




bastl
Members
-
Joined
-
Last visited
Everything posted by bastl
-
@xlucero1 I mean click the flash device in the Unraid webui. The flash device is your USB boot device where Unraid is installed on. Open the page for Unraid, navigate to the main section where you can find your array disks and your cache device, the page where you can also find the shutdown reboot buttons. You should see the flash drive there. Make sure the config i posted above is in the boot option you're using, usually under default.
-
I switched back to the 5.9 version from 5.10 not even because of the above error i encountered, also because the already adopted AP AC Pro in 5.10 lost randomly the adoption and because of this I also had to restore a backup of the Unifi appdata. Rewerting back to 5.9 wasn't possible. After that the AP won`t adopt. I had to remove it from the controller and had to reset it to default via ssh and trigger a new adoption. Before that I switched to "host" and after back to "bridge". Everything is working fine now. 👍
-
Thank you guys for the answer. I couldn't really wait for an answer. I'am on bleeding edge right now, as always. I used the "latest flag" with the old appdata and so far no errors, except of some in the Docker logs @linuxserver.io Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] 30-keygen: executing... [cont-init.d] 30-keygen: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 18, 2019 1:34:44 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request
-
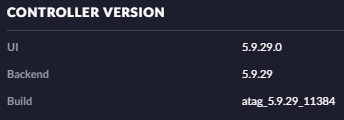
First of all thanks for that container. I'am currently running the old version with the unstable tag in the docker settings and never had any issues so far. linuxserver/unifi:unstable The controller software shows the following version: It showed me the last couple days a newer version 5.10 is available for download. Here is my question. If i switch to "latest" in the new container, does that mean it switches to 5.10 and btw which is the the latest LTS version? It's kinda confusing all these different version UBNT provides. Or is the better way to create the new container and set it to 5.9 first? Will it stay on 5.9 or will it also hint me for an update to 5.10? Questions questions questions. Don't know where to start 🤔 1. step: appdata already backed up
-
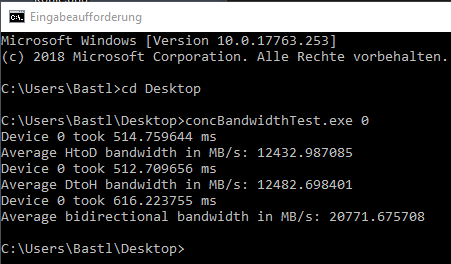
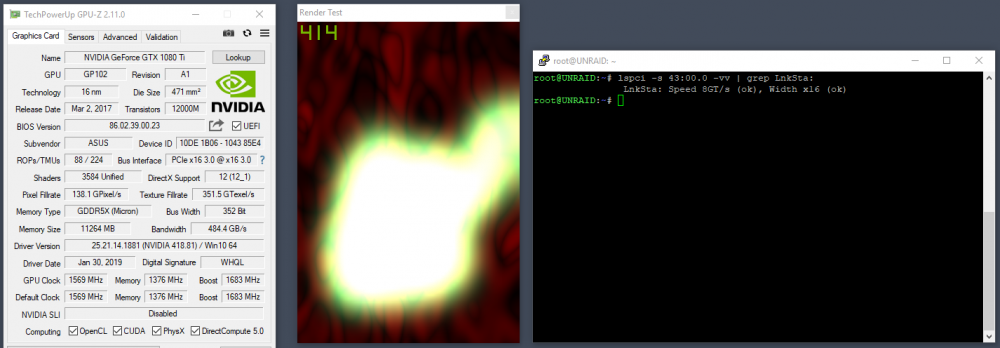
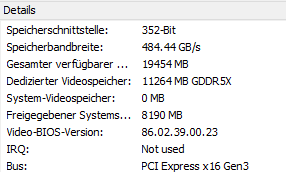
@rix Try the following, Get some load on the GPU for example with the render test in GPUZ and run the following comand in unraid. lspci -s 43:00.0 -vv | grep LnkSta: Adjust it so it matches your GPU. 43:00.0 is my passed through 1080ti. 8GT/s is what you wanna see for a x16 Gen3 speed. Mistake that everyone makes is to trust the link speeds GPUZ is reporting. Even if it's reporting x16 the Nvidia system info is the place shows it right. Another tool for testing is concBandwidthTest: https://forums.evga.com/PCIE-bandwidth-test-cuda-m1972266.aspx Run it from the comandline inside your VM and report back the values you get.
