



CS01-HS
Members
-
Joined
-
Last visited
Everything posted by CS01-HS
-
I noticed a couple of strange entries when I ran testparm -v The include for smb-unassigned.conf was added to my isos share (it's nowhere else in the output): [isos] case sensitive = Yes comment = iso images include = /etc/samba/smb-unassigned.conf ... And similarly smb-shares.conf was added to my system share (which, in case it's relevant, is a cache-only share I export through /boot/config/smb-custom.conf to bypass shfs): [system] comment = system data include = /etc/samba/smb-shares.conf path = /mnt/active/system ... Restarting smb and the server didn't change it so something's adding them. Is that where they belong? I run the UD and Recycle Bin plugins which I know make some modifications. And for reference here's my SMB Extras: [global] # Fix for 6.9.0-rc2 Mac client search spotlight backend = tracker # force inclusion of acl_xattr # (doesn't work because it doesn't propagate to shares) ##vfs objects = acl_xattr catia fruit streams_xattr # tweaks from https://wiki.samba.org/index.php/Configure_Samba_to_Work_Better_with_Mac_OS_X min protocol = SMB2 #Custom include = /boot/config/smb-custom.conf
-
Interesting - the containers that didn't autostart use my vpn container's custom network. I have the order right (vpn before the others) and wait 60 set on the vpn container but I never considered whether ca.backup observed wait time since it always "just worked" – maybe it used to and now it doesn't. If the plan's to go to container-specific tar files, that delay's probably sufficient to make observance irrelevant.
-
I had a similar issue with my Debian VM and yt-dlp with 6.11.1. Ended up reverting to 9p.
-
Kind of, from SimonF's post above - sdspin. I haven't used it in a while though and this post suggests some issues spinning down:
-
That's probably a different problem - my containers were fine aside from having to start them manually.
-
Strange problem with my first appdata backup on 6.11.2 - some containers (which were running and set to autostart) weren't restarted post-backup. Maybe coincidence but all the affected containers use a custom network (none of the non-custom network containers failed to start.) Maybe a fluke or maybe an issue with my setup, although I haven't changed anything and this plugin's been rock solid. Anyone else see this?
-
I have a Media share setup as follows: Media/ Movies/ TV/ I have Recycle Bin enabled for that share: Media/ .Recycle.Bin/ I have a container that deals specifically with Movies. I'd like to restrict its access to the movie dir by setting the container path: /mnt/user/Media/Movies -> /movies But I'd also like to give it access to the Recycle Bin which lives one directory up. I thought I could "trick" it by overlaying the recycling dir on the existing path with an additional path var: /mnt/user/Media/.Recycle.Bin -> /movies/.Recycle.Bin but that didn't work. (It results in the creation of the host path below) /mnt/user/Media/Movies/.Recycle.Bin Currently I pass it the Media share which allows it to access both Movies and .Recycling.Bin - it works but it's not ideal. Is there a proper way to accomplish what I want?
-
In Live TV -> Advanced I see Default recording path Does setting that change where emby stores tmp live TV files? Well that's easy enough to fix even with an unraid user script. Something like this that runs every hour, deleting ts files more than an hour old: find /host/path/to/transcode/dir/ -type f -name '*.ts' -mindepth 1 -mmin +60 -delete You could even restrict it to files above a certain size with -size +100M
-
No sorry, I don't use live TV so I've never tested it. I'm guessing they do that for DVR functionality (serves as a reference file which in the standard case is the media itself.) In the best case my script won't have any effect, in the worst case it'll delete it which could break things. If active live TV files can be differentiated by name the script could be tweaked to ignore them, or if not we can infer by size (greater than X.) What are you trying to solve exactly, because my guess is creation of these large files with live TV is unavoidable.
