed by 10.10.10.77 port 52543 Aug 29 15:44:11 Tower sshd[1560]: Close session: user root from 10.10.10.77 port 52543 id 0 Aug 29 15:44:11 Tower sshd[1560]: pam_unix(sshd:session): session closed for user root Aug 29 15:44:11 Tower sshd[1560]: Transferred: sent 39928, received 6680 bytes Aug 29 15:44:11 Tower sshd[1560]: Closing connection to 10.10.10.77 port 52543 Aug 29 15:47:29 Tower kernel: CIFS: VFS: \\10.10.10.21\backup Close unmatched open for MID:1060811 and another part of the log with errors: After hard reboot I got the error "/mnt/cache/system/docker/docker.img" Path does not exist. cd /mnt/cache and ls followiung error: /bin/ls: cannot open directory '.': Input/output error Trying to repair xfs says: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. tower-diagnostics-20230828-1151.zip tower-diagnostics-20230829-1624.zip
-
Should this be all? Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... invalid start block 143526221 in record 124 of bno btree block 0/182773 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 clearing reflink flag on inodes when possible Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done It seems to work now, after checking the filesystem. At least the Dockers can be updated again.
-
Hello, In the older of the two log files you can see that there were constant error messages in the log like this one: Tower kernel: BTRFS error (device loop2: state EA): parent transid verify failed on logical 208311271424 mirror 1 wanted 4372964 found 4372437 After that I restarted the array/tower to look if the error disappears. In maintenance mode there were no errors in the file system check for cache_appdata ssd. In the log everything looked fine to me at first, then I tried to install an app from the community store and got the following error message: "docker: Error response from daemon: error creating temporary lease: write /var/lib/docker/containerd/daemon/io.containerd.metadata.v1.bolt/meta.db: read-only file system: unknown." The new error messages can be seen in the newer of the two log files, copied out again here: Aug 28 11:42:46 Tower kernel: XFS (dm-12): start block 0x88e094d block count 0x8288ffff Aug 28 11:42:46 Tower kernel: XFS (dm-12): Block Freespace BTree record corruption in AG 0 detected! Aug 28 11:42:46 Tower kernel: XFS (dm-12): start block 0x88e094d block count 0x8288ffff Aug 28 11:42:46 Tower kernel: dm-12: writeback error on inode 47039578, offset 109555220480, sector 932647328 Aug 28 11:42:46 Tower kernel: I/O error, dev loop3, sector 0 op 0x1:(WRITE) flags 0x800 phys_seg 0 prio class 2 Aug 28 11:42:46 Tower kernel: BTRFS error (device loop3): bdev /dev/loop3 errs: wr 0, rd 0, flush 1, corrupt 1, gen 0 Aug 28 11:42:46 Tower kernel: BTRFS warning (device loop3): chunk 13631488 missing 1 devices, max tolerance is 0 for writable mount Aug 28 11:42:46 Tower kernel: BTRFS: error (device loop3) in write_all_supers:4369: errno=-5 IO failure (errors while submitting device barriers.) Aug 28 11:42:46 Tower kernel: BTRFS info (device loop3: state E): forced readonly Aug 28 11:42:46 Tower kernel: BTRFS: error (device loop3: state EA) in btrfs_sync_log:3198: errno=-5 IO failure What can I do in this case? tower-diagnostics-20230828-1151.zip tower-diagnostics-20230828-1022.zip
-
For now I stopped container by hand and disabled autostart because I don't really need that container. But today I wanted to stop array because of btrfs errors and now I have the same "cache is busy" error messagen. Logs attached, appreciate your help. tower-diagnostics-20230828-1022.zip
-
So I have to kill the container myself before stopping the array or what can I do to shutdown my Tower? The Docker itself was stopped, so don't know how a container can prevent my Tower from shutdown. It is no option to hard shutdown the device each time and do a parity check.
-
Curiously, there were actually no problems with the container before. Is it possible to force the termination?
-
Hello all, unfortunately I am also one of the people who get the error message "/mnt/cache is busy" when trying to stop the array and shutting down the system. Nothing showed when entering lsof /mnt/cache. umount /dev/loop2 and umount /var/lib/docker not worked. Diagnosis attached. Thanks for you help. tower-diagnostics-20230824-1248.zip
-
Hello, since several days I have the problem that the Filebot docker exits by itself. At least once a day. The logfile does not say why, not even in the system log. I have the same phenomenon with the JDownloader2 docker from jlesage. Also there the Docker terminates by itself without writing an entry in the log. Or I am looking in the wrong place. Maybe someone can find an error in the attached logfile. tower-diagnostics-20220215-1545.zip
-
If you use NVIDIA: Remove -amd from Additional PhoenixMiner Arguments. I do not have "-amd" in my additional settings but every start of the container it tries to load the AMD drivers, what costs a lot of time. Any chance of avoiding that?
