

mgutt
-
Posts
11265 -
Joined
-
Last visited
-
Days Won
123
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by mgutt
-
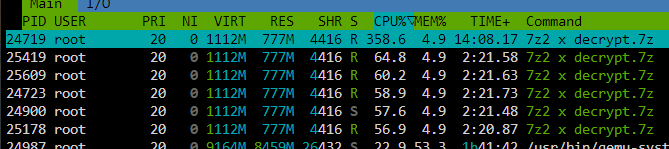
Can someone replace the p7zip package against the original 7z binary, which can be downloaded from the website? Its a full binary without dependencies: https://www.7-zip.org/download.html Regarding my tests it's at least 5x faster than the p7zip package. The main reason is that it is able to multi-thread/multi-core decompress:
-
Scroll down to "Sata Controller". The link should work except with Firefox. No as long you don't build your own list of commands (some examples in the first post, but those influence usually all devices of a specific type like "enable standby for all sata ports").
-
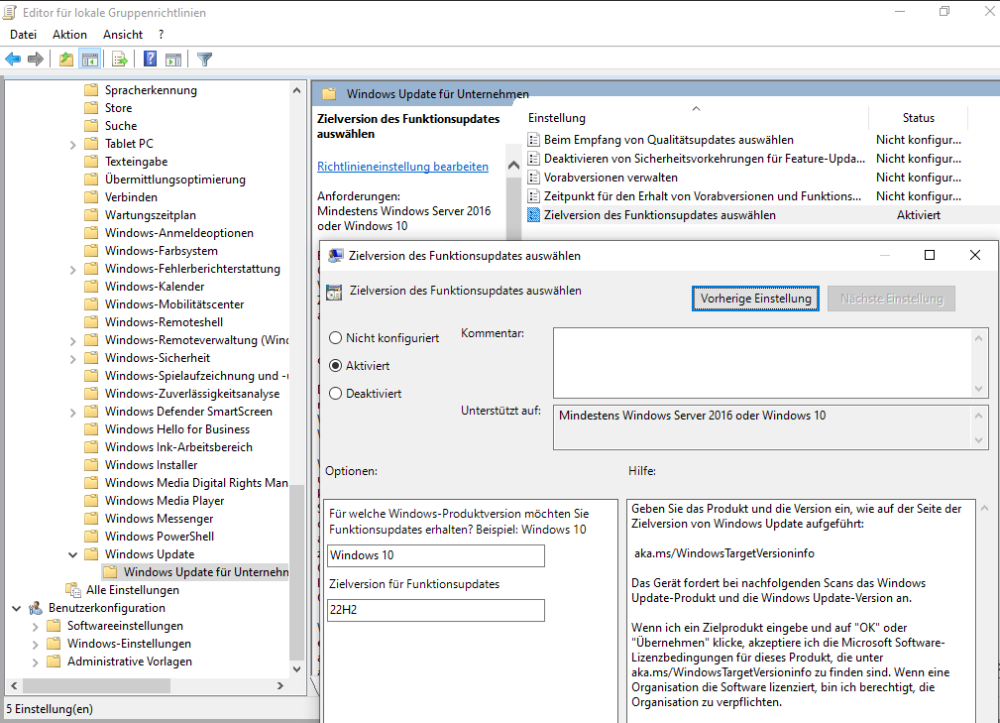
Ich habe heute eine Windows 10 VM installiert und bekam mit deaktiviertem br0 (sind ja die aktuell empfohlenen Netzwerkeinstellungen für Unraid) und Wechsel des VM Netzwerks auf vhost0 einfach kein Netzwerk-Gerät installiert. Hatte immer nur Code 56 angezeigt. Hier fand ich dann die Lösung: https://forum.proxmox.com/threads/windows-is-still-setting-up-the-class-configuration-for-this-device-code-56.100038/ Also Q35-5.1 musste ich wählen. Dann wurde die Netzwerkkarte korrekt installiert. Wer außerdem verhindern will, dass Windows 10 auf Windows 11 aktualisiert wird, der kann über die Gruppenrichtlinie "Zielversion des Funktionsupdates auswählen" die Zielversion "Windows 10" und "22H2" einstellen, also die letzte Windows 10 Version:
-
It seems I'm having the same problem on my test server with Unraid 6.12.4 Error message of Chrome Dev Tools: This server is relatively empty, so it does not have any Docker installed at all. But I think it could be because of my in my router (fritz.box). I had a similar issue in the past which got solved after disconnecting the server and deleting all network devices with the server name from my routers webgui network devices overview. At the moment some downloads are running. I will check this later and update my post. EDIT: And as I thought it was because of my fritz box. This router does crazy things if a mac address changes for a device, which has active port redirects. A similar issue causes the problems with MACVLAN and docker containers. My environment: - thoth, my productive server with the fixed ip .8 and active port redirects for the ports 80 and 443 - tower, my test server with an dynamic DHCP address, at the moment .48 A few days ago I changed the network card of "thoth". So it got a new mac address. This causes this mess: As you can see the productive server with the correct name is listed as an "offline device", but with active port redirects ("Portfreigabe"). In addition I got two "Tower" servers, which absolutelly does not make sense as my productive server never had this name. It is unchanged "thoth" since several years. How to solve this mess: - shutdown both servers - remove the port redirects of "thoth" - boot "thoth" - add the port redirects again Now I have my two network devices as expected: And my CPU dashboard works, too: But why does it solve the above problem? I think the reason is, that the Fritz Box randomly answers DNS requests for "tower.fritz.box" with the IP .8 or .48 as it knows about two different network devices with the same name. This bug (?) is present as long I can remind. But even if AVM solves this I'm still confused why my productive server sometimes is detected as "Tower". Does the server boot with this name and changes it after reading the config files from the USB drive?




