




plantsandbinary
Members
-
Joined
Everything posted by plantsandbinary
-
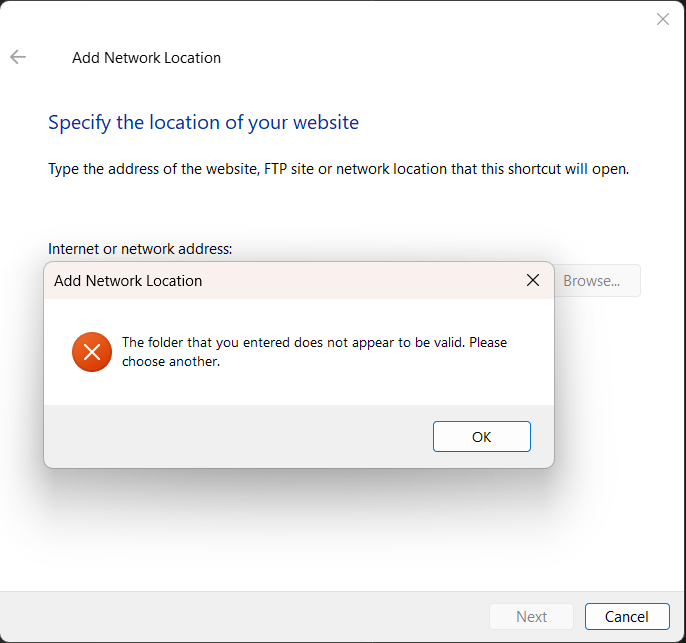
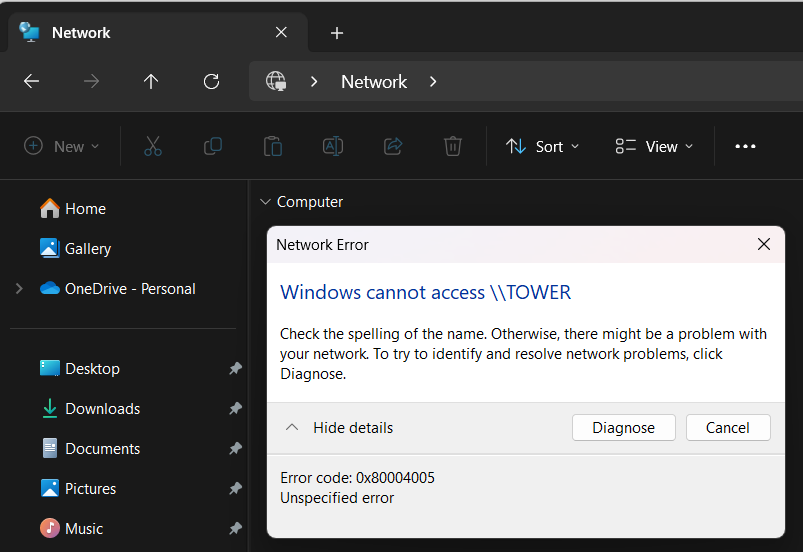
I cannot for the life of me get this to work with my samba shares on Unraid... It USED to work, but it hasn't worked at all for quite a few versions. Here is my setup: 1. Installed Tailscale on my Unraid with this docker container (also set available as an exit node) 2. Installed Tailscale on my Laptop 3. Set up a DNS via Talscale blah-blah.ts.net 4. Connected both machines via Tailscale 5. On my laptop I've tried //TOWER/storage (cannot find) and mapping a network drive. eg. //tailscale_ip/share1, http://tailscale_dns/share1 and basically every single combination. It was some many months ago I could simply go into my Network Locations in Windows and just type //TOWER and all my shares would show up. Now after an update of Tailscale or Unraid etc. this no longer happens. I could also map the network drives with simply: //tailscale_dns/share1 Nothing like this works anymore. It seems to try and connect because there's a lag whilst it attempts a connection but I just keep getting errors from Windows like: It never even asks me for my share username and password. Please someone, some help? Doesn't matter if I set to use an exit node or not. What could I be missing? This seriously should be as simple as installing Tailscale on both devices, turning it on and then adding the share... That's meant to be the point of Tailscale. EDIT: Could this be the issue? Something wrong with Unraid itself that changed during an update? to work flawlessly. Just install on both machines and don't even need to set any extra settings. I could mount things no problem. After a few updates of Tailscale and Unraid it just stopped working. As I said, this used
-
speedtest-tracker container is STILL broken. It's been more than 8 months and you still have more than 50% chance when you go to use it, it just says 500 SERVER ERROR
-
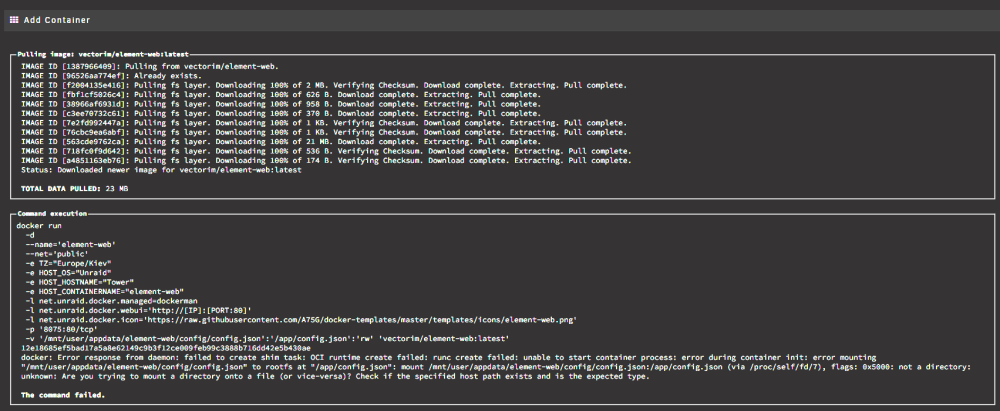
Is the element container broken? I get this error whenever I try and install it. It worked many months ago but not now. EDIT: Nvm, I was missing the initial steps to pull the config.json in the description. No idea why they cannot just be added as a step in the docker container...
-
So I've also just found that not only did my qBittorrent container get completely destroyed after the last update. It's also removed my ability to download, upload and my original username and password. Looks like I'm going to have to do a full reinstall of it. FFS. I wish there was a way to see this in a changelog or something BEFORE I update the container. I'm going to turn off future updates for this container...
-
I forgot to say that for some reason I don't even seem to have the [Locking] part in the config file, so I have no idea what is going on here. Technically it should have no problem logging me in without it. EDIT: I have no idea why or how but it seems to have defaulted back to: admin adminadmin I logged in and changed it again via the UI... super weird. EDIT AGAIN: I guess this is what the guys above me are talking about. I suppose some update has nuked my config for some reason... pretty stupid.
-
qBittorrent has for some reason started complaining about my password after I updated Unraid to 6.12.3 I didn't have this problem before at all. I haven't changed my username and password either or even touched any of the appdata stuff. Any ideas how I can fix this and get back into the container? I can't see anything that is happening in there.
-