-
@xlucero1 You can't passthrough the audio device from group 15 as long as it isn't separated in it's own group. The ACS override option should have added an entry in your syslinux config already. Check your syslinux config, you can find it under main and click your flash device. Change it to the following and restart your server and check your system devices again. pcie_acs_override=downstream,multifunction
-
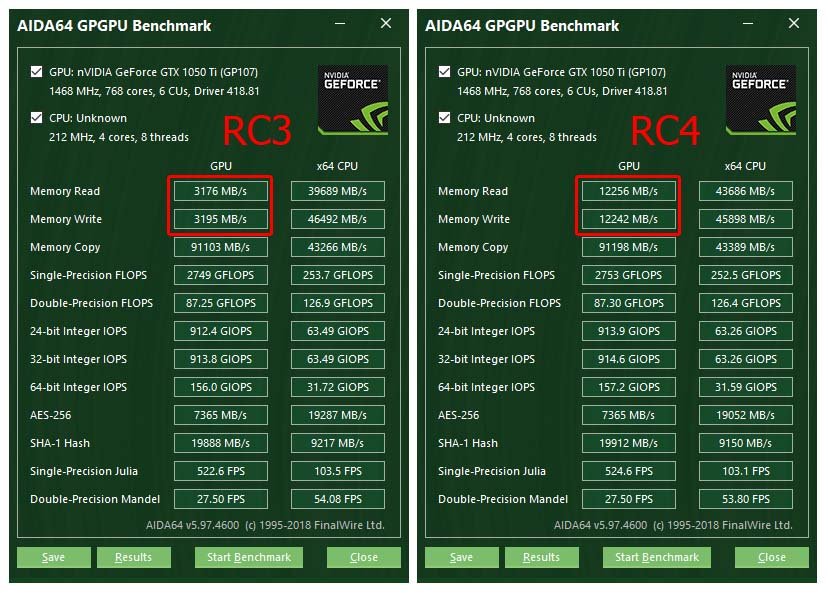
All tests i did so far, on synthetic benchmarks like cinebench or heaven and superposition you can't see that much of a difference. I guess the fact, that the benchmark loads all shaders and textures at the begining is the reason. Testing FarCry5 the performance gain I see is bigger. I guess games that constantly loading stuff will benefit more from that patch. I think that needs a couple more tests Edit: I posted some test in another forum related to this.
-
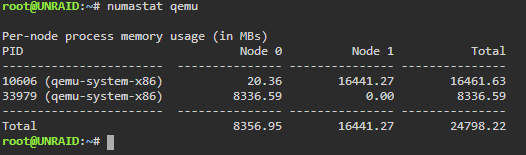
Thanks @Jerky_san You basically added the qemu lines at the end. For me in a test VM the Nvidia driver reports the 1050ti as x16 Gen3 now, before only x1. Another thing i noticed, this is the first VM using the correct memory i have setup. Usually with strict no matter what, it always used a couple MB from the other node. Coincidence? Never saw that before. <memory mode='strict' nodeset='0'/> Looks like a slight improvment to me. 😂 Couple more tests will follow tomorrow. Thanks for adding that fix 👍
-
@Jerky_san can you post your xml for reference?
-
@blaine07 There are still no Mojave web drivers for Nvidia 10 series cards available. I have the EVGA 1050ti and passthrough works but no acceleration with this card without the drivers.
-
I tried a lot of things to improve the performance of my VMs the last couple days and stumbled across that level1tech forum as i guess like everybody here. Great in depth information and i hope limetech is able to push that fix to us unraid users as soon as possible 😉 GIVE US THE FIX NOOOOOOW Just kiddin. Don't push features if they aren't tested in your product. Since I'am using Unraid, even with all the RC builds I tested (every public RC since early 2018) were stable for my needs. Sure there are always performance improvments possible often on the edge of stability. Always using the bleeding edge technology is fun, sure and for a techi nice to play with but for the general user often hard to handle. It's hard for @limetech and any over tech company to find a good middle way. I believe in you guys 👍
-
@jbrodriguez I've send you a pm with the support logs.
