




Mr_Jay84
Members
-
Joined
-
Last visited
Everything posted by Mr_Jay84
-
I can't seem to use tailscale anymore. 2022/02/20 20:57:17 logtail: dial "log.tailscale.io:443" failed: dial tcp: lookup log.tailscale.io on [::1]:53: read udp [::1]:57649->[::1]:53: read: connection refused (in 1ms), trying bootstrap... 2022/02/20 20:57:17 [RATELIMIT] format("[unexpected] peerapi listen(%q) error: %v") (1 dropped) 2022/02/20 20:57:17 [unexpected] peerapi listen("fd7a:115c:a1e0:ab12:4843:cd96:6264:6e26") error: listen tcp6 [fd7a:115c:a1e0:ab12:4843:cd96:6264:6e26]:0: bind: cannot assign requested address 2022/02/20 20:57:17 trying bootstrapDNS("derp2b.tailscale.com", "64.227.106.23") for "log.tailscale.io" ... 2022/02/20 20:57:18 bootstrapDNS("derp2b.tailscale.com", "64.227.106.23") for "log.tailscale.io" = [2600:1f18:429f:9305:4043:217b:512c:f8d4 34.229.201.48] 2022/02/20 20:57:18 logtail: bootstrap dial succeeded 2022/02/20 20:57:18 netmap packet filter: 6 filters 2022/02/20 20:57:18 Taildrop disabled; no state directory 2022/02/20 20:57:18 peerapi starting without Taildrop directory configured 2022/02/20 20:57:18 peerapi: serving on http://MYIPADDRESS:63802 2022/02/20 20:57:18 [unexpected] peerapi listen("fd7a:115c:a1e0:ab12:4843:cd96:6264:6e26") error: listen tcp6 [fd7a:115c:a1e0:ab12:4843:cd96:6264:6e26]:0: bind: cannot assign requested address
-
Thanks for the info mate.
-
How do you install the webserver?
-
Has anyone got a working SWAG reverse proxy conf for the shlink containers?
-
I have the same issue guys. Any suggestions?
-
What's the default StreamLength set at for Clam? I have it running with NextCloud but getting these errors. Warning files_antivirus Failed to write a chunk. Check if Stream Length matches StreamMaxLength in anti virus daemon settings I'm using this tquinnelly/clamav-alpine EDIT: this version works https://hub.docker.com/r/mkodockx/docker-clamav
-
I'm trying to get Mumble server running however I get this error in the log. <W>2022-01-03 18:20:40.112 Initializing settings from /etc/mumble/config.ini (basepath /etc/mumble) <W>2022-01-03 18:20:40.298 MetaParams: TLS cipher preference is "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:AES256-SHA:AES128-SHA" <F>2022-01-03 18:20:40.341 ServerDB: Failed initialization: out of memory Error opening database <X>2022-01-03 18:20:40.420 SSL: OpenSSL version is 'OpenSSL 1.0.2k 26 Jan 2017' <W>2022-01-03 18:20:40.422 Initializing settings from /etc/mumble/config.ini (basepath /etc/mumble) <W>2022-01-03 18:20:40.606 MetaParams: TLS cipher preference is "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:AES256-SHA:AES128-SHA" <F>2022-01-03 18:20:40.642 ServerDB: Failed initialization: out of memory Error opening database <X>2022-01-03 18:39:13.454 SSL: OpenSSL version is 'OpenSSL 1.0.2k 26 Jan 2017' <W>2022-01-03 18:39:13.455 Initializing settings from /etc/mumble/config.ini (basepath /etc/mumble) <W>2022-01-03 18:39:13.568 MetaParams: TLS cipher preference is "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:AES256-SHA:AES128-SHA" <F>2022-01-03 18:39:13.589 ServerDB: Failed initialization: out of memory Error opening database <X>2022-01-03 18:39:13.639 SSL: OpenSSL version is 'OpenSSL 1.0.2k 26 Jan 2017' <W>2022-01-03 18:39:13.640 Initializing settings from /etc/mumble/config.ini (basepath /etc/mumble) <W>2022-01-03 18:39:13.755 MetaParams: TLS cipher preference is "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:AES256-SHA:AES128-SHA" <F>2022-01-03 18:39:13.776 ServerDB: Failed initialization: out of memory Error opening database
-
Still crashing although after 4 days. Looks like new CPUs is the only way forward.
-
So setting the intel driver for Performance mode has made it more stable. It was crashing every 12 hours at one time.

-
It's strange that the issue has gradually got worse over the last two years. It was fair reliable at one stage. Let's see how the performance tweak goes. If not, new CPU time.
-
Its an ES E5-2658A v3 CPU. Possibly why i'm having these issues lol. I've installed the Tips and Tweaks plugin and set it for Performance mode, hopefully this will help. Replacement with retail chips might be my only option. I've posted screen shots of the BIOS options. Nothing seems to make any difference.
