LFFPicard
Members
-
Joined
-
Last visited
Everything posted by LFFPicard
-
So, Updated my server a few days back. I have a 1050 Ti, so as soon as I rebooted the server, the GPU was not working. I grabbed the legacy drivers for my GPU, like I have done before, to get it working again and rebooted my server. Now, before I grabbed the legacy drivers, both Plex and Unmanic would not start due to the properties specifying a card that can not be found. After grabbing the legacy drivers, they both start again. Unmanic has started converting with no issues. But Plex, for some reason, will not HW transcode anymore and is just chewing up my CPU. I have checked all the settings, and nothing has changed. The only thing that has happened is the server update and regrabbing the legacy drivers. So I am unsure what is wrong and why it won't HW transcode anymore. The Plex logs show everything should be fine, and the transcoder settings in Plex settings are all correct. I really am unsure why it is not working. **** permissions for /dev/dri/renderD128 are good **** **** permissions for /dev/dri/card0 are good **** Setting permissions on /transcode
-
Well, I started by struggling with it. But I am slowly finding out more and more as I nose around. I am a solid Sonarr and Radarr user so it is all familiar, but I must say some of the features on this are damn awesome. I just came across the trash guides importer. Very nice! I am struggling with root folders and matching, but I am trying to make it work with a current manual setup for Formula 1 and WWE so I will keep tweaking until I get it sorted. Great work! EDIT: Is there a way to change the scanner? I currently use TVDB for my Formula 1 naming so that it works in Plex, but when importing my 970! F1 files it fails to match a fair chunk of them due to the different naming convention SportsDB uses. Maybe if I can change to the TVDB scanner for import and then preview rename with SportsDB? I will need to do some testing to see if SportsDB naming works in Plex.
-
Hi, I have been getting a failed backup recently; the last working backup is now just over a month ago. The log shows it is because of PLex with the error.... [28.10.2025 03:30:14][ℹï¸][plex] Backing up plex... [28.10.2025 04:15:16][debug][plex] Tar out: tar: /mnt/cache/appdata/plex/Library/Application Support/Plex Media Server: file changed as we read it [28.10.2025 04:15:16][âŒ][plex] tar creation failed! Tar said: tar: /mnt/cache/appdata/plex/Library/Application Support/Plex Media Server: file changed as we read it [28.10.2025 04:16:38][debug][plex] lsof(/mnt/cache/appdata/plex) But further up the log it shows that it did stop the container without issue, so I do not know why this would be happening if the container is stopped. I did try and search through this thread but every search result took me to the wrong post so I could not find anything after 20mins of searching. Hope this is a simple fix, if anyone has any ideas that would be great. backup.debug.log
-
I am also interested in this. I just looked at this and spend more time than I care to admit setting up reverse proxy with SWAG only to then notice the version and wanted to move the stored files directory as looking at the template it is pointing /shared to appdata. But looking in the advanced admin settings I can see more options so reluctant to tinker until the version is resolved. Any update on this?
-
Hi, Stupid question. When setting up an API for IGDB it takes me to Twitch to intergrate the application, what do I put in the OAuth url? It wont let me create an API without this.
-
I fixed this. For some reason even though I changed the tag and it downloaded 1.19.4 it was still loading the 1.19.3 server. I went into my cache and the .jar for 1.19.3 was still there. I deleted it leaving only 1.19.4 and it now loaded the correct server.
-
I changed the tag to 1.19.4 as it was set to .3 and it redownloaded a package but when I load my client the server is still showing as 1.19.3. Will this be updated? Edit: Sorry, this is for the Fabric server.
-
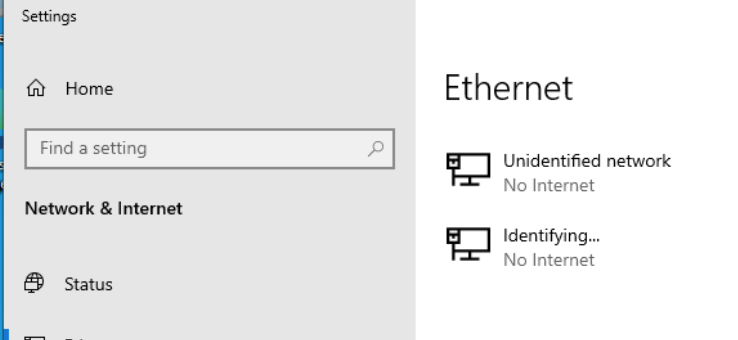
Sorry to necro. I have the same issue. Stupid question, how would I find the MAC address? I done a bit of googling and it appears dockers will have different MAC addresses, but how do I find one for a VM? I loaded the Windows 10 VM but as it can not find a network adapter ipconfig /all wont give a MAC address. EDIT: I got it working and the mac address is the same as my server. But now it is just stuck identifying.
-
I am moving 6TB at the moment and noticed the yellow indicators as well. As I can not see the log until it is finished, will the log for those be obvious so I can see what was wrong? I am assuming it is mostly it could not delete the source folder as it was in use or not empty or something.

-
Hi Ich, Having an issue with Conan. Thought I would set a server up now there is a new expansion for it but using default template (Not adding any workshop until I can get a stable server set up) I am getting alot of errors. I have restarted the container a couple times as a few messages said updates applied on next restart so thought that might clear up some errors but still getting loads. See pastebin below.. Any ideas? https://pastebin.com/y9TRwQg8 Thanks in advance
-
Yep! Perfect thank you, I can unleash it again! Thanks for all your hard work.