-
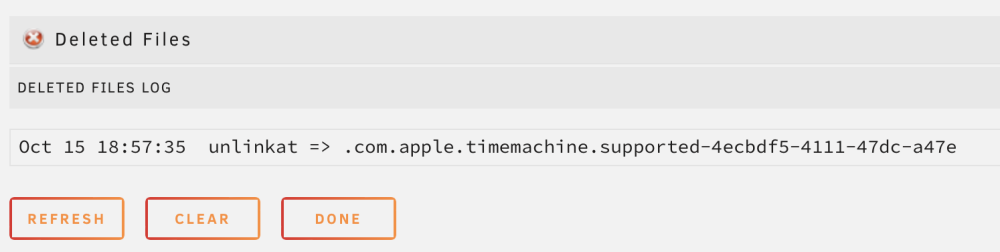
Is it normal to see frequent entries like this in the Recycle Bin's deleted file log? I did have a time machine share at one point but deleted it a while ago. None of my existing shares are exported as "Yes/Time Machine" root@NAS:~# testparm -sv | grep -i 'time machine' Load smb config files from /etc/samba/smb.conf lpcfg_do_global_parameter: WARNING: The "null passwords" option is deprecated lpcfg_do_global_parameter: WARNING: The "syslog only" option is deprecated lpcfg_do_global_parameter: WARNING: The "syslog" option is deprecated Loaded services file OK. Weak crypto is allowed by GnuTLS (e.g. NTLM as a compatibility fallback) Server role: ROLE_STANDALONE root@NAS:~# I do have Enhanced macOS interoperability enabled if that matters.
-
That definitely works as long as they don't decide to change the directory structure again. The find should be structure-agnostic (unless I screwed up.)
-
Initial post updated with fix and various improvements.
-
You're right, mine too. They must have changed it. (My punishment for saying "just works") I've replaced the simple ls: ls ${TRANSCODE_DIR}/*.ts -1t | tail -${BATCH_SIZE} | xargs rm with a find: find ${TRANSCODE_DIR} -type f -name "*.ts" -exec ls -1t "{}" + | tail -${BATCH_SIZE} | xargs rm to work around it. I'll update my initial post unless you have something cleaner?
-
Still using them. I haven't found a better solution but I haven't looked, this "just works." It's possible Emby fixed their garbage collection problem so it's no longer necessary. I've tweaked the scripts slightly for better error-handling (initial post edited with updated scripts)
-
I finally got around to testing this with an iPhone syncing to an unRAID Mac VM - works beautifully. The big warning banner about missing usbip_host and vhci_hcd modules was a little confusing because neither seems necessary but otherwise straightforward. Great job, thank you.
-
Assuming the speed bottleneck is array write you could use the CA Auto Turbo Write Mode plugin to enable Turbo mode on a schedule coincident with your backup.
-
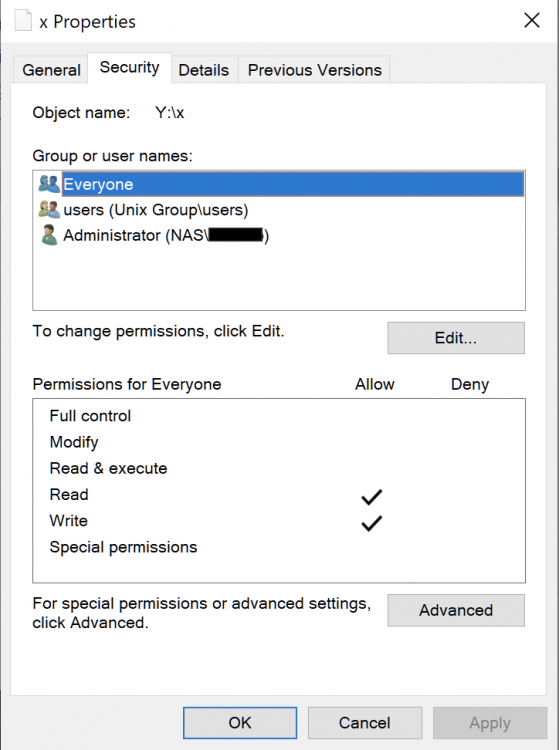
Looks like this problem is Mac-specific. To test I setup a Windows VM – permission seem fine (files read/write, no execute)
-
Here's a test comparing unRAID's SMB behavior to my Raspberry Pi's. /Volumes/Download/ is the smb-mounted unRAID share /Volumes/Website/ is the smb-mounted Pi share In both cases default is the logged-in smb user. unRAID [macbook]:~ $ touch x [macbook]:~ $ ls -l x -rw-r--r-- 1 default staff 0 Jul 10 12:01 x [macbook]:~ $ cp x /Volumes/Download/ [macbook]:~ $ ls -l /Volumes/Download/x -rwx------ 1 default staff 0 Jul 10 12:01 /Volumes/Download/x [macbook]:~ $ cp /Volumes/Download/x . [macbook]:~ $ ls -l x -rwx------ 1 default staff 0 Jul 10 12:01 x Raspberry Pi (samba package) [macbook]:~ $ touch