




Mr_Jay84
Members
-
Joined
-
Last visited
Everything posted by Mr_Jay84
-
That solved it! Thank you kindly!
-
I also have the issue of none of the HD's showing under Parity, Array, Cache, SSD, Unassigned Drives. The do show under the Disk Overview windows though.
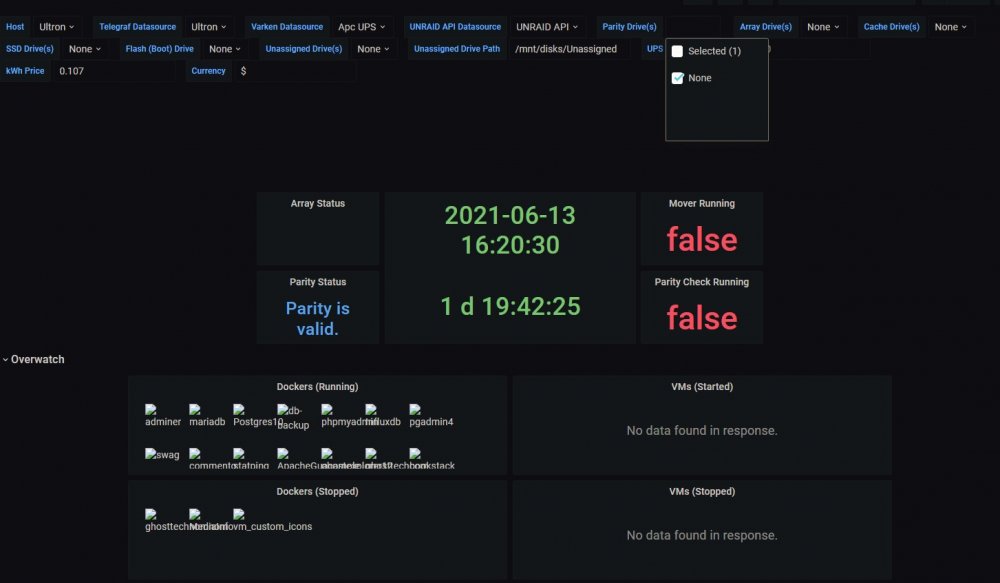
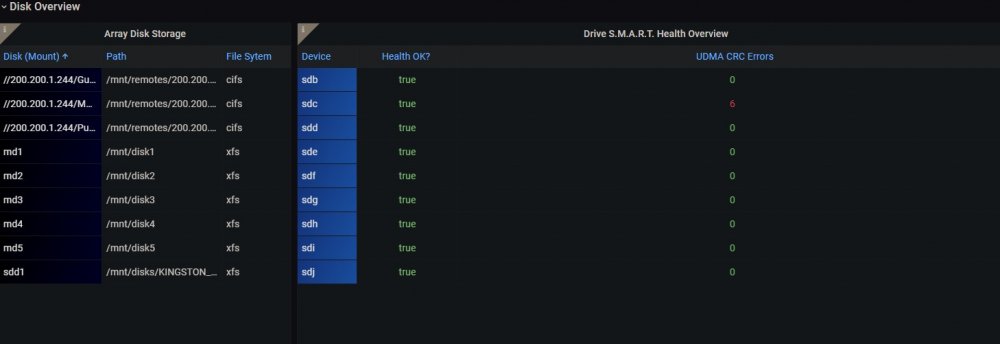
-
Same issue here.
-
Anyone know what this means? Error: ER_BAD_FIELD_ERROR: Unknown column 'description' in 'field list'
-
Anyone else having issues with PP failing after the most recent update. It was working perfectly fine before with Medusa and Sonarr. Now ill I get is PP-Failures.
-
Christ so it is! That will team me to install dockers when drinking! lol Thanks awfully!
-
No joy whatsoever unfortunately.
