





Thx And Bye
Members
-
Joined
-
Last visited
Everything posted by Thx And Bye
-
I am not sure if this has come up before, but I could not find anything on it. BackgroundWhen ZFS or BTRFS is used in the array, the filesystem can detect invalid data blocks. ProblemIn cases where a block is identified as invalid, writing corrections to parity does not provide a benefit. At the same time, wiping and rebuilding an entire drive is often impractical and time-consuming. Proposed SolutionIntroduce an option to select a specific drive and run a parity check that corrects that drive, similar to the existing “write corrections to parity” functionality. EnhancementTo make the process more effective, the system could: Run a scrub when errors are detected. Based on the scrub results, automatically recommend whether corrections should be written to data or to parity.
-
It does indeed list one value there for the drive (Reallocated_Sector_Ct is 1) but as unRAID shows "No Attributes Available" for the flash there is no way to acknowledge the error. This SSD is quite old already and also connected via USB. So I'm not sure if it's because of the age, the connection or UnRAID not knowing how to deal with this situation (the flash having attributes in the first place). Starting S.M.A.R.T tests for the flash also doesn't seem to work. Smartctl is seemingly able to read the values, albeit not absolutely correctly since 109 years of power on time doesn't seem plausible to me.
-
With all drives working now, the plugin is showing the status on the dashboard as expected. One odd thing (but nothing critical): My flash is showing a S.M.A.R.T warning while the drive itself reports S.M.A.R.T as passed based on an Attribute check. I understand that a SATA SSD attached to a USB<->SATA adapter isn't the usual setup for the flash. Just an odd thing I've noticed. IB-245-C31-20250515-2100.txt
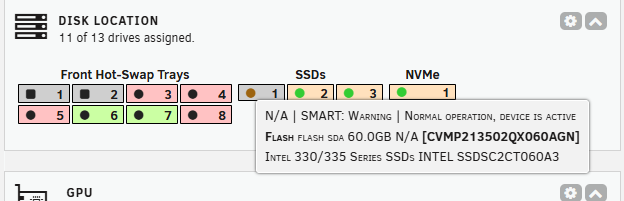
-
So I think I now know what the issue is. After the update to UnRAID 7.1.x the drive didn't show up anymore at all. So its likely that the drive has failed. I don't know why the SSD didn't show up the the UI of unRAID as failed though. After the update and subsequent reboot the device doesn't show up in the list and unRAID UI anymore. This also means that the plugin is not showing the error anymore and lists the configured slot as unpopulated. I have a replacement drive ordered and will report back if it shows up correctly in the plugin now too.
-
I've just now fond the time to run the steps with debugging. I've reset devices first and then ran SMART+DB again with debugging enabled. I've send you the .log file via PM.
-
nvme1n1 is missing. That would be the MKNSSDTS1TB-D8_MK23021714C44E8B3.json (file attached) Sorry that I didn't check earlier there is this error in the log (but nothing on the 16th when I initially tried to setup the plugin): [29-Apr-2025 00:00:01 Europe/Berlin] PHP Fatal error: Uncaught TypeError: end(): Argument #1 ($array) must be of type array, false given in /usr/local/emhttp/plugins/disklocation/pages/page_system.php:414 Stack trace: #0 /usr/local/emhttp/plugins/disklocation/pages/page_system.php(414): end(false) #1 {main} thrown in /usr/local/emhttp/plugins/disklocation/pages/page_system.php on line 414 MKNSSDTS1TB-D8_MK23021714C44E8B3.json
-