-
I don't know, if you have it running now, but here is how to setup it manually on terminal: wget https://packages.slackonly.com/pub/packages/14.2-x86_64/network/autossh/autossh-1.4g-x86_64-1_slonly.txz installpkg autossh-1.4g-x86_64-1_slonly.txz
-
I use the OpenVPN client to bypass a double NAT situation and share my Jellyfin via external VPS. How can I set up a split tunnel in this case so that I can still access the server from the LAN without problems and also ensure access from the Jellyfin to my live TV address? Or is this just a setting thing in the Jellyfin settings?
-
Also 6881 ports are for qBit? What do you have after "--device /dev/net/tun --cap-add=NET_ADMIN"? I only have this two entries, not a third one like you. After configuring like your settings, its hanging at "connecting..." for about 10 minutes or so. Tried both NordLynx and OpenVPN.
-
I am also running into error: Any way to fix it? Tried both NordLynx and OpenVPN.
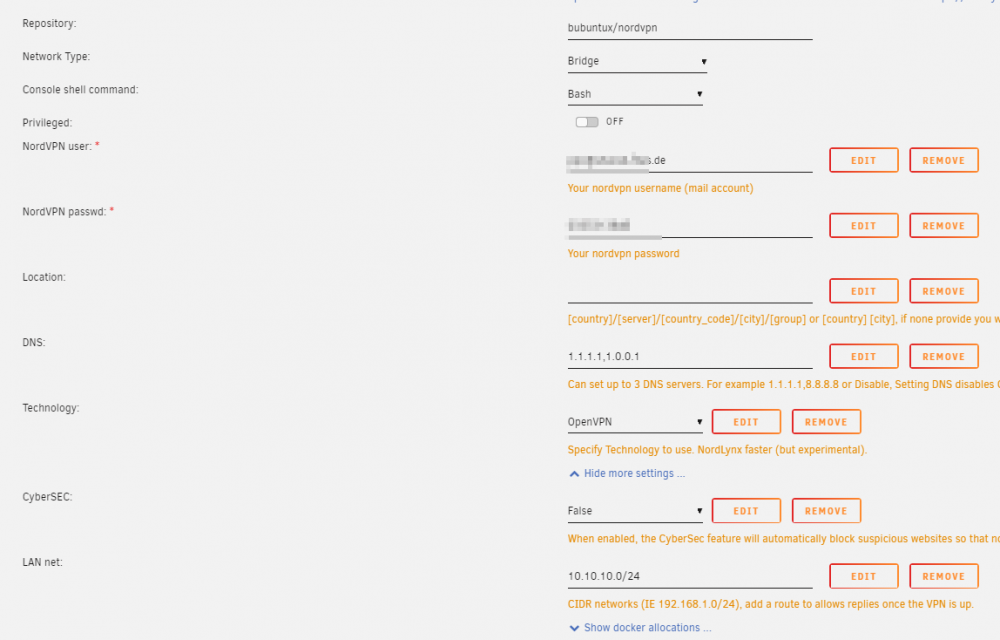
-
Today I ran into the same problem for the first time. Wondering there is still no solution other than restarting NGINX. This temporary fixes the not working dashboard etc. but the log is still on 100%. How to fix it or clear the logs? Logs attached. tower-diagnostics-20210521-0947.zip
-
Hello, part of my media library is in "MicroHD" format, meaning they are movies where the bitrate has been trimmed, but they are still in x264. When Unmanic now converts these files to x265, the files become larger than before and still suffer a loss of quality. Is there any way to prevent this?
-
Hello, I am running into Transcoding loop using ffmpeg CLI option. I have created a library under tdarr_aio version Beta 1.3003 and set the following under transcode options - Video - FFmpeg CLI arguments: "-y -hwaccel cuda -hwaccel_output_format cuda,-map 0:m:language:ger -map -v -map V -max_muxing_queue_size 8192 -c copy -c:v hevc_nvenc -preset fast -err_detect ignore_err" This CLI arguments work also very well, but after transcoding is done, transcoding starts again from the beginning and so on. Any way to stop this behavior?
-
But with your steps you also deleted the unraid.sh you edited right before. Or at which step and which place do you "put in" the unraid.sh file? I also deleted everything from macinabox rm -r /mnt/user/appdata/macinabox rm -r /dev/urandom rm -r /boot/config/plugins/user.scripts/scripts/1_* rm -r Macinabox\ BigSur rm -r /mnt/user/system/custom_ovmf/ rm -r /mnt/user/isos/*.img After the first start I edited unriad.sh from console and restartet. It was loading the basesystem and the log says "Big sure is downloading" but it stucks at "Selected MacOS product" and nothin is downloaded into domains or isos.
-
Even though I am a friend of sarcasm and I appreciate your work and commitment without knowing you, even in this situation you can choose better words and point out to the fellow foroist in a different way that his way is not okay.