-
Reading the first post is essential.
-
That's because only a tiny amount of recent power supplies are very efficient in low power scenarios. They are mentioned in the first post. Does not help I think as the problem is not the usage of the controller. It kills your C-States because of its pure existence 🤪
-
The ASM1061 is probably the problem. And this isn't efficient in low power scenarios.
-
And still nothing learned. Maybe you should create backups of appdata?! Maybe you should test this?! Maybe you should set the shutdown time earlier?! A crashing computer can kill random data. This shouldn't be surprising. What do you expect? Plex can't magically restore deleted data. Maybe you should install Plex correctly by removing old data first?! And of course check your path. I mean you are currently using both at the same time.
-
I would try it with Ubuntu. Maybe unRAID is shipped with an older driver.
-

Gigabyte B760M Gaming X DDR4 Messung und SATA Erweiterung
mgutt replied to mgutt's topic in NAS/Server Eigenbau & Hardware
Ausbauen und vergleichen. -
Ja der JMB unterstützt keinen Standby. Du musst die Kommandos einzeln ausführen und die bei den SATA bezogenen Kommandos nur bei den Onboard "hostX" SATA Buchsen das Kommando ausführen. Die Kommandos sind im englischen Powertop Thread aufgeführt.
-
Powertop liest Werte von der CPU aus und interpretiert die als C9 oder C10. Es kann gut sein, dass die in einer der Versionen falsch ausgelesen werden. Ändert aber nichts daran, dass die entsprechenden so anliegen. Naja 15 ist deutlich aktueller als 8.
-
Nextcloud Sicherheits- & Einrichtungswarnungen beheben
mgutt replied to Anym001's topic in Anleitungen/Guides
Man greift auch zu Hause über die Domain zu. Die genannten Warnungen sind auch nicht anders lösbar. -
Gigabyte B760M Gaming X DDR4 Messung und SATA Erweiterung
mgutt replied to mgutt's topic in NAS/Server Eigenbau & Hardware
Ja bei powertop runterscrollen und du solltest sehen, dass die iGPU auf RC6 steht. -
Gigabyte B760M Gaming X DDR4 Messung und SATA Erweiterung
mgutt replied to mgutt's topic in NAS/Server Eigenbau & Hardware
Auto tune ausgeführt? iGPU Treiber installiert? Anderen M.2 Slot getestet? -
Ja, da hätte ich auch mal drauf kommen können 😅 Danke!
-
Da gibt es aber auch massig weitere Angebote: https://www.mydealz.de/search?q=Thinkcentre Ich hätte auch noch einen M920x für 350 € zu verkaufen. Der hat den Charm, dass echt viele SSDs reinpassen. Spielt keine Rolle.
-
Hast du wie gepostet p- geschrieben?
-
Der würde sich genauso anbieten. Zum Lenovo gibt es hier übrigens auch einen Thread: Jo DLNA halte ich für ziemlichen Müll, aber ja warum nicht. Du brauchst nur eben einen Container, der einen DLNA-Server bereitstellt. Ich würde aber eher Plex oder Jellyfin nutzen. Wirst du erst sehen, wenn du es testest. Normalerweise laufen aber Intel 2.5G Controller sehr sparsam. Nur ob sie C8 verhindern, hängt extrem von der jeweiligen Hardware ab. Wenn sie günstig ist, ok, aber ansonsten brauchst du eigentlich keine so gute SSD. Eine Evo reicht. Du kannst 3200 Mhz überall verbauen. Langsamer taktet RAM immer.