-
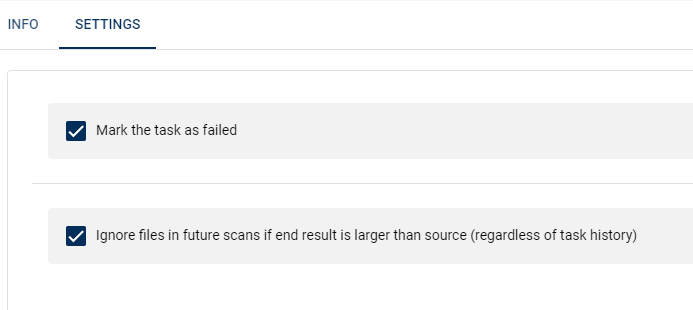
Hi Josh, Sorry for the delay, I moved home and then had to move the server so it has been all up in the air a bit. I think I set it up right according to the description you put in the plugin. I have had a bunch of stuff marked as failed when processing, I checked a couple and they had previously been converted before so I believe it is now working. If you would not mind skimming over the output log and just verifying I will let it loose on my library again. Thanks! https://pastebin.com/kWNHthRb
-
Can you also show us the config for the reject if larger plugin Ah yes sorry.
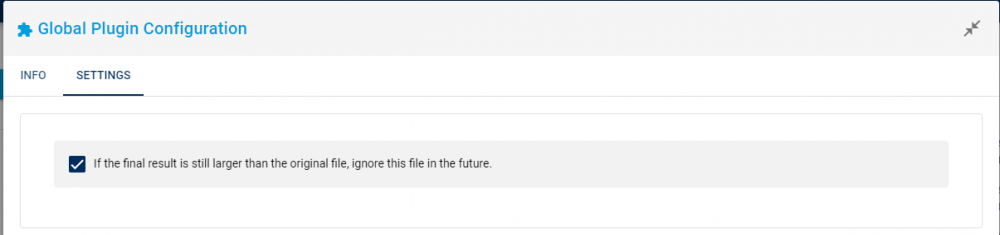
-
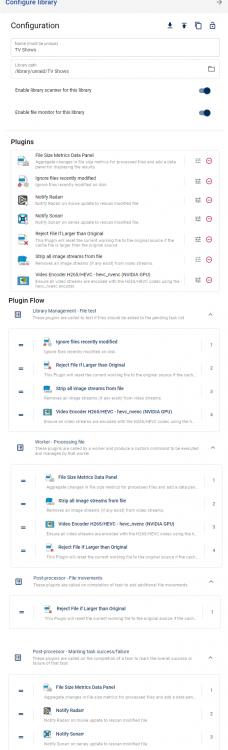
Sounds like you have your stack configured incorrectly. Could you please share a screenshot of your library config and the plugin flow for the library Hi josh, Thanks for taking the time to look at this. See below the config and the flow. Just noticed I have notify Radarr in there, I can get rid of that as it is TV Shows.
-
This is the log of that particular file. Workers Worker-W0: Charlie's Angels - S03E03 - Angel Com.. 27% State Processing task... Current Runner Video Encoder H265/HEVC - hevc_nvenc (NVIDIA GPU) ETC: 1 minute, 31 seconds Pending Tasks /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E08 - Pom Pom Angels DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 4/Charlie's Angels - S04E01 - Love Boat Angels (1) DVD Proper.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E05 - Angels in Springtime DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 4/Charlie's Angels - S04E12 - Angel Hunt DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E04 - Angels on High DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E09 - Angels Ahoy! DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E06 - Winning is For Losers DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E07 - Haunted Angels DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E10 - Mother Angel DVD.mkv /library/unraid/TV Shows/Charlie's Angels/Season 3/Charlie's Angels - S03E12 - Angels Belong in Heaven DVD.mkv Completed Tasks Charlie's Angels - S04E05 - Angels at the Altar DVD Proper.mkv Just Now Charlie's Angels - S04E03 - Angels Go Truckin' DVD Proper.mkv 2 minutes ago Charlie's Angels - S04E11 - Angels on Campus DVD.mkv 3 minutes ago Charlie's Angels - S04E07 - Caged Angel DVD Proper.mkv 5 minutes ago Charlie's Angels - S04E09 - The Prince and the Angel DVD Proper.mkv 7 minutes ago Charlie's Angels - S04E10 - Angels on Skates DVD.mkv 8 minutes ago Charlie's Angels - S04E26 - One Love.Two Angels (2) DVD.mkv 10 minutes ago Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD.mkv 12 minutes ago Charlie's Angels - S04E24 - Toni's Boys DVD.mkv 13 minutes ago Charlie's Angels - S04E23 - Three for the Money DVD.mkv 15 minutes ago © 2018-2022 by Josh Sunnex Version: 0.2.0~a3bd45a Completed Tasks Search Charlie's Angels - S04E03 - Angels Go Truckin' DVD Proper.mkv 2022-05-09 18:26:52 Success Charlie's Angels - S04E11 - Angels on Campus DVD.mkv 2022-05-09 18:25:16 Success Charlie's Angels - S04E07 - Caged Angel DVD Proper.mkv 2022-05-09 18:23:40 Success Charlie's Angels - S04E09 - The Prince and the Angel DVD Proper.mkv 2022-05-09 18:22:00 Success Charlie's Angels - S04E10 - Angels on Skates DVD.mkv 2022-05-09 18:20:23 Success Charlie's Angels - S04E26 - One Love.Two Angels (2) DVD.mkv 2022-05-09 18:18:46 Success Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD.mkv 2022-05-09 18:17:03 Success Charlie's Angels - S04E24 - Toni's Boys DVD.mkv 2022-05-09 18:15:24 Success Charlie's Angels - S04E23 - Three for the Money DVD.mkv 2022-05-09 18:13:46 Success Charlie's Angels - S04E22 - Nips and Tucks DVD.mkv 2022-05-09 18:12:08 Success Charlie's Angels - S04E19 - Dancing Angels DVD.mkv 2022-05-09 18:10:29 Success Charlie's Angels - S04E18 - Homes, $weet Homes DVD.mkv 2022-05-09 18:08:53 Success Charlie's Angels - S04E21 - An Angel's Trail DVD.mkv 2022-05-09 18:07:18 Success Charlie's Angels - S04E20 - Harrigan's Angel DVD.mkv 2022-05-09 18:05:39 Success Charlie's Angels - S04E17 - Catch a Fallen Angel DVD.mkv 2022-05-09 18:04:00 Success Records per page: 15 1-15 of 129410 Completed Task Details RUNNER: File Size Metrics Data Panel [Pass #1] Executing plugin runner... Please wait Runner did not request to execute a command RUNNER: Strip all image streams from file [Pass #1] Executing plugin runner... Please wait Runner did not request to execute a command RUNNER: Video Encoder H265/HEVC - hevc_nvenc (NVIDIA GPU) [Pass #1] Executing plugin runner... Please wait Plugin runner requested for a command to be executed by Unmanic COMMAND: ffmpeg -hide_banner -loglevel info -hwaccel cuda -hwaccel_device 0 -i /library/unraid/TV Shows/Charlie's Angels/Season 4/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD.mkv -strict -2 -max_muxing_queue_size 2048 -threads 1 -map 0:v:0 -map 0:a:0 -c:v:0 hevc_nvenc -profile:v:0 main -preset slow -c:a:0 copy -y /tmp/unmanic/unmanic_file_conversion-1652086167.4177125/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD-1652086167.4177053-WORKING-3.mkv LOG: Input #0, avi, from '/library/unraid/TV Shows/Charlie's Angels/Season 4/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD.mkv': Metadata: encoder : VirtualDubMod 1.5.4.1 (build 2178/release) IAS1 : English Duration: 00:49:35.31, start: 0.000000, bitrate: 987 kb/s Stream #0:0: Video: mpeg4 (Advanced Simple Profile) (XVID / 0x44495658), yuv420p, 512x384 [SAR 1:1 DAR 4:3], 914 kb/s, 23.98 fps, 23.98 tbr, 23.98 tbn, 23.98 tbc Stream #0:1: Audio: mp3 (U[0][0][0] / 0x0055), 48000 Hz, mono, fltp, 59 kb/s Stream mapping: Stream #0:0 -> #0:0 (mpeg4 (native) -> hevc (hevc_nvenc)) Stream #0:1 -> #0:1 (copy) Press [q] to stop, [?] for help [mpeg4 @ 0x555fde575c00] Video uses a non-standard and wasteful way to store B-frames ('packed B-frames'). Consider using the mpeg4_unpack_bframes bitstream filter without encoding but stream copy to fix it. Output #0, matroska, to '/tmp/unmanic/unmanic_file_conversion-1652086167.4177125/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD-1652086167.4177053-WORKING-3.mkv': Metadata: IAS1 : English encoder : Lavf58.45.100 Stream #0:0: Video: hevc (hevc_nvenc) (Main), nv12, 512x384 [SAR 1:1 DAR 4:3], q=-1--1, 2000 kb/s, 23.98 fps, 1k tbn, 23.98 tbc Metadata: encoder : Lavc58.91.100 hevc_nvenc Side data: cpb: bitrate max/min/avg: 0/0/2000000 buffer size: 4000000 vbv_delay: N/A Stream #0:1: Audio: mp3 (U[0][0][0] / 0x0055), 48000 Hz, mono, fltp, 59 kb/s frame= 331 fps=0.0 q=15.0 size= 2304kB time=00:00:14.95 bitrate=1262.3kbits/s speed=29.8x frame= 682 fps=680 q=13.0 size= 6912kB time=00:00:29.59 bitrate=1913.5kbits/s speed=29.5x frame= 1084 fps=721 q=14.0 size= 10496kB time=00:00:46.34 bitrate=1855.3kbits/s speed=30.8x frame= 1385 fps=691 q=14.0 size= 14592kB time=00:00:58.89 bitrate=2029.6kbits/s speed=29.4x frame= 1725 fps=689 q=15.0 size= 16640kB time=00:01:13.08 bitrate=1865.3kbits/s speed=29.2x frame= 1993 fps=663 q=16.0 size= 21248kB time=00:01:24.26 bitrate=2065.7kbits/s speed= 28x frame= 2321 fps=662 q=18.0 size= 24064kB time=00:01:37.94 bitrate=2012.7kbits/s speed=27.9x frame= 2602 fps=649 q=16.0 size= 27136kB time=00:01:49.65 bitrate=2027.2kbits/s speed=27.4x frame= 2951 fps=655 q=14.0 size= 30464kB time=00:02:04.22 bitrate=2009.0kbits/s speed=27.6x frame= 3313 fps=661 q=14.0 size= 33792kB time=00:02:19.32 bitrate=1987.0kbits/s speed=27.8x frame= 3665 fps=665 q=13.0 size= 37376kB time=00:02:34.00 bitrate=1988.1kbits/s speed= 28x frame= 4020 fps=669 q=14.0 size= 40960kB time=00:02:48.81 bitrate=1987.6kbits/s speed=28.1x frame= 4348 fps=668 q=13.0 size= 43520kB time=00:03:02.49 bitrate=1953.6kbits/s speed= 28x frame= 4700 fps=670 q=14.0 size= 48128kB time=00:03:17.16 bitrate=1999.7kbits/s speed=28.1x frame= 5097 fps=678 q=14.0 size= 52736kB time=00:03:33.72 bitrate=2021.4kbits/s speed=28.4x frame= 5472 fps=683 q=14.0 size= 56064kB time=00:03:49.36 bitrate=2002.4kbits/s speed=28.6x frame= 5844 fps=686 q=14.0 size= 60672kB time=00:04:04.89 bitrate=2029.5kbits/s speed=28.8x frame= 6230 fps=691 q=13.0 size= 64000kB time=00:04:20.97 bitrate=2009.0kbits/s speed=28.9x frame= 6604 fps=694 q=14.0 size= 67328kB time=00:04:36.55 bitrate=1994.4kbits/s speed=29.1x frame= 6974 fps=696 q=13.0 size= 70912kB time=00:04:52.00 bitrate=1989.4kbits/s speed=29.2x frame= 7350 fps=699 q=13.0 size= 74752kB time=00:05:07.70 bitrate=1990.1kbits/s speed=29.3x frame= 7722 fps=701 q=10.0 size= 78592kB time=00:05:23.23 bitrate=1991.8kbits/s speed=29.3x frame= 8094 