[2025-04-16 23:07:23] SMART: /dev/sg1 UNKNOWN (1b7852b855) done in 42ms. [2025-04-16 23:07:24] SMART: /dev/sg0 UNKNOWN (3f4304780f) done in 226ms. [2025-04-16 23:07:24] SMART: /dev/sg2 IDLE (ee963138ac) done in 576ms. [2025-04-16 23:07:24] SMART: /dev/sg3 ACTIVE (deb7fcf9fa) done in 331ms. [2025-04-16 23:07:25] SMART: /dev/sg4 ACTIVE (fb5b981762) done in 125ms. [2025-04-16 23:07:25] SMART: /dev/sg5 ACTIVE (626427ef2d) done in 339ms. [2025-04-16 23:07:25] SMART: /dev/sg6 ACTIVE (e51311a5b7) done in 109ms. [2025-04-16 23:07:25] SMART: /dev/sg7 IDLE (8b0e9492c0) done in 203ms. [2025-04-16 23:07:25] SMART: /dev/sg8 ACTIVE (53d30157b3) done in 97ms. [2025-04-16 23:07:26] SMART: /dev/sg9 ACTIVE (9c84f2f252) done in 183ms. [2025-04-16 23:07:26] SMART: /dev/nvme0n1 ACTIVE (4a9eeecc90) done in 75ms. [2025-04-16 23:07:26] SMART: /dev/nvme1n1 ACTIVE (1b7852b855) done in 43ms. Writing to the database... done in 2.7 seconds. In this list both NVMe drives seem to be listed. INTEL_SSDSC2CT060A3_CVMP213502QX060AGN.json ST16000NM001G-2KK103_ZL2P97RS.json TOSHIBA_MG08ACA16TE_13U0A059FVGG.json KIOXIA-EXCERIA_G2_SSD_X2EB70WHKME5.json ST4000VN008-2DR166_ZDHALT30.json WDC__WDS200T1R0A-68A4W0_23292T800029.json MKNSSDTS1TB-D8_MK23021714C44E8B3.json ST4000VN008-2DR166_ZM40Y4EY.json WDC__WUH721816ALE6L4_5EG2NW7P.json SPCC_Solid_State_Disk_AA230217S302KG00435.json TOSHIBA_MG08ACA16TE_13U0A058FVGG.json For both NVMe drives the json file do contain valid data. Should I proceed and remove the files or reset the devices? The RAM I have is ECC, so if it's corrupted I don't think it's related to the device itself. Just in case it might be important: The NVMe drives are on a bifucation card in a single x8 PCIe slot.
-
I've just installed this plugin and it looks promising (apart from the default colors being nearly unreadable with the "Azure" theme, but that was quickly fixed by changing the colors to lighter ones) The main issue I'm facing right now is that, after following the instructions on the dashboard and subsequently setting up the layout and assigning the disks, the dashboard just shows a Go to System and initialize a "Force SMART+DB" warning. Executing this options has no effect on the warning though. Let me know if there is anything I can provide or if this is an easy fix. The plugin also doesn't detect one of my NVMe drives. 11 drives total is correct, but under allocations there is only 10 options to select. /dev/nvme0n1p1 is detected as nvme0n1 but /dev/nvme1n1p1 isn't. regards


-
I've formatted two drives of my array with ZFS by now. The web-ui is correctly showing the total size of the array. When mounting the share via SMB on Windows it doesn't include the zfs drives in the size. The 2TB of a btrfs formatted cache is added correctly to the size of the share. It's not a major issue but it could cause Windows to not accept a transfer due to insufficient space.
-
The output from docker ps -a.txtlooks rather normal to me. Here is the docker inspect 2eda680bcc88.txt but I can't see anything special about it either? Here is the log of the containers starting:container startup logs.txt
-
Yes I have CA Auto Update Applications installed. The error occurs on manual backups too though and the backup and auto update run at different times anyways. It's always the same container that has this problem (it starts just fine when doing so manually via the webUI). The container is part of a stack deployed via docker-compose (Compose Manager Plugin) and not touched by the auto update. I've also replaced my gzip with pigz for (much) faster compression, but it's likely unrelated as the creation and validation of the archives works just fine.