I'm using your hexo-blog container and it is amazing so far. Otherwise flawless. However I have noticed 2 things in the logs: 1. It is not possible to install any plugins which have a dash in the name (which is literally all of them) Installing additional plugins "hexo-cli, hexo-generator-searchdb, hexo-all-minifier, " npm ERR! code EINVALIDTAGNAME npm ERR! Invalid tag name "hexo-cli," of package "hexo-cli,": Tags may not have any characters that encodeURIComponent encodes. EDIT: Nevermind it's because I was mistakenly separating the plugin names with a comma and not a space as it was instructed. 2. npm is pretty outdated and likely should be regularly updated, as it is much more unlikely to break things during an update, than if it stays outdated. npm corruption is a pretty common thing with older versions. I have even myself had to troubleshoot this exact issue many times. npm notice npm notice New major version of npm available! 8.19.3 -> 9.8.0 npm notice Changelog: <https://github.com/npm/cli/releases/tag/v9.8.0> npm notice Run `npm install -g [email protected]` to update! npm notice
-
I'm hosting a blog using "hexo" container on port eg. 8820 It takes static .md files and hosts them at my blog domain at myblog.tld. To easily write those files I'd like to use another container "vscodium" to write the .md files. I've given vscodium a mount point: /blog Which is the unraid /user/appdata/hexoblog-data/source/pages/ DIR However in vscodium I don't have write permissions. Even though I marked the mount point in Unraid as Read/Write. vscodium says I don't have permission to write or edit files. What's the best way to fix this without risking damaging linux permissions? Thanks
-
Man I take issue with so many of your comments but whatever. Different strokes for different folks. What I will say though is that every single motherboard manufacturer, especially Asus and Gigabyte have totally collapsed in quality in the last 3-4 years. Asus is the #1 scumbag manufacturer now in practically every respect. Gigabyte has dropped right off a cliff and competes with Asus now in bad policies and QA. I would say they aren't distinguishable in this regard. Unlike you I've only ever had issues with Gigabyte and always found them to charge another $100 for the exact same features as any other brand, just because "it's Gigabyte". The only thing I'll give them points for, are their amazing aftermarket GPUs and long warranty policies and amazing cooling on those. In the MB department though, nope. ASRock on the other hand have consistently shipped quality over and over. They're the most slept on company in the business. ASRock has competed brutally and unfailingly to try and stand up to the other companies. They've done this by having extremely good support, warranty policies and most importantly, unfailing hardware. Their motherboards are absolutely world class and come with so many extra features that most people can't live without when they get used to them. Where Asus tries to push garbage on you like their atrocious "Armoy Crate" and then totally ignores you on their support forum when you're getting constant crashes because of it, and Gigabyte and MSI bundle their motherboards with garbage middle/bloatware. ASRock focuses on stability. They've consistently been one of the first manufacturers to fully support new CPU architectures and release consistent BIOS updates even for extremely old hardware. Furthermore, they are specifically also focusing on niché users, in eg. making the ONLY mATX X570 board on the market. For people looking at smaller builds, this is HUGE. At the risk of sounding like a sales pitch, I HIGHLY encourage you to drop whatever predisposition you have toward them. As for Intel. I'd boycott Israel literally anywhere I can, for personal reasons. That's before we even talk about their terrible track record for exploits and security holes. Which is again even before we talk about their totally delusional pricing and insanely high temps compared to AMD. I mean sure if you know you absolutely need 24 cores or something, by all means pay the insane asking price for Intel. If you want far better power efficiency and much better