




bnevets27
Members
-
Joined
-
Last visited
Everything posted by bnevets27
-
I've been using this since it was posted and want to thank @PeteL for creating this. There is a radio show I've been trying to record and archive for years and while I had a few hacky ways that weren't too reliable in the past, this has just worked for years. Thank you!
-
That looks all too familiar. Apparently, I bought my first key in 2010 (email from Tom!) but I know I was using unraid before then, must have been v4 basic. Don't miss the install scripts to try and shoehorn more functionality into it, way before packages and the app store. It's come a long way. It was also not as well known at all. Very little talk outside specific locations, not anything like today. I remember Tom making a comment (and I hope this is right), speaking something along the lines that is is a niche product and won't ever become really popular as most users don't have the need for this much storage, this was when Lime-tech was a one man show. Amazing to see the exact opposite happen.
-
Ah ok yeah that makes sense. 999 it is then, thanks!
-
Dumb question? So I ran the command to start 3 plotting tasks, one in each window of tmux. Great, all worked, got 3 plots. I expected it to start a new plot after finishing, it apparently does not. So I would have to run the command again. Obviously it doesn't make sense to manually start a plotting task, so how does one make sure a new plot starts after the last one finishes?
-
I agree and disagree. I personally currently have more ram then I know what to do with so I could care less how much ram unraid uses. BUT, I'm also looking at changing that in the future and I do also help with builds for others with different requirements and I am looking to do a straight stripped down, lowest specs just NAS type build. So I do see the need to be conservative also. At the same time minimum specs builds are getting to have more memory then they used to, but that is still evolving. I've even noticed now on an old machine older version of unraid that were lighter run better then the more recent builds. Maybe outside of the scope of this thread but ever since unraid has become more feature rich there has been this "battle" between raw minimalistic NAS and full feature rich NAS. I think it we might be getting to the point where 2 versions would be better. A "light" and a full. That would be the simplest, that would probably cover most of the two different groups. You could also go down the customize your install route and get to choose what you want included before your image is built. That would be great for more advanced or particular users. Of course this requires more work and development. That doesn't come for free. Not sure how well known this is so it's good to be brought up. It is definitely helpful. I've been using mc forever for managing my files server side/locally. Also a tip, if you're doing large transfer use screen so the transfer will continue if for some reason you loose connection to the server or your machine you are running mc from goes to sleep. But I will also say it's a bit of a pain/slow. It would be much quicker (and easier for a large group of people) to just click on an icon in the web ui, copy and paste (or drag and drop) and be done. With mc you still have to open a terminal and type mc and navigate to the file/folder you want to move on pane and then do the same in the other pane, then hit the correct F key. It's really not the most arduous task but of course it could be much better/nicer/easier. Would all's be nice to have a bit more protection. Accidental deletion is definitely possible on a large scale. Though this is true for most why people manage their files.
-
That was it. Thank you!
-
I'm trying to use this script to mount multiple shared drives. From everything I've read here I should just be able to run multiple version of this script. But when I do I get the following error: Failed to start remote control: start server failed: listen tcp 127.0.0.1:5572: bind: address already in use I have rebooted. I'm only mounting the mergerfs in one of the versions of the script. Whichever script I run first will work but I can't get a second to work due to the above error. Any clues?
-
True but the successful backup that it completed is unfortunately not a backup of a full working system. And in this case basically blank. I was lucky I did a manual for copy at the start so it wasn't a complete loss. I usually also keep (by renaming the folder) a permanent backup that CA backup/restore creates once in a while copy in case I don't catch something that's gone awry within the deletion period, so I can go further back if necessary. But yes with a delete backups every 60 days and say a minimum of 2 backups kept it would definitely keep a good backup long enough. In that same right, keep every nth backup indefinitely would be nice too but I can understand not wanting to put in too many options. Thanks squid for the great app!
-
Short version: If the server has been off for longer then the number of days set in: "Delete backups if they are this many days old" and CA Appdata Backup / Restore runs a backup on a schedule, it will delete all the backups. Solution: Probably a good idea to have a setting for minimum number of backups. How I came about this issue. My cache got corrupt and my dockers stopped working. Since I didn't have time to fix it and didn't really need my server running when the containers weren't working I shut it off till I had time to work in it. While working on it I've left it on overnight. Came back to it today and my backups have been deleted. My setting are set to delete after 60 days and well my server was off for over 60 days.
-
Haven't used this, have no idea if it will work but this looks like what you are looking for. https://github.com/doctorpangloss/nut https://hub.docker.com/r/doctorpangloss/nut Found via: Let me know if you get it working and what settings were used in the template.
-
Same, thank you jcouch93
-
Not sure why this is "of course they aren't" I think the majority of users here leave their unraid server on 24/7. I have a setup at one location that uses raspberry PI's for all of the clients (running kodi) and unraid running as the server. Since the server is in charge of recording live TV it's on all the time. And the minor power draw the PI's use I don't bother to sleep/turn them off. In a different setup/location I was using a more power hungry client(s) and would sleep them. So the syncing was an issue for me at that time. Glad you might have found a happy solution with emby though.
-
Might be a moot point if you leave your clients on all the time. I've found the only real way to decide between different solutions/software is to try them. Everyone has different preferences and setups. And different combinations work better for different people. If emby is easy to setup. Try it out. If nothing about it bothers you then stick with it.