-
I'm always getting a failed backup but none of the archives failes to validate. One container failes to start because the image can't be deleted (?) though. But a container not starting correctly shouldn't fail the backup, right? backup.log
-
Would it be feasible to get a checkbox to run nvidia-persistenced after the driver install on system startup to keep the driver loaded? More information: https://docs.nvidia.com/deploy/driver-persistence/index.html
-
Yes, two of them have. plexinc/pms-docker has it build in and I've created my own that checks that my VPN container is properly connected.
-
For now I'm running a user script on a daily schedule as a workaround: #!/bin/bash /usr/local/bin/unraid-api/unraid-api restart
-
I'm on version 2021.10.12.1921 currently, so it should be the most recent one. But this issue is present at least for a few versions now.
-
Hey, so I've noticed on multiple occasions that the MyServers plugin will lose connection and then cause a high CPU usage. It also spawns a lot of "sh" subprocesses without ever successfully establishing a connection again. executing 'unraid-api restart' solves this for at least a day or two. No more spawned 'sh' childs anymore too. Should I just restart via a user script every 24 hours as a workaround or is this a more general issue that can be fixed in the plugin code? All else kept the same, after a restart of unraid-api my load average drops from around 1.60 1.75 1.89 to 0.38 0.76 1.36 after about 10 minutes or so. This is significant CPU load and thus power usage that is completely wasted. If there are any logs I can provide I'll happily do so. The system log doesn't show any anomalies tho.
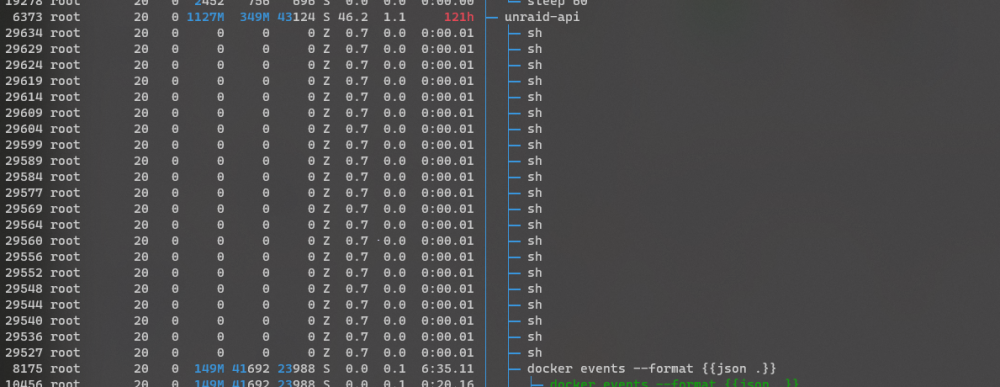
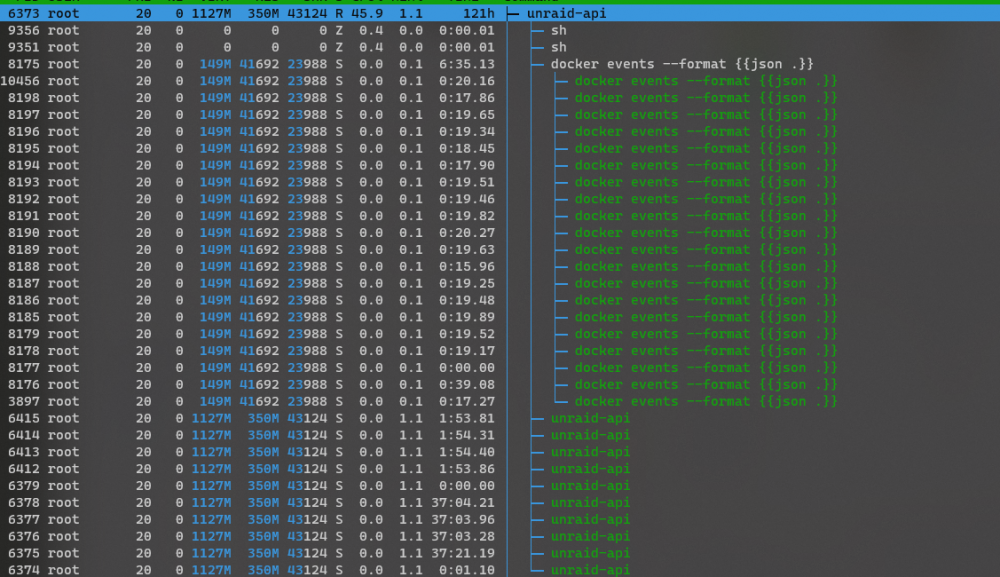
-
No but you can support this plugin in its endeavor: [Plugin] Docker Compose Manager - Plugin Support - Unraid
-
I wish there would've been a section about ECC memory but overall, it's a really informative episode. Good job!