-
I'm trying to get this running but still can't reach the WebUI. Installing [email protected]... Installing [email protected]... MeshCentral HTTP redirection server running on port 80. Generating certificates, may take a few minutes... Generating root certificate... Generating HTTPS certificate... Generating MeshAgent certificate... Generating Intel AMT MPS certificate... MeshCentral v0.8.16, LAN mode. Server has no users, next new account will be site administrator. MeshCentral HTTPS server running on port 443. Docker Template in attached screenshots
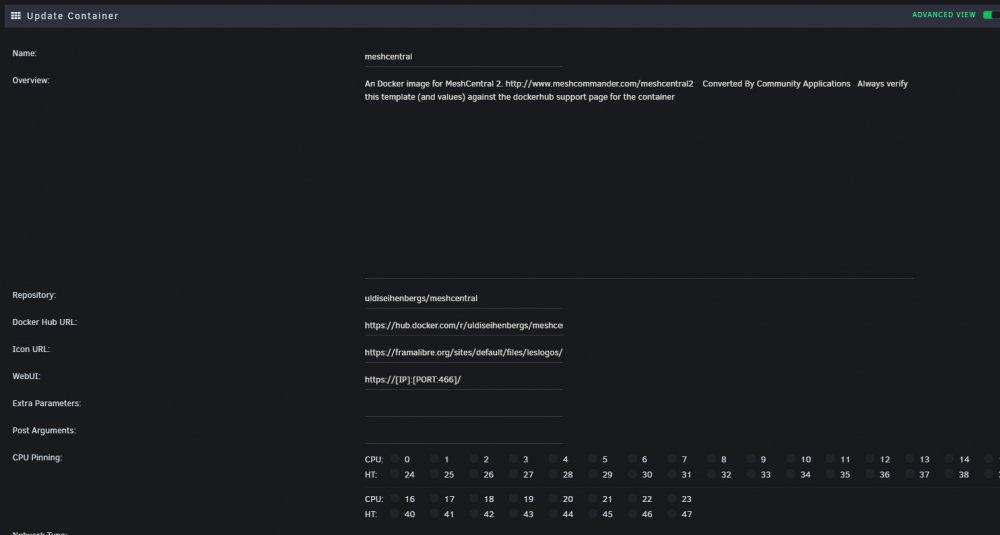
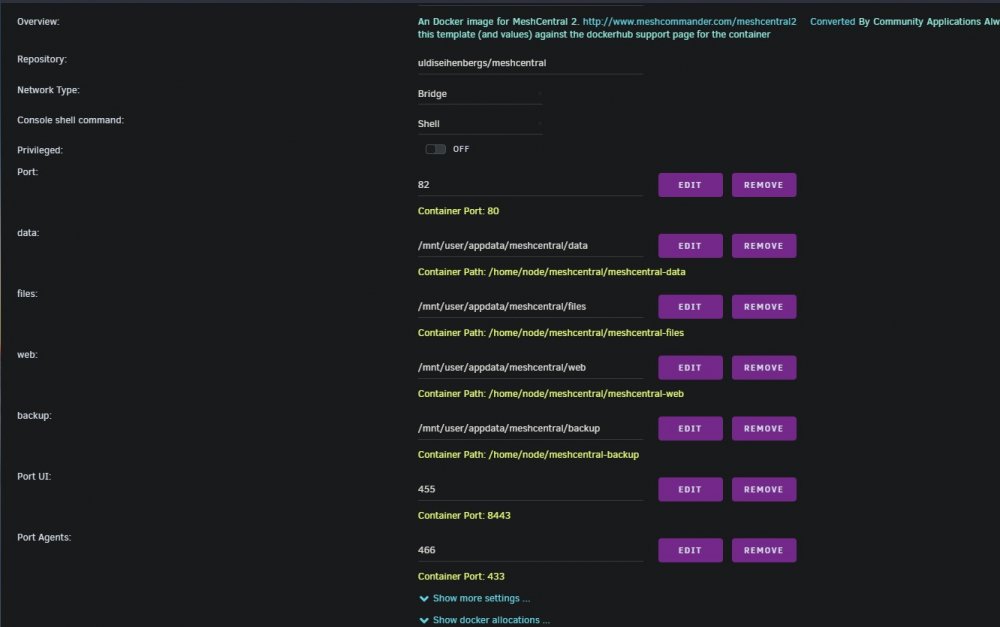
-
Ich777 right I think the best route for me is to leave the solitary transcoding card with the drivers in persistence mode that way it will throttle back to P8 when not in use by Emby. Then leave the spare cards in VFIO with the VMs, at least this way I know they power throttle properly.