y [macbook]:~ $ ls -l y -rw-r--r-- 1 default staff 0 Jul 10 12:20 y [macbook]:~ $ cp y /Volumes/Website/ [macbook]:~ $ ls -l /Volumes/Website/y -rw-r--r-- 1 default staff 0 Jul 10 12:20 /Volumes/Website/y [macbook]:~ $ cp /Volumes/Website/y . [macbook]:~ $ ls -l y -rw-r--r-- 1 default staff 0 Jul 10 12:21 y [macbook]:~ $ chmod a+x y [macbook]:~ $ ls -l y -rwxr-xr-x 1 default staff 0 Jul 10 12:21 y [macbook]:~ $ cp y /Volumes/Website/ [macbook]:~ $ ls -l /Volumes/Website/y -rwxr-xr-x 1 default staff 0 Jul 10 12:21 /Volumes/Website/y Anyone?
-
Problem persists even after disabling my custom configuration. I found a number of users reporting similar samba problems, some with windows https://ubuntuforums.org/showthread.php?t=2414960 I'm out of my depth at this point but curious if it's working for anyone, windows, mac or otherwise.
-
Is it normal that all files copied to or from an unraid share have permission -rwx------ ? Create file locally and copy to mounted unraid share Public: [macbook-pro]:~/Desktop $ touch x [macbook-pro]:~/Desktop $ ls -l x -rw-r--r-- 1 fred staff 0 Jul 1 09:13 x [macbook-pro]:~/Desktop $ cp x /Volumes/Public/ [macbook-pro]:~/Desktop $ ls -l /Volumes/Public/x -rwx------ 1 fred staff 0 Jul 1 09:14 /Volumes/Public/x Examine file's permissions on unraid server NAS: [macbook-pro]:~/Desktop $ ssh root@NAS Last login: Fri Jul 1 08:56:17 2022 from 10.0.1.3 Linux 5.15.46-Unraid. [root@NAS]:~# ls -l /mnt/user/Public/x -rw-rw-rw- 1 fred users 0 Jul 1 09:14 /mnt/user/Public/x I've tweaked my samba config to resolve some mac-specific issues so I don't know whether this behavior's default or a consequence of my settings.
-
I filed this report for a pre-release of 6.9.2 (I believe), thread below, but it's still broken in 6.10 stable.
-
+1 Performance was much better with AFP before it was dropped (I think in 6.9) Finder sometimes takes 10-20 seconds to list a directory with a dozen files on a cache-only share. I assumed it was generally poor SMB performance in MacOS but maybe not. I've tried all the recommended tweaks, client and server, but it's still pretty poor. Relatedly, has search from MacOS clients (which hasn't worked since last November) been fixed in the recent betas? I'd think that'd be a pretty major issue but I don't see many complaints.
-
The interface recommends a monthly balance but my schedules are based on day-of-week. Adding "First Monday", "First Tuesday", etc. as an option would be handy.
-
With 6.9 I had to tweak unRAID's sdspin to make USB spindown work. I don't know whether this solution's generic and I haven't tested with 6.10 sdspin is a critical script so if you tweak it make a backup and be careful. Hope it helps. Edit: this one also may be relevant. Good luck.
-
Now I wonder if Speed "Unavailable" for recent (and historical) runs is due to the plugin. Very minor issue either way.