-
After removing the old files and creating a new export it shows "related export file is not present": But the files are present on the flash:


-
This isn't specifically a UnRAID problem but I'm putting it here for visibility and awareness, as UnRAID v6.9.2 is affected by this bug. I already commented about the problem over here: UNRAID 6.9.2 - DOCKER CONTAINER NOT REACHABLE OVER THE INTERNET WITH IPV6 There is a problem in the networking engine of Docker when using IPv6 with a container that has only a IPv4 assigned in a bridged network. Prior to Docker version 20.10.2 IPv6 traffic was forwarded to the container regardless. This behavior changed with version 20.10.2. This is the pull request that changed this behavior: Fix IPv6 Port Forwarding for the Bridge Driver A fix for this regression was issued 4 days later: Fix regression in docker-proxy but this wasn't implemented into Docker until version 20.10.6. For me this is just a minor issue as I have a full dual-stack connection and switched to only IPv4 for now, but for people using a connection via DS-Lite, this could mean that their docker-containers that are operating in bridged mode aren't accessible from outside of their home network anymore (like PLEX or Nextcloud).
-
Nice tips, I just wish it would be easier to setup KeysFile authentication and disable password authentication for the SSH. Just placing your pupkey in the UI and setting a checkbox to disable password auth would be nice. I currently have it setup like ken-ji describes here. Then i edited PasswordAuthentication to "no". Also think about a secure by default approach with future updates. Why not force the user to set a secure password on first load? Why even make shares public by default? Why allow "guest" to access SMB shares by default? Why create a share for the flash in the first place? I get that some of those things make it more convenient, but imo convenience should not compromise security.
-
If you want to call from shell scrips, use the complete command, not the alias. Like this: docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -v "$path:$path" -w="$path" docker/compose $path has to be the directory where your compose file resides.
-
As CA Backupv2 doesn't use the --dereference (-h) operator for tar it would only backup the symbolic link itself, not the files it points to. Even with the -h option I'd advise against it tho. Just put all your config folders from your docker containers to the same folder for a clean backup and easy restore.
-
Okay. Fair decision, your call after all. Yet it still causes a significant downtime for me when the backup runs if compression only runs on one thread. I found a way to use pigz without needing to modify the plugin tho. I installed pigz via nerd tools and replaced the gzip binary with a symlink to pigz, so it's used by tar --auto-compress with the .tar.gz ending like CA Backupv2 invokes it. It yields substantial performance improvements with my 8C/16T CPU. Currently that's a reduction down to 6min from 37min (with verification of the backup file). If anyone stumbles upon this and thinks they can profit from parallel compression, it's fairly simple to do, just don't expect @Squid to fix any problems that should come up with this configuration and keep it in mind if you should ever run into a problem with CA Backupv2 to revert this before filing any bug report. Just move the original gzip binary (I renamed it to ogzip so if you should ever need it, it's still there) and then create the link: mv /bin/gzip /bin/ogzip ln -s /usr/bin/pigz /bin/gzip 'Official' support via a checkbox if pigz is detected would probably be better but this works for me and can be applied via the /boot/config/go script just fine.