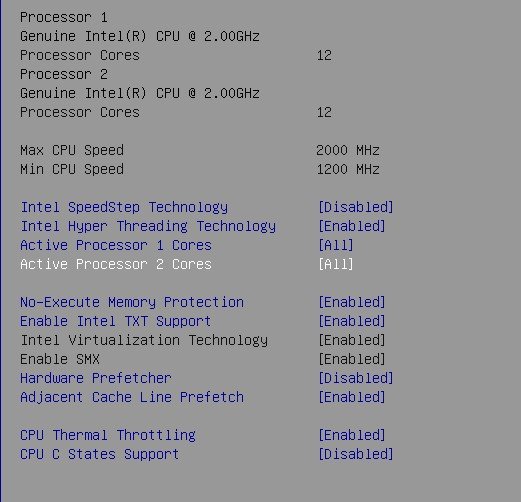
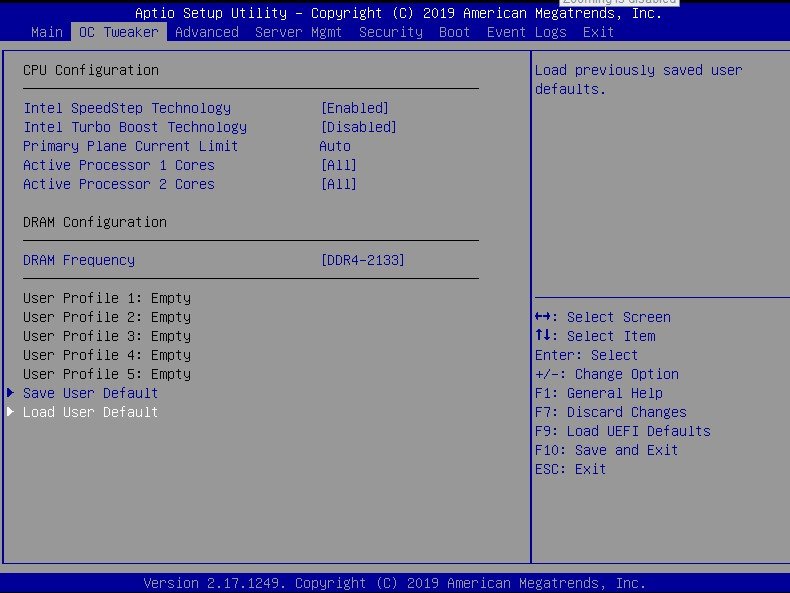
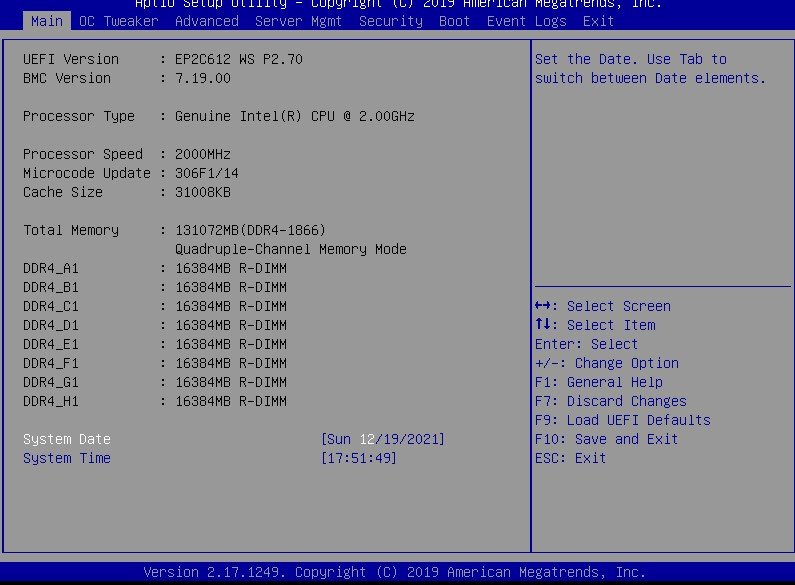
-
UPDATE: So the disabling the C states in the BIOS only worked for a few days. It's crashing almost daily now. Also added "rcu_nocbs=0-47" to the flash boot procedure. Still doesn't help. It's definitely related to the CPUs.