fps=703 q=10.0 size= 82688kB time=00:05:38.73 bitrate=1999.7kbits/s speed=29.4x frame= 8483 fps=706 q=14.0 size= 86272kB time=00:05:54.96 bitrate=1991.0kbits/s speed=29.5x frame= 8843 fps=706 q=13.0 size= 90880kB time=00:06:09.96 bitrate=2012.3kbits/s speed=29.6x frame= 9231 fps=709 q=14.0 size= 95232kB time=00:06:26.16 bitrate=2020.3kbits/s speed=29.7x frame= 9609 fps=711 q=14.0 size= 99840kB time=00:06:41.92 bitrate=2034.9kbits/s speed=29.7x frame= 9975 fps=711 q=15.0 size= 103936kB time=00:06:57.19 bitrate=2040.9kbits/s speed=29.8x frame=10341 fps=712 q=16.0 size= 109056kB time=00:07:12.45 bitrate=2065.8kbits/s speed=29.8x frame=10747 fps=715 q=13.0 size= 113664kB time=00:07:29.37 bitrate=2072.1kbits/s speed=29.9x frame=11129 fps=717 q=16.0 size= 118272kB time=00:07:45.31 bitrate=2082.2kbits/s speed= 30x frame=11539 fps=720 q=15.0 size= 122112kB time=00:08:02.42 bitrate=2073.6kbits/s speed=30.1x frame=11952 fps=723 q=15.0 size= 125696kB time=00:08:19.63 bitrate=2060.9kbits/s speed=30.2x frame=12333 fps=724 q=14.0 size= 129280kB time=00:08:35.52 bitrate=2054.4kbits/s speed=30.3x frame=12698 fps=725 q=13.0 size= 132608kB time=00:08:50.76 bitrate=2046.7kbits/s speed=30.3x frame=13052 fps=724 q=14.0 size= 136704kB time=00:09:05.52 bitrate=2052.9kbits/s speed=30.3x frame=13412 fps=724 q=14.0 size= 141056kB time=00:09:20.54 bitrate=2061.4kbits/s speed=30.3x frame=13775 fps=724 q=14.0 size= 144896kB time=00:09:35.66 bitrate=2061.9kbits/s speed=30.3x frame=14139 fps=724 q=14.0 size= 148736kB time=00:09:50.85 bitrate=2062.2kbits/s speed=30.3x frame=14501 fps=724 q=13.0 size= 152576kB time=00:10:05.95 bitrate=2062.7kbits/s speed=30.3x frame=14868 fps=724 q=15.0 size= 155648kB time=00:10:21.26 bitrate=2052.4kbits/s speed=30.3x frame=15233 fps=724 q=13.0 size= 159488kB time=00:10:36.48 bitrate=2052.7kbits/s speed=30.3x frame=15592 fps=724 q=13.0 size= 163072kB time=00:10:51.45 bitrate=2050.6kbits/s speed=30.3x frame=15958 fps=724 q=13.0 size= 166656kB time=00:11:06.72 bitrate=2047.7kbits/s speed=30.3x frame=16325 fps=724 q=13.0 size= 170240kB time=00:11:22.03 bitrate=2044.8kbits/s speed=30.3x frame=16688 fps=725 q=12.0 size= 173568kB time=00:11:37.17 bitrate=2039.5kbits/s speed=30.3x frame=17052 fps=725 q=13.0 size= 177152kB time=00:11:52.34 bitrate=2037.3kbits/s speed=30.3x frame=17417 fps=725 q=14.0 size= 180992kB time=00:12:07.58 bitrate=2037.8kbits/s speed=30.3x frame=17802 fps=726 q=15.0 size= 186368kB time=00:12:23.64 bitrate=2053.0kbits/s speed=30.3x frame=18167 fps=726 q=14.0 size= 191488kB time=00:12:38.85 bitrate=2067.2kbits/s speed=30.3x frame=18527 fps=726 q=14.0 size= 195584kB time=00:12:53.88 bitrate=2070.4kbits/s speed=30.3x frame=18898 fps=726 q=14.0 size= 199168kB time=00:13:09.33 bitrate=2067.0kbits/s speed=30.3x frame=19260 fps=726 q=14.0 size= 203008kB time=00:13:24.45 bitrate=2067.3kbits/s speed=30.3x frame=19628 fps=726 q=14.0 size= 207360kB time=00:13:39.79 bitrate=2072.1kbits/s speed=30.3x frame=19974 fps=725 q=15.0 size= 210176kB time=00:13:54.21 bitrate=2063.9kbits/s speed=30.3x frame=20359 fps=726 q=17.0 size= 215552kB time=00:14:10.27 bitrate=2076.7kbits/s speed=30.3x frame=20745 fps=727 q=17.0 size= 221440kB time=00:14:26.37 bitrate=2093.8kbits/s speed=30.4x frame=21248 fps=732 q=15.0 size= 224768kB time=00:14:47.35 bitrate=2075.0kbits/s speed=30.6x frame=21653 fps=733 q=14.0 size= 228608kB time=00:15:04.24 bitrate=2071.1kbits/s speed=30.6x frame=22023 fps=733 q=14.0 size= 232448kB time=00:15:19.68 bitrate=2070.5kbits/s speed=30.6x frame=22402 fps=733 q=13.0 size= 235520kB time=00:15:35.49 bitrate=2062.4kbits/s speed=30.6x frame=22774 fps=734 q=14.0 size= 239616kB time=00:15:51.00 bitrate=2064.1kbits/s speed=30.6x frame=23147 fps=734 q=15.0 size= 243968kB time=00:16:06.57 bitrate=2067.7kbits/s speed=30.6x frame=23556 fps=735 q=14.0 size= 248320kB time=00:16:23.61 bitrate=2068.1kbits/s speed=30.7x frame=23958 fps=736 q=14.0 size= 251648kB time=00:16:40.39 bitrate=2060.7kbits/s speed=30.7x frame=24356 fps=737 q=14.0 size= 254976kB time=00:16:57.00 bitrate=2053.8kbits/s speed=30.8x frame=24739 fps=737 q=14.0 size= 258304kB time=00:17:12.96 bitrate=2048.5kbits/s speed=30.8x frame=25128 fps=738 q=12.0 size= 263424kB time=00:17:29.18 bitrate=2056.8kbits/s speed=30.8x frame=25497 fps=738 q=12.0 size= 