-
Ich habe eben in den Logs diverse Fehlermeldungen vorgefunden. Hier ein Beispiel: 2023-09-24 22:06:39.214 WARNING (MainThread) [homeassistant.components.zha.core.cluster_handlers] [0x709E:1:0x0002]: async_initialize: all attempts have failed: [DeliveryError('Failed to deliver message: <EmberStatus.DELIVERY_FAILED: 102>'), DeliveryError('Failed to deliver message: <EmberStatus.DELIVERY_FAILED: 102>'), DeliveryError('Failed to deliver message: <EmberStatus.DELIVERY_FAILED: 102>'), DeliveryError('Failed to deliver message: <EmberStatus.DELIVERY_FAILED: 102>')] Wenn man googled, stößt man auf Themen rund um Zigbee Aktoren. Also habe ich versucht herauszufinden welcher Aktor das sein könnte. Ist natürlich super, dass da nur "0x709E" steht. 😒 Ich habe dann aber herausgefunden, dass man ein Zigbee Gerät anklicken und dann auf "Netzwerk anzeigen" gehen muss: Und dann kann man oben links in der Suche die Zeichenfolge eingeben und der entsprechende Aktor wird hervorgehoben: Aber was ist nun das ":1:0x0002" ? Ist da mit die "DeviceTemperature" gemeint? Und wenn ja, was soll mir das nun sagen. Kann HA den Wert nicht auslesen oder was ist das Problem? Wirklich Sinn macht das jedenfalls nicht, da genau dieser Wert nicht verfügbar ist: Oder ist das schon das Problem? Ich habe den Wert aus Spaß mal aktiviert und er wird scheinbar auch ausgelesen: Ich habe daher das Gefühl, dass ich an der falschen Stelle schaue?!





-
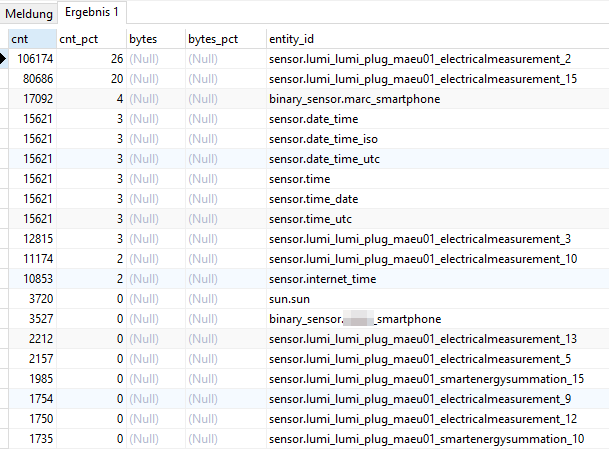
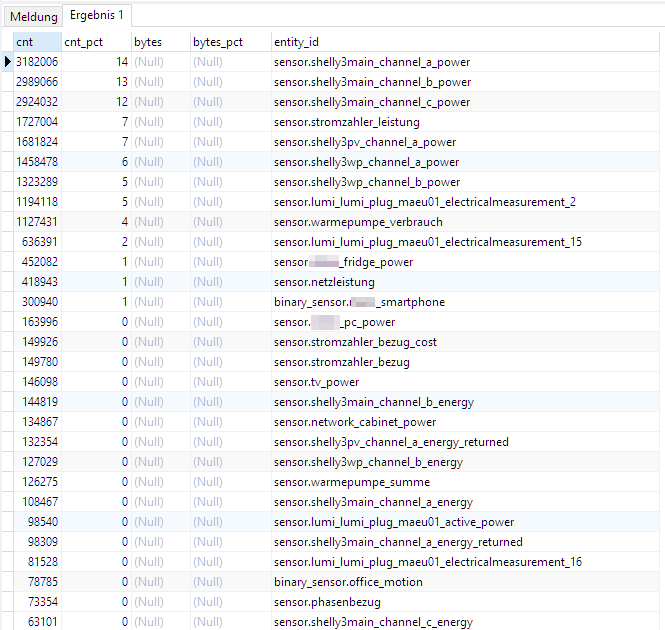
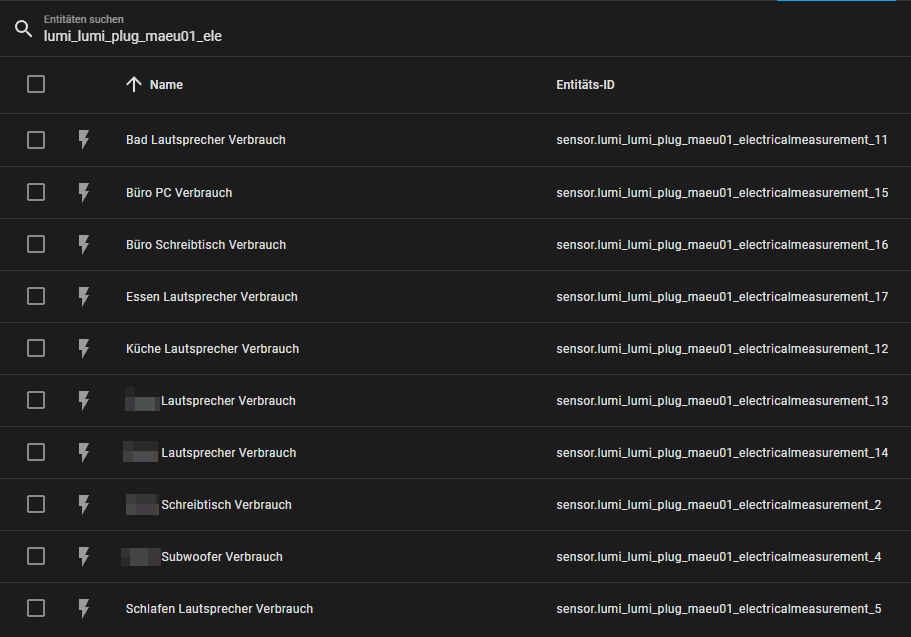
Da ich mittlerweile bei 8GB angekommen bin 😅, wollte ich mal schauen, wo man vielleicht noch was Platz sparen kann. Ein wie ich finde interessanter Punkt ist folgender: Bei einem benutzerdefinierten Sensor (configuration.yaml), der sich auf mehrere Entitäten bezieht, wird dieser jedes mal berechnet, wenn nur eine der beteiligen Entitäten einen neuen Wert meldet. Addiert man also zB wie ich drei Sensoren eines Shelly 3EM, um den Gesamtverbrauch aller drei Phasen als Summe zu erhalten, so würde das Ergebnis alle paar Sekunden berechnet und in die Datenbank geschrieben. Das kann man verhindern, in dem man einen time_pattern trigger dem sensor-Block voranstellt. Hier aktualisiere ich zB die Summe nur alle 5 Minuten: - name: Wärmepumpe Summe unique_id: shelly3wp_energy unit_of_measurement: 'kWh' state: >- {#- on reboot some sensors do not return a number (instead they return "unknown" or "unavailable") -#} {%- if is_number(states("sensor.shelly3wp_channel_a_energy")) and is_number(states("sensor.shelly3wp_channel_b_energy")) and is_number(states("sensor.shelly3wp_channel_c_energy")) -%} {{ (states("sensor.shelly3wp_channel_a_energy") | float + states("sensor.shelly3wp_channel_b_energy") | float + states("sensor.shelly3wp_channel_c_energy") | float) | round(2) }} {%- else -%} unavailable {%- endif -%} device_class: energy state_class: total_increasing Oder hier nur alle 30 Sekunden: - trigger: - platform: time_pattern seconds: "/30" sensor: - name: Wärmepumpe Verbrauch unique_id: shelly3wp_power unit_of_measurement: 'W' state: >- {#- on reboot some sensors do not return a number (instead they return "unknown" or "unavailable") -#} {%- if is_number(states("sensor.shelly3wp_channel_a_power")) and is_number(states("sensor.shelly3wp_channel_b_power")) and is_number(states("sensor.shelly3wp_channel_c_power")) -%} {{ (states("sensor.shelly3wp_channel_a_power") | float + states("sensor.shelly3wp_channel_b_power") | float + states("sensor.shelly3wp_channel_c_power") | float) | round(2) }} {%- else -%} unavailable {%- endif -%} device_class: power state_class: measurement P.S. das Prüfen auf "is_number" und Setzen auf "unavailable" hat geholfen, dass der Sensor nach einem Neustart des Containers nicht mehr auf 0 zurückspringt. Seitdem habe ich ausschließlich saubere Werte in der Datenbank. Was eventuell auch noch interessant ist, dass neben der Datenbank-Tabelle "states" auch "statistics_short_term" einiges an Speicherplatz belegt: Dazu recherchiere ich aber später noch mal. Bis dahin habe ich die Abfrage aus dem verlinkten Thread noch mal ausgeführt: SELECT COUNT(*) AS cnt, COUNT(*) * 100 / (SELECT COUNT(*) FROM states) AS cnt_pct, SUM(LENGTH(attributes)) AS bytes, SUM(LENGTH(attributes)) * 100 / (SELECT SUM(LENGTH(attributes)) FROM states) AS bytes_pct, entity_id FROM states GROUP BY entity_id ORDER BY cnt DESC Das Ergebnis von damals: Und von heute: Was mir dabei auffällt: 1.) Umso häufiger ein Gerät beim Verbrauch schwankt, umso häufiger kommt es zu DB-Einträgen. Vom Prinzip logisch, ich hätte nur nicht gedacht, dass alleine der Shelly 3EM, der den Allgemeinstrom des Stromzählers ermittelt, 39% (14+13+12) aller DB-Einträge ausmacht. Wie soll ich das reduzieren?! 2.) Benutzerdefinierte Sensoren / Entitäten werden nicht aus der DB entfernt, obwohl sie nicht mehr existieren. zB alles was mit "stromzahler" anfängt, gibt es gar nicht mehr. Ich habe schon über Entwicklerwerkzeuge > Dienste > Recorder: Purge Entities > Entity Globs to remove > "- sensor.stromzahler*" versucht diese Entitäten zu löschen, aber sie bleiben hartnäckig in der Datenbank enthalten 🤔 3.) Man sollte grundsätzlich jeden Sensor / Entität beim Hinzufügen zu Home Assistant umbenennen. zB "lumi_lumi_blablabla" ist wenig aussagekräftig. Da darf man dann erst mal die Entitäten-Liste durchsuchen: Wobei ich aber auch hier überfragt bin, wie ich die Menge der DB-Einträge beeinflussen könnte. 🤔