-
Ah right I see, so if persistence mode is on the card will be unavailable to use with a VM? If persistence mode is off will the cards throttle back to P8 power state once the docker/VM is finished with it? When the cards are in VFIO mode I'm not sure which power state their in, I don't think there's anyway to check via the CLI. The only way I can think of is to measure it is the power draw from the PSU. I have a Corsair PSU that I can read the power draw. They don't appear to be using anymore power even if the VMs are turned off. The system itself is in the attic so I'd need to go up and listen to the fan states to double check.
-
Will that work if the cards are using VFIO though? If i haven't got them enabled with VFIO the drivers will set the cards to the correct power state however this means I can't use them with the VMs as i get this error... Mar 15 23:37:01 Ultron kernel: NVRM: Attempting to remove minor device 1 with non-zero usage count! This locks the entire VM section up requiring a reboot.
-
Looking for some input here guys regarding GPU use. I'm on 6.9.1 and using the Nvidia plugin which enables the dockers to use all my three GPUs, one one is used for Emby. Now the issue is when I assign one to a VM I get his error... Mar 15 23:37:01 Ultron kernel: NVRM: Attempting to remove minor device 1 with non-zero usage count! So from what I can gather the Nvidia plugin captures the GPU's and wont allow them to be used by VMs. Using the VFIO option reserves the spare two GPUs enabling their use by VMs, okay great but this means the VMs must be running other wise the cards are in full P0 mode (full power). Is there a away to boot without VFIO using the Nvidia plugin, use the spare cards with the VMs and then return them to the Nvidia plugin pool when the VM shuts down for power management and other uses? Or is there a way to keep the spare cards on VFIO and run a script to put them in P8 mode?
-
Can I request this https://owncast.online/ This would be an amazing docker for unraid!
-
I understand, I was just wondering in case I missed something.
-
Both conainters and dockers. I know it won't dipslay anything for a GPU thats in use by a container buts its usefull to check on the GPU when not in use for viewing the power state of the card.
-
Is it possible to have multiple statistics as I have a few GPUs?
-
I have the same issue. I have set it up exactly as per SpaceInvaders video. If I set it to use the custom network with Docker DNS resolution it works via the subdomain. Setting the guacamole docker with its own IP times out via the reverse proxy but is available internally via the static IP. EDIT: SOLVED Go into settings - Docker - click on advanced view in top right hand corner - enable Host access to custom networks. You'll have to turn off the docker service to change this. Works perfectly as per Spaceinvaders video now.
-
I don't even see it under Squids repository.
-
Can't find this on the Apps section running 6.8.3 Has it been removed?
-
Is the built in community document sever working yet?
-
Is there a way off pulling recipes from an online source to add to the database?
-
I'm having issues with MariaDB, I've got a few dockers that require it's use which keep failing every few hours requiring MariaDB to be restarted. Has anyone else experienced this? Can I back the databases and reinstall Maria?
-
Yeah that's right. I had to store the eBooks on the NAS for various reasons. I suppose then answer is to host the library on the array and have a script duplicate all books to the NAS. Running Calibre as a Docker on the QNPA NAS is also another option. Thanks for the sharp repsonse!
-
I seem to be having problems if my library is mounted on my NAS. Hosting the library on the array doesn't suffer from this. Anyone else noticed this behaviour?
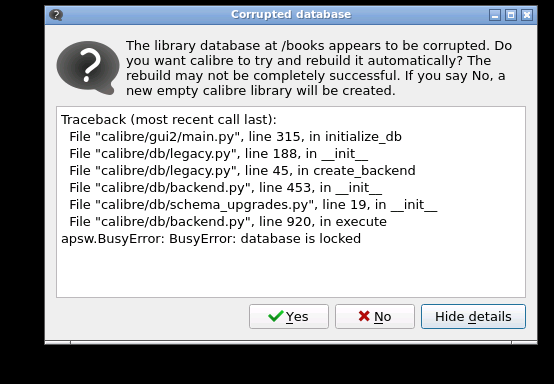
-
Can I use this to collect SNMP data from and APC AP9360 UPS card/QNAP NAS and send to telegraf?