267264kB time=00:17:44.56 bitrate=2056.6kbits/s speed=30.8x frame=25921 fps=740 q=13.0 size= 270336kB time=00:18:02.25 bitrate=2046.3kbits/s speed=30.9x frame=26328 fps=741 q=14.0 size= 274432kB time=00:18:19.24 bitrate=2045.2kbits/s speed=30.9x frame=26705 fps=741 q=14.0 size= 279808kB time=00:18:34.96 bitrate=2055.8kbits/s speed=30.9x frame=27048 fps=740 q=13.0 size= 284160kB time=00:18:49.27 bitrate=2061.4kbits/s speed=30.9x frame=27441 fps=741 q=17.0 size= 289024kB time=00:19:05.66 bitrate=2066.6kbits/s speed=30.9x frame=27816 fps=741 q=15.0 size= 293632kB time=00:19:21.31 bitrate=2071.3kbits/s speed=30.9x frame=28198 fps=741 q=14.0 size= 297216kB time=00:19:37.22 bitrate=2068.2kbits/s speed=30.9x frame=28573 fps=741 q=15.0 size= 301312kB time=00:19:52.87 bitrate=2069.2kbits/s speed=30.9x frame=28950 fps=741 q=16.0 size= 305664kB time=00:20:08.59 bitrate=2071.8kbits/s speed=30.9x frame=29349 fps=742 q=16.0 size= 309760kB time=00:20:25.24 bitrate=2071.1kbits/s speed= 31x frame=29771 fps=743 q=16.0 size= 315136kB time=00:20:42.84 bitrate=2077.2kbits/s speed= 31x frame=30201 fps=745 q=13.0 size= 317696kB time=00:21:00.76 bitrate=2064.3kbits/s speed=31.1x frame=30586 fps=745 q=12.0 size= 320768kB time=00:21:16.82 bitrate=2058.0kbits/s speed=31.1x frame=30963 fps=745 q=11.0 size= 323840kB time=00:21:32.56 bitrate=2052.4kbits/s speed=31.1x frame=31364 fps=746 q=9.0 size= 326912kB time=00:21:49.27 bitrate=2045.5kbits/s speed=31.1x frame=31791 fps=747 q=14.0 size= 331264kB time=00:22:07.08 bitrate=2044.9kbits/s speed=31.2x frame=32167 fps=747 q=13.0 size= 335616kB time=00:22:22.77 bitrate=2047.5kbits/s speed=31.2x frame=32549 fps=747 q=10.0 size= 339456kB time=00:22:38.71 bitrate=2046.7kbits/s speed=31.2x frame=32946 fps=748 q=10.0 size= 342784kB time=00:22:55.27 bitrate=2041.8kbits/s speed=31.2x frame=33325 fps=748 q=13.0 size= 346880kB time=00:23:11.06 bitrate=2042.8kbits/s speed=31.2x frame=33698 fps=748 q=13.0 size= 351232kB time=00:23:26.64 bitrate=2045.5kbits/s speed=31.2x frame=34067 fps=748 q=14.0 size= 355840kB time=00:23:42.02 bitrate=2049.9kbits/s speed=31.2x frame=34417 fps=747 q=12.0 size= 359936kB time=00:23:56.61 bitrate=2052.5kbits/s speed=31.2x frame=34800 fps=747 q=12.0 size= 364288kB time=00:24:12.60 bitrate=2054.4kbits/s speed=31.2x frame=35189 fps=748 q=12.0 size= 367872kB time=00:24:28.82 bitrate=2051.7kbits/s speed=31.2x frame=35559 fps=748 q=8.0 size= 371968kB time=00:24:44.25 bitrate=2053.0kbits/s speed=31.2x frame=35949 fps=748 q=14.0 size= 375808kB time=00:25:00.50 bitrate=2051.7kbits/s speed=31.2x frame=36303 fps=747 q=14.0 size= 380672kB time=00:25:15.28 bitrate=2058.0kbits/s speed=31.2x frame=36650 fps=747 q=13.0 size= 385536kB time=00:25:29.76 bitrate=2064.6kbits/s speed=31.2x frame=37004 fps=746 q=14.0 size= 390144kB time=00:25:44.52 bitrate=2069.3kbits/s speed=31.2x frame=37364 fps=746 q=14.0 size= 393216kB time=00:25:59.52 bitrate=2065.5kbits/s speed=31.1x frame=37724 fps=746 q=14.0 size= 397312kB time=00:26:14.54 bitrate=2067.1kbits/s speed=31.1x frame=38096 fps=746 q=12.0 size= 401408kB time=00:26:30.07 bitrate=2068.0kbits/s speed=31.1x frame=38485 fps=746 q=12.0 size= 404736kB time=00:26:46.29 bitrate=2064.1kbits/s speed=31.1x frame=38951 fps=748 q=15.0 size= 409088kB time=00:27:05.71 bitrate=2061.4kbits/s speed=31.2x frame=39318 fps=748 q=13.0 size= 413440kB time=00:27:21.02 bitrate=2063.9kbits/s speed=31.2x frame=39691 fps=748 q=14.0 size= 416768kB time=00:27:36.57 bitrate=2061.0kbits/s speed=31.2x frame=40069 fps=748 q=12.0 size= 420864kB time=00:27:52.34 bitrate=2061.6kbits/s speed=31.2x frame=40469 fps=748 q=12.0 size= 423936kB time=00:28:09.04 bitrate=2056.1kbits/s speed=31.2x frame=40870 fps=749 q=12.0 size= 427008kB time=00:28:25.75 bitrate=2050.7kbits/s speed=31.3x frame=41259 fps=749 q=9.0 size= 431616kB time=00:28:41.97 bitrate=2053.3kbits/s speed=31.3x frame=41652 fps=749 q=11.0 size= 435200kB time=00:28:58.36 bitrate=2050.9kbits/s speed=31.3x frame=42053 fps=750 q=9.0 size= 438784kB time=00:29:15.09 bitrate=2048.0kbits/s speed=31.3x frame=42469 fps=751 q=11.0 size= 442112kB time=00:29:32.44 bitrate=2043.4kbits/s speed=31.3x frame=42862 fps=751 q=9.0 size= 445952kB time=00:29:48.84 bitrate=2042.2kbits/s speed=31.3x frame=43257 fps=751 q=11.0 size= 450304kB time=00:30:05.32 