-
Mit RAM Defekt hat das nichts zu tun. Da gäbe es andere Fehler. Jetzt musst du einfach warten bis der Fehler erneut nachvollziehbar ist. Wie gesagt schreibt irgendwas in den RAM oder überlastet im Allgemeinen den RAM.
-
Aktuelles Betriebssystem behalten und Unraid installieren
mgutt replied to SkiperTheBoss's topic in Deutsch
Du brauchst logischerweise zusätzliche Platten für die Daten von unRAID. Wenn du die in BTRFS formatierst, kannst du sogar mit einem Windows Treiber auf die Daten zugreifen. Dann eben Stick rein, unRAID bootet, Stick raus, Windows bootet. Du darfst nur eben wie gesagt nicht mit unRAID die Windows Platte irgendwo einbinden. Also als Unassigned Disk lassen. Und in Windows darfst du nichts mit der Parity Disk machen und von den Array disks nur lesend zugreifen oder nach jedem Boot die Parity reparieren. -
Oh, dann sollte ich an der Stelle das dry-run denke ich weg lassen. Der Test kann ja ruhig in beiden Fällen wirklich gemacht werden. Danke für den Hinweis. Laut meiner Recherche wird der Zugriff als Root-User automatisch in nobody geändert: https://superuser.com/a/1226152/129262 Das ist halt das was ich meine. Wenn du auf ein externes System schreibst, kannst du niemals sicher sein, dass du auch da root bist, außer du nutzt wirklich den root-Login der Zielmaschine, was ich wieder als unsicher betrachten würde. Nur damit du das auch mal selber prüfen kannst. So kannst du alle Dateien finden, die dem User root gehören, die im appdata Share liegen: find /mnt/user/appdata -uid 0 Wenn du nun dieses Verzeichnis sicherst, kannst du das selbe Kommando auf der Zielmaschine selbst ausführen, um zu schauen, ob die Rechte noch passen. Zählen könnte man dann zB so: find /mnt/cache/appdata -uid 0 | wc -l find /mnt/extern/server/backups/appdata -uid 0 | wc -l Beide müssen logischerweise die exakte selbe Anzahl zurückgeben. Noch eine Option wäre es die Backups von Cache auf Array zu machen und das Backup dann in ein tar zu packen, was du dann auf ein externes Ziel deiner Wahl kopierst. Dafür reicht dann "cp". Die Hardlinks gehen dann natürlich nicht. Aber wenn man den gesamten Backup-Ordner sichert, dann erkennt tar die Hardlinks und fügt die Datei auch nur jeweils 1x im Archiv hinzu. Vorteil in einem tar ist, dass die Dateirechte im Archiv selbst gesichert werden. Dadurch kann man ein tar auch zB auf eine Windows-Maschine sichern und verliert nichts.
-
Nur für Unraid-Enthusiasten: USB 3.1 SLC Stick von Swissbit
mgutt replied to mgutt's topic in NAS/Server Eigenbau & Hardware
Ich habe zwischenzeitlich schon wieder welche gekauft. Sind noch 2 oder 3 sogar noch da. Schreib mir einfach eine Email / PN.


