-
Update command curl --silent -H "Content-Type: application/json" -u user:pass -d '{"jsonrpc":"2.0","method":"VideoLibrary.Scan","id":"scan"}' http://192.111.1.111:8080/jsonrpc &> /dev/null Clean command curl --silent -H "Content-Type: application/json" -u user:pass -d '{"jsonrpc":"2.0","method":"VideoLibrary.Clean","id":"scan"}' http://192.111.1.111:8080/jsonrpc &> /dev/null Those commands were last working on krypton, haven't used kodi since (not by choice). Alternatively you can add "clean after update" to the advanced settings xml. I ran mine separately for some reason. As saarg said, the webui is broke. So put it out of your mind it exists and better still, disable it. I only ever used the default scrappers but I did setup some of the files from a client. But after learning what was needed I mostly edited the xmls. I don't see scrapers Ah I looked into it, scrappers are in the guisettings.xml <scrapers> <moviesdefault default="true">metadata.themoviedb.org</moviesdefault> <musicvideosdefault default="true">metadata.local</musicvideosdefault> <tvshowsdefault default="true">metadata.tvdb.com</tvshowsdefault> </scrapers> I do remember getting it to all work was a massive PITA. But once working ran flawlessly. Getting familiar with kodi's xml files is helpful. You can do it all through xml and looking at the kodi logs. Which may or may not be more difficult, depends on the person. And from my long ago memory, you don't actually need the clients to have sources.xml if none of them are going to do any scanning. I know when I tried emby backend, many years ago, it required a sync operation with every client. Essentially each client has its own db, like how kodi runs out of the box. Emby just syncs all the clients with the backend. In my case, because I left all my clients off, the initial sync time took too long. It wasn't long in general but I wanted the library/recently added to be there instantly like it is when using mysql. That was my biggest gripe with it. And I think it has some other limitations but again, long ago and not sure how accurate that is anymore. And your use case could be different.
-
I personally had an issue way back when doing then an initial scan from a client not sure what it was but after that I never had a client do anything scanning. I think it might have been the paths being different. I personally for that reason about and to know the headless is working, do all my scanning with the headless only. Anyhow, you need to kick off a scan. You can set it to do it on start up. And then check the log and see if it's scanning. If is says scan finished in 0 seconds, you have a problem. The headless kodi won't scan on its own. So you need to either trigger it with something like sonarr. Or you can use a cron job and trigger a command (don't have it off the top of my head)
-
Yes you need MariadB docker also. You need to have a sources.xml in the user folder. You can set that up on a client box so you can use the gui and then copy it over or create it by looking at the kodi wiki for formatting. (been a few years since I've touched this and this was off the top of my head)
-
Hopefully this isn't a thread jack as I have a somewhat similar situation. I currently have both onboard NICs bonded going to a managed switch via LACP. I also have a 4 port intel NIC that I would like to utilize if it can provide me with some sort of benefit. The main question would be, would isolating plex to its own port free up the bonded connection and allow less overhead on the bonded connection? Therefore giving some benefit to moving plex to a dedicated NIC port? Plex is running in a docker in this case. A good example of a heavy network usage time would be say multiple plex streams which transferring data to a backup server. Would putting plex on a deticated port help in this situation?
-
Just wanted to thank John for this awesome application. I think I have used it before but haven't in a while and used it again today. Just simply incredible and nice to use. About the only thing I am looking forward to is when its able to test all drives at the same time to test out bus limitations. I see that's planned for the future. Great work John!
-
https://forums.unraid.net/topic/76129-wrong-disk-but-sn-matches/&share_tid=76129&share_fid=18593&share_type=t
-
Server is in a remote location so I can't do this easily. But I did open a thread. Though I get the feeling you are right, and the super.dat got corrupted. Would be nice if that could get fixed without doing another parity rebuild.
-
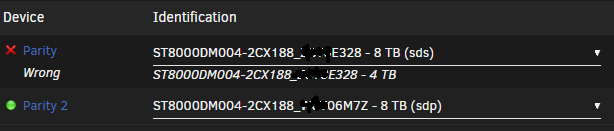
Just updated. What the hell? Why does unraid think this disk was 4TB? What do I do here? I could of course just start it and let it build parity but there should be no reason to need to do so.
-
Assuming you just want to have kodi run an update on a schedule. You can do that with cron and curl I think it was. Just look up how to update kodi via cmd line. Here it is put that in user scripts and run it as frequently as you want
-
Well it looks like the docker container is still on docker hub and the docker template is still on github. Wonder if you could still install it that way and just replace the script within the container with the latest version of the script? There is also this: https://github.com/johnodon/zapscrape This was definitely a crappy way for this docker to die. Would an alternative be the webgrab+ plus? Look like it can grab from zap2it also but I haven't tired it yet. Nevermind. I found a working solution. And I bet you know what that solution was. For everyone else. Look around, usual places. Only not linking to anything because I don't want to take away from johnodon's work and help the zap2xml dev find and ruin another project.
-
That's great and all, and google is helpful. But there used to be a search box at the top of each thread. Type in search term, hit enter. Not sure why we have had to go back in time. Also google search is definitely not better then all forum searches. Better then some yes, but some forums have much better laid out results.
-
Don't give radar the correct category in the download client setting. It cant process if it doesn't know where the files are