bitrate=2043.3kbits/s speed=31.4x frame=43653 fps=752 q=12.0 size= 453632kB time=00:30:21.84 bitrate=2039.8kbits/s speed=31.4x frame=44032 fps=752 q=11.0 size= 457984kB time=00:30:37.63 bitrate=2041.7kbits/s speed=31.4x frame=44394 fps=751 q=14.0 size= 462336kB time=00:30:52.75 bitrate=2044.2kbits/s speed=31.4x frame=44780 fps=752 q=13.0 size= 466688kB time=00:31:08.83 bitrate=2045.7kbits/s speed=31.4x frame=45178 fps=752 q=10.0 size= 470272kB time=00:31:25.44 bitrate=2043.3kbits/s speed=31.4x frame=45547 fps=752 q=15.0 size= 474880kB time=00:31:40.82 bitrate=2046.6kbits/s speed=31.4x frame=45925 fps=752 q=14.0 size= 480000kB time=00:31:56.59 bitrate=2051.6kbits/s speed=31.4x frame=46332 fps=752 q=10.0 size= 484096kB time=00:32:13.58 bitrate=2051.0kbits/s speed=31.4x frame=46747 fps=753 q=11.0 size= 488960kB time=00:32:30.88 bitrate=2053.2kbits/s speed=31.4x frame=47141 fps=753 q=11.0 size= 493056kB time=00:32:47.30 bitrate=2053.1kbits/s speed=31.4x frame=47536 fps=753 q=12.0 size= 497152kB time=00:33:03.79 bitrate=2053.0kbits/s speed=31.4x frame=47927 fps=754 q=12.0 size= 500992kB time=00:33:20.08 bitrate=2052.0kbits/s speed=31.5x frame=48319 fps=754 q=14.0 size= 504832kB time=00:33:36.45 bitrate=2050.9kbits/s speed=31.5x frame=48705 fps=754 q=11.0 size= 509696kB time=00:33:52.53 bitrate=2054.3kbits/s speed=31.5x frame=49078 fps=754 q=11.0 size= 513792kB time=00:34:08.11 bitrate=2055.1kbits/s speed=31.5x frame=49469 fps=754 q=14.0 size= 517120kB time=00:34:24.40 bitrate=2052.0kbits/s speed=31.5x frame=49837 fps=754 q=14.0 size= 523264kB time=00:34:39.76 bitrate=2061.1kbits/s speed=31.5x frame=50219 fps=754 q=14.0 size= 527872kB time=00:34:55.70 bitrate=2063.4kbits/s speed=31.5x frame=50622 fps=754 q=12.0 size= 531456kB time=00:35:12.50 bitrate=2060.9kbits/s speed=31.5x frame=51016 fps=755 q=15.0 size= 536320kB time=00:35:28.94 bitrate=2063.7kbits/s speed=31.5x frame=51401 fps=755 q=12.0 size= 540928kB time=00:35:45.00 bitrate=2065.9kbits/s speed=31.5x frame=51763 fps=755 q=14.0 size= 545280kB time=00:36:00.09 bitrate=2067.9kbits/s speed=31.5x frame=52128 fps=754 q=12.0 size= 549120kB time=00:36:15.31 bitrate=2067.9kbits/s speed=31.5x frame=52517 fps=755 q=14.0 size= 552704kB time=00:36:31.53 bitrate=2066.0kbits/s speed=31.5x frame=52892 fps=755 q=13.0 size= 556544kB time=00:36:47.18 bitrate=2065.6kbits/s speed=31.5x frame=53284 fps=755 q=12.0 size= 560128kB time=00:37:03.52 bitrate=2063.6kbits/s speed=31.5x frame=53724 fps=756 q=15.0 size= 563456kB time=00:37:21.88 bitrate=2058.9kbits/s speed=31.5x frame=54096 fps=756 q=12.0 size= 567808kB time=00:37:37.39 bitrate=2060.6kbits/s speed=31.5x frame=54487 fps=756 q=12.0 size= 571136kB time=00:37:53.71 bitrate=2057.8kbits/s speed=31.5x frame=54887 fps=756 q=12.0 size= 575232kB time=00:38:10.39 bitrate=2057.4kbits/s speed=31.5x frame=55283 fps=756 q=12.0 size= 578816kB time=00:38:26.90 bitrate=2055.4kbits/s speed=31.6x frame=55668 fps=756 q=15.0 size= 584960kB time=00:38:42.96 bitrate=2062.9kbits/s speed=31.6x frame=56029 fps=756 q=14.0 size= 589824kB time=00:38:58.00 bitrate=2066.6kbits/s speed=31.5x frame=56391 fps=756 q=14.0 size= 593408kB time=00:39:13.12 bitrate=2065.8kbits/s speed=31.5x frame=56756 fps=756 q=12.0 size= 596736kB time=00:39:28.36 bitrate=2064.1kbits/s speed=31.5x frame=57134 fps=756 q=14.0 size= 601088kB time=00:39:44.11 bitrate=2065.4kbits/s speed=31.5x frame=57489 fps=755 q=14.0 size= 605184kB time=00:39:58.92 bitrate=2066.6kbits/s speed=31.5x frame=57850 fps=755 q=14.0 size= 610304kB time=00:40:13.96 bitrate=2071.1kbits/s speed=31.5x frame=58210 fps=755 q=13.0 size= 613888kB time=00:40:28.99 bitrate=2070.4kbits/s speed=31.5x frame=58568 fps=755 q=14.0 size= 617472kB time=00:40:43.92 bitrate=2069.8kbits/s speed=31.5x frame=58927 fps=754 q=14.0 size= 621056kB time=00:40:58.89 bitrate=2069.1kbits/s speed=31.5x frame=59290 fps=754 q=15.0 size= 624896kB time=00:41:14.04 bitrate=2069.1kbits/s speed=31.5x frame=59746 fps=755 q=15.0 size= 631040kB time=00:41:33.04 bitrate=2073.6kbits/s speed=31.5x frame=60152 fps=756 q=16.0 size= 635648kB time=00:41:49.99 bitrate=2074.6kbits/s speed=31.5x frame=60524 fps=755 q=17.0 size= 639744kB time=00:42:05.49 bitrate=2075.1kbits/s speed=31.5x frame=60893 fps=755 q=16.0 size= 643584kB time=00:42:20.88 bitrate=2075.0kbits/s