-
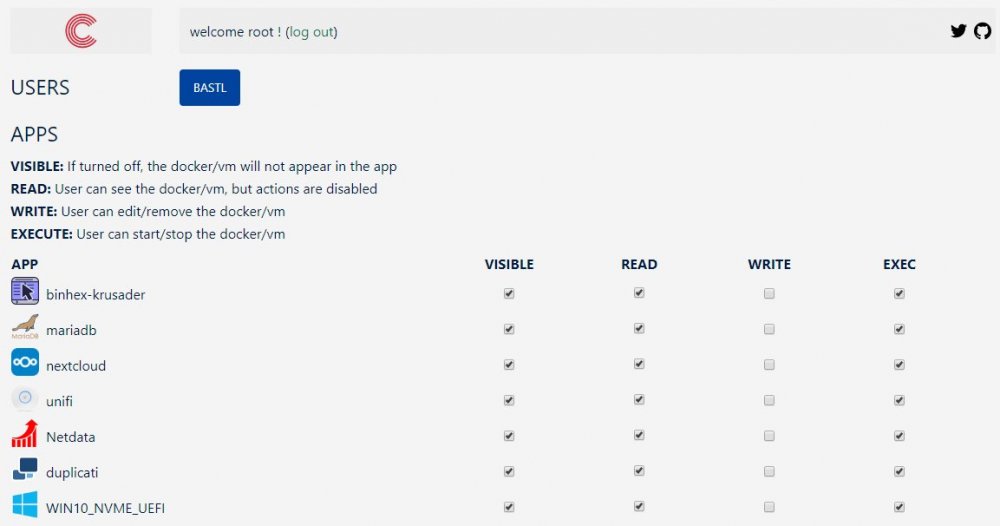
Visible is checked for that user and as you can see on the android app no docker or VMs are shown. @jbrodriguez
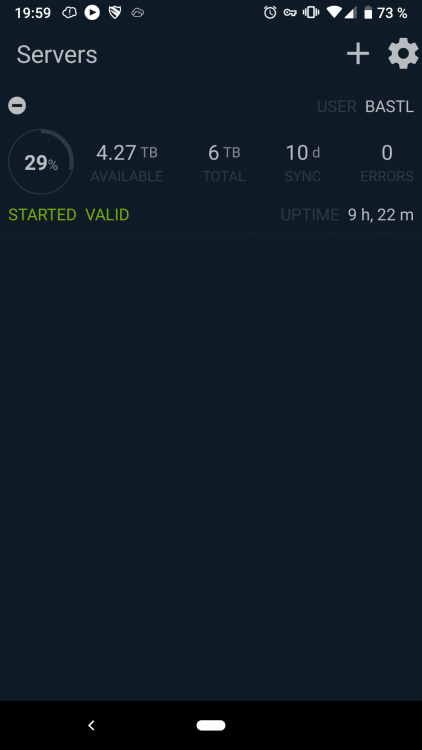
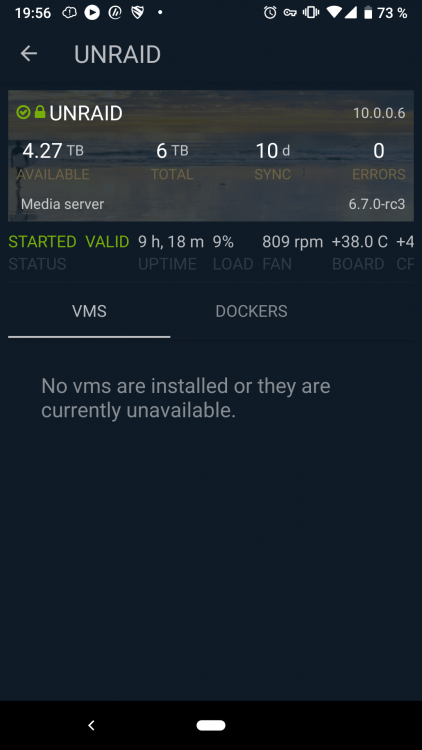
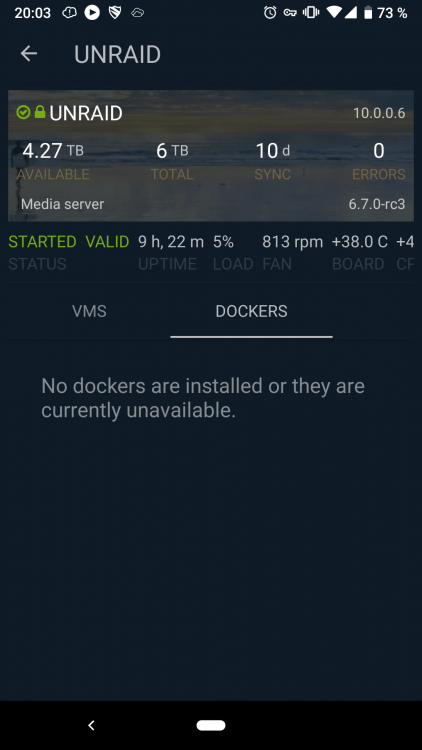
-
If I have a user setup in unraid and the same configured in the ControlR settings to be allowed to VIEW, READ and EXEC a specific VM or Docker that exact using should see that VM and or Docker in the android app, right? I am a bit confused right now. I had the user root conected before and all showed up. As soon as i use another user, none of the Docker or VMs are shown. Did i miss something? Currently on 6.7.0 RC3 and the newest Android app version 4.7.0
-
Nice to see the fresh design following the Unraid UI. The "card" for the apps are kinda to dark compared to the background with the dark unraid theme. Maybe some brighter edges of the "cards" to accentuate them better from each other.