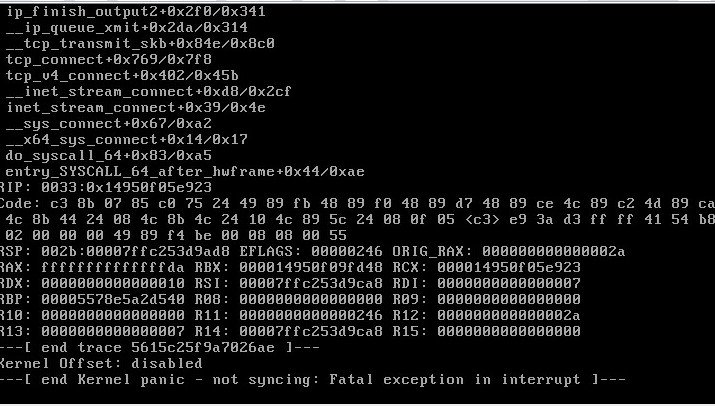
-
It seems so. Won't work without it.
-
Hello Guys I'm in the process of moving around 27Tb of data from my NAS to my new expanded array. I tried using Syncthing and Resilio however the issue was that both were creating a load of empty directories on the array. This meant that when one disk filled up nothing else would move. I then tried rsync, it was doing the same thing and so I resorted to using Midnight Commander for the transfer. I have a few days left to transfer with directories being created and filled one at a time. Now in the near future I want to replace the NAS with another Unraid based system as weekly backup. Is there another way of doing this as MC is manual only?
-
It may have been down to the C6 power state in the BIOS. Now disabled, it's been stable so far.
-
The resolver part is for the docker network. I did make a mistake though as $upstream_app should have had the container ID, fixed now. Amending the "Server name" and "Public_baseurl" resulted in a non functional server. I changed the bind address at 290 to the docker IP. No change in described behaviour. Homeserver.log & .db continue to fill up. Very strange.
-
Having some issues with the federation here guys and looking for some advice. Issue 1 I can browse public rooms in element however joining them takes a good five minutes at which point I usually get a "failed to join room notification", then it strangely joins the room. Leaving also take five mins but does eventually leave. Sending a message takes about the same time. There's obviously a federation issue here as the homeserver.log is full of federation errors. I ahve attached the various logs. Issue 2 The homeserver.log and homeserver.db fills up dramatically 30M an hour, any way of limiting this? homeserver.log homeserver.yaml matrix.subdomain.conf
-
Crashed again. Ultron
-
I've removed Parity Check Tuning plugin as of now. I've got a rather large collection of containers, it's mainly the databases and PVR ones that are large. It's always been around 70G and is fairly constant. Having had the issue you described last year it usually just stops the docker service from running. In this case the UI completely crashes, I can't even reset by SSH, I need to use IMPI to reset the machine. I'll start going through the containers just to check the oaths anyway. Here's the command output root@Ultron:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 63G 1.7G 62G 3% / tmpfs 32M 5.9M 27M 19% /run /dev/sda1 7.2G 948M 6.3G 13% /boot overlay 63G 1.7G 62G 3% /lib/modules overlay 63G 1.7G 62G 3% /lib/firmware devtmpfs 63G 0 63G 0% /dev tmpfs 63G 264K 63G 1% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 3.4M 125M 3% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes /dev/md1 5.5T 2.0T 3.5T 37% /mnt/disk1 /dev/md2 5.5T 40G 5.5T 1% /mnt/disk2 /dev/sdb1 224G 187G 38G 84% /mnt/cache-docker /dev/sdf1 11T 5.2T 5.8T 48% /mnt/cache-downloads /dev/sdi1 932G 264G 669G 29% /mnt/cache-files /dev/sdd1 932G 6.6G 925G 1% /mnt/cache-media /dev/sde1 932G 6.6G 925G 1% /mnt/cache-tv shfs 11T 2.1T 8.9T 19% /mnt/user0 shfs 11T 2.1T 8.9T 19% /mnt/user /dev/loop2 100G 69G 30G 70% /var/lib/docker /dev/loop3 1.0G 6.1M 903M 1% /etc/libvirt //200.200.1.244/GusSync 43T 37T 6.3T 86% /mnt/remotes/200.200.1.244_GusSync //200.200.1.244/Mel Drive 43T 37T 6.3T 86% /mnt/remotes/200.200.1.244_Mel Drive //200.200.1.244/Public 43T 37T 6.3T 86% /mnt/remotes/200.200.1.244_Public //200.200.1.243/Public 43T 37T 6.3T 86% /mnt/remotes/200.200.1.243_Public root@Ultron:~#
-
Yeah I'm aware but that's not the issue at hand mate.
-
It's my internal IP range.
-
It's been on the internal network for years, never got around to switching everything over.
-
Happened again today randomly at roughly <77>1 2021-09-21T18:49:01+01:00 Ultron ultron-diagnostics-20210921-1950.zip
-
Did you ever find a solution? I have the same issue. Some containers are correct, others aren't regardless off if there's a TZ variable or not.
-
I still have a working template of you want mate? Place this in your flash drive directory /boot/config/plugins/dockerMan/templates-user/ my-rutorrent.xml