speed=31.5x frame=61260 fps=755 q=16.0 size= 647680kB time=00:42:36.19 bitrate=2075.7kbits/s speed=31.5x frame=61627 fps=755 q=17.0 size= 651776kB time=00:42:51.50 bitrate=2076.4kbits/s speed=31.5x frame=61994 fps=755 q=14.0 size= 655104kB time=00:43:06.81 bitrate=2074.6kbits/s speed=31.5x frame=62320 fps=754 q=17.0 size= 658944kB time=00:43:20.40 bitrate=2075.9kbits/s speed=31.5x frame=62632 fps=754 q=17.0 size= 665600kB time=00:43:33.40 bitrate=2086.4kbits/s speed=31.4x frame=62970 fps=753 q=17.0 size= 669440kB time=00:43:47.52 bitrate=2087.2kbits/s speed=31.4x frame=63383 fps=754 q=17.0 size= 673280kB time=00:44:04.75 bitrate=2085.5kbits/s speed=31.4x frame=63768 fps=754 q=17.0 size= 676096kB time=00:44:20.80 bitrate=2081.5kbits/s speed=31.4x frame=64169 fps=754 q=17.0 size= 679168kB time=00:44:37.51 bitrate=2078.0kbits/s speed=31.5x frame=64560 fps=754 q=14.0 size= 681216kB time=00:44:53.83 bitrate=2071.6kbits/s speed=31.5x frame=64927 fps=754 q=14.0 size= 684288kB time=00:45:09.14 bitrate=2069.2kbits/s speed=31.5x frame=65294 fps=754 q=14.0 size= 687872kB time=00:45:24.45 bitrate=2068.3kbits/s speed=31.5x frame=65678 fps=754 q=13.0 size= 690688kB time=00:45:40.46 bitrate=2064.7kbits/s speed=31.5x frame=66047 fps=754 q=13.0 size= 694016kB time=00:45:55.84 bitrate=2063.0kbits/s speed=31.5x frame=66430 fps=754 q=13.0 size= 696832kB time=00:46:11.83 bitrate=2059.4kbits/s speed=31.5x frame=66813 fps=754 q=12.0 size= 699904kB time=00:46:27.79 bitrate=2056.7kbits/s speed=31.5x frame=67243 fps=755 q=14.0 size= 704768kB time=00:46:45.74 bitrate=2057.7kbits/s speed=31.5x frame=67610 fps=754 q=15.0 size= 708608kB time=00:47:01.03 bitrate=2057.7kbits/s speed=31.5x frame=67971 fps=754 q=15.0 size= 714240kB time=00:47:16.10 bitrate=2063.1kbits/s speed=31.5x frame=68324 fps=754 q=14.0 size= 718336kB time=00:47:30.81 bitrate=2064.2kbits/s speed=31.5x frame=68687 fps=754 q=14.0 size= 723200kB time=00:47:45.96 bitrate=2067.2kbits/s speed=31.5x frame=69032 fps=753 q=14.0 size= 728320kB time=00:48:00.36 bitrate=2071.4kbits/s speed=31.4x frame=69371 fps=753 q=15.0 size= 731392kB time=00:48:14.49 bitrate=2070.0kbits/s speed=31.4x frame=69730 fps=753 q=15.0 size= 736000kB time=00:48:29.47 bitrate=2072.3kbits/s speed=31.4x frame=70119 fps=753 q=16.0 size= 740352kB time=00:48:45.69 bitrate=2073.0kbits/s speed=31.4x frame=70637 fps=754 q=14.0 size= 744704kB time=00:49:07.29 bitrate=2069.9kbits/s speed=31.5x frame=71212 fps=757 q=15.0 size= 749312kB time=00:49:31.27 bitrate=2065.9kbits/s speed=31.6x frame=71336 fps=757 q=8.0 Lsize= 751149kB time=00:49:35.30 bitrate=2068.2kbits/s speed=31.6x video:728056kB audio:21732kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.181519% RUNNER: Reject File if Larger than Original [Pass #1] Executing plugin runner... Please wait Plugin runner requested for a command to be executed by Unmanic COMMAND: cp -fv /library/unraid/TV Shows/Charlie's Angels/Season 4/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD.mkv /tmp/unmanic/unmanic_file_conversion-1652086167.4177125/Charlie's Angels - S04E25 - One Love.Two Angels (1) DVD-1652086167.4177053-WORKING-4.mkv LOG: '/library/unraid/TV Shows/Charlie'\''s Angels/Season 4/Charlie'\''s Angels - S04E25 - One Love.Two Angels (1) DVD.mkv' -> '/tmp/unmanic/unmanic_file_conversion-1652086167.4177125/Charlie'\''s Angels - S04E25 - One Love.Two Angels (1) DVD-1652086167.4177053-WORKING-4.mkv'
-
Hi @Josh.5, Having a small issue, I have had it running for a while now ploughing through my TV Shows. Just when I think it is about to finish it adds another 5k files to the queue. I have just checked and it seems to be adding files it has already done to the queue, to the point the results show the output is the same size and disregards the conversion. Not sure if it is not tagging the files properly or something but I would like to get this queue down to 0 at some point. Let me know if you need any specific information to find out why this is happening. I have not replaced the files with new ones for any reason so they should be marked as done and not done again. As per below, I searched the one file and it has shows up 26times. It seems to re-add every 7 days. It is wasting my resources doing this on a weekly basis so if you have any idea that would be great.