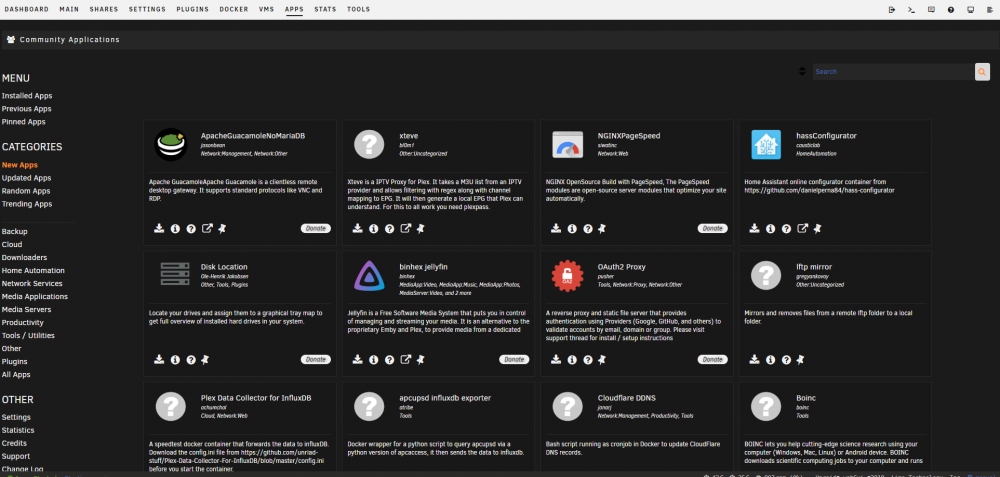
-
Thanks for the response. Would be great to have such a feature to unlock the app first before you're able to use it. Unfortunatly I'am not able to access the feedback.userreport.com page. No matter which browser i tried (IE, FF, Chrome, Edge) all showing a white page with the message "loading" and nothing happens.
-
I almost thought so. Btw is it possible to implement the use of the fingerprint sensor in the app, so you have to unlock the app before you use it? On Android if i close the app and restart it, it always saves the last logged in user.
-
Currently testing the 6.7.0rc1 and the Android app doesn't show any installed VMs or Dockers. "No vms/dockers are installed or they are currently unavailable"
-
@Magicaldave please remove the part after from your xml in the first post. This key is publicly available, sure, but apple sued people for puplishing this key. If you watched the videos from Spaceinvaders you should already know this.
-
@administrator recheck the msi fix after each Windows and Nvidia update. It happened twice for me now that the patched settings disappeared and i had to reapply them.
-
@Jomp Try the "Libvirt Hotplug USB" plugin. In the VM tab you can attach a USB device to a running VM. Works for me with every Phone and Tablet i tested.
-
@Alphahelix Jtok improved the original script. You can find his script with the above mentioned feature on his github page.
-
The numatune setting only works if you set your BIOS settings for the RAM to channel. On all TR4 boards i saw so far the default setting is auto and the CPU is presented as 1 node to the OS. You might have to check your manual of the board how to setup the RAM slots correctly for 2 dimms. You're the first one i see here in the forum with only 2 dimms on the TR4 platform.
-
Don't use the numatune option if you want the bandwith of both channels. Or set it to "interleaved" and specify both nodes. <numatune> <memory mode='interleave' nodeset='0-1'/> </numatune> It's up on you what works better for you. Depends on the application and the games. Some benefit of the higher bandwith some of the lower latency.
-
@mikeyosm You only using 2x16GB of RAM. You can't achive the performance of bare metal dual channel memory speed if you limit a VM to one channel only. Just sayin.