-
Hi Josh, I found what might be a bug, I have not had the issue since I made a change so assume that was the cause. Not sure if you had it reported before but see below: Issue: Plex scanner crashing the Plex docker container. Probable Cause: The notify Plex plugin seemed to trigger a full scan not a partial scan every time an encode finished. This was repeatedly restarted before it finished when encoding smaller quick files. Logs attached and errors below: "** PLEX MEDIA SCANNER CRASHED, CRASH REPORT WRITTEN: /config/Library/Application Support/Plex Media Server/Crash Reports/1.25.6.5577-c8bd13540/PLEX MEDIA SCANNER/45c7ca2a-b863-460b-df55088e-f081c704.dmp" "Mar 17 21:00:32 UNRaid kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=1bb442ead7812e3fe2ee61298cab3c87a2b79cc4d7e53172ad1ee70316e11570,mems_allowed=0,global_oom,task_memcg=/docker/a71aed1dabcf0b2636dd240230642b61783f926a6bfab1d5e90878528e6222ab,task=PMS RunServer,pid=22731,uid=99 Mar 17 21:00:32 UNRaid kernel: Out of memory: Killed process 22731 (PMS RunServer) total-vm:12198664kB, anon-rss:7465440kB, file-rss:0kB, shmem-rss:7952kB, UID:99 pgtables:15184kB oom_score_adj:0 Mar 17 21:00:33 UNRaid kernel: oom_reaper: reaped process 22731 (PMS RunServer), now anon-rss:0kB, file-rss:0kB, shmem-rss:4kB" I have since removed the notify Plex plugin from my workflow and have not had the issue since. unraid-diagnostics-20220317-2101.zip
-
Been having an issue the since a couple updates ago. First I did not dig too deep and was just noticing in the Plex logs that the scanner kept crashing. It would happen every few days. I assumed it would be fixed in the next update and wait it out. But it has done it twice in a hour now. So I dug a little deeper and saw this in my UnRaid logs No idea what this means, a friend said a process is using too much memory and the kernal killed it. It could be related to the scanner getting stuck or going in a loop. I grabbed my diagnostics as well so see attached. Can anyone confirm what this is and hwo I can fix this? I have never had an issue before so not sure why it is suddenly deciding to apparently use too much memory and get killed in this manner. Thanks in advance. unraid-diagnostics-20220317-2101.zip
-
Ignore me... For some reason everything has to be specific for the login to even work. Once I ticked SSL in the mail server settings it let me login to the webmail.
-
Giving this a try. Set up a mail server and set credentials for it but when I try and login to the webmail front end it just constantly says email or password is incorrect. I then tried to set up a user as it had not made this automatically and still have the same issue.
-
Addition: To clarify, the steam server browser has to have the server added manually to favourites. Still no server shows in the LAN tab there either.
-
Ok, I am getting somewhere.... Steam shows the server but not on port 2015. If I add 2016 it will show the server. So, I am assuming it is not finding it via the in-game settings as 2015 is the primary query port? So..... Looking at the server_config.cfg there is a section on the ports: If I change the query port to 2015 and restart the server the steam server browser finds it on 2015... BUT the game LAN servers will still not show the game. My next step is to port forward the steam ports 2015-2016 to my server as adding the external IP on 2016 or 2015 will show as not responding on the steam server browser. If I can get that to work at least I have a workaround. But not sure why the in game browser still can't see it. I have noticed though, looking at the logs (Right click docker -> Logs) it looks like it sometimes does not connect to steam it just says server started. Then at other times you can see server started and then it says connected to steam... ok Maybe this is an intermittent steam connection issue? Either way, I am going to port forward the query ports and then try an external connection via steam server browser. Will keep you updated.


-
Same network, the server runs Plex and everything else so is pretty solid in that respect. As for Wrekfest it's self, I have played it multiple times and for the past 6-8weeks have been playing it with friends Sunday evenings and I have hosted the server from my laptop. So in that respect I know the game works on the laptop and the ports are all correct (I changed the rules to the server IP from my laptop IP) So I have no idea what could be wrong. Is there any more indepth logs or something I can do to try and narrow it down a bit? Annoyingly Wrekfest has no "Direct connect" for me to try and force a connection to see if it actually works at all.
-
Right, deleted docker, went to CA Cleanup Appdata and deleted the Wrekfest folders. manually checked the folders were deleted. Grabbed a fresh docker, no settings changed at all just grabbed it as it is. Checked log and waited for it to finish downloading. Webgui says it is connected to steam. Logs says server is started. Still nothing. Banging my head a little so going to go to bed and try another fresh install tomorrow. The server config file has no section about LAN IP so that has not been changed.

-
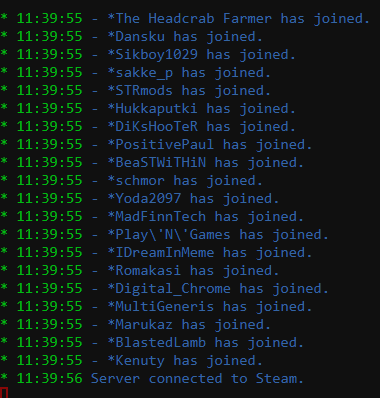
Amazing that you have Wreckfest added! I previously ran this internally when we wanted to play so I would just load the game up and start a server. Because of this I already had all the ports forwarded. All I have done is go through my rules and updated the IP to the Unraid server. I downloaded the Wrekfest docker and set up the server config. I have all the ports I previously had forwarded plus the ones the docker settings specify. Yet I am unable to find the server when I load up on my laptop and browse LAN servers. I can see the server is running as the logs say so and the webgui shows AI have joined: The webgui also shows this though: Repeated about 10 times, before it shows the AI joined. Now, being a little on the stupid side can someone clarify something. My server is on port 192.0168.0.37 but the container shows another IP on the port mappings. All my forwarding rule still point to the server, the server should move all that traffic to the 172 IP correct? Other than that I am at a loss as to what is wrong with the setup. Surely even without all the port forwarding I should be able to at least see the server on LAN servers right?