price:performance ratio. AMD is the choice, no question. As I said, you can get a monster of an AMD chip for only fifty bucks which will crush that Intel chip of yours. On top of that, AMD boards have for a long time been far more stable, cheaper overall and generally come with better features. AMD boards were the first with 2.5G Ethernet, to not share lanes with CPU etc. But sure, I guess none of this matters if you are building an ultra-budget IDGAF-build. Lmfao. I am stealing this quote. Anyway enjoy your build dude. When you want better and more reliable components, refer to the first post I made.
-
There is absolutely something wrong with this docker image. This happens roughly after 24 hours. I've rebuilt the container a few times and always the database becomes read-only. I can't add anything to the whitelist or blacklist afterward. Rebooting it solves the problem but this still always happens eventually. I've since shut this down and started using AdGuard DNS directly on my router with DNS-over-TLS. The performance is much better and I am not fighting with this container every 5 seconds. It's also overall far more reliable.

-
How is it working? Is it giving you a 500 Network Error every few days or something? I am using the same one and getting this 500 Network Error after a day or two. A simple reboot fixes it but there's no error or anything else in the log why it stops working...
-
Which version did you switch to?
-
Personally I would never build with intel ever. That CPU has a pretty high TDP. Obviously it won't always be running at max power but if you care about your power bill, you might want to look at AMD. I also wouldn't buy scumbag ASUS after their last BS. The ASRock X570M Pro4 is a super cheap, beast of a board in a micro form-factor. It's absolutely rock solid and will last you at least 5 years. The Ryzen 3600 can be got for $50 and is a beast of a chip. It still has 6 cores and 12 threads. If you want something a bit newer and faster then there's the Ryzen 5600 for about $100-110. Both of which are between 33%-60% better than the Intel you listed and half to 33% less expensive, in addition to being a LOT newer. If you can't find/don't want that board I think there's an X460 and B650 version of it too which are close to the same thing. I wouldn't use a CPU released in 2011 and discontinued in 2013 even for security reasons dude.
-
A big thanks to the people behind Unraid. It's absolutely one of the best purchases I've ever made. Even though a kernel issue in an older version killed 2 years of my files, it was my own fault for not having a proper backup. The new update is great. Small improvements but all of them in the right direction. I'm really happy to have bought something that gets better every version and not worse or more bloated and crippled by feature creep. It's really nice to more clearly see what is protected by my array and how much memory/resources different services are using on my machine. Thanks again!
-
I recently installed a new M2 SSD for cache and it's generally running what would be considered "hot" at about 41-47C. The issue is that I'm now getting "Array Health [FAIL]" and the only issue I can find in the notification log is that the cache disk is hot... Is that really what's causing the failure message?
-
It seems that after a time for some reason using the current container: ghcr.io/alexjustesen/speedtest-tracker:latest I am getting 500 internal server errors. After a few days. I had removed the internal port mapping because I was using Cloudflare tunnel. So I didn't need any port mapping but it might be that this somehow breaks the container (as I just deleted the mappings from docker-compose). In any case. I reinstalled the container and kept the port mapping. Let's see if it works now. So far though, without that issue this version of the container works fine and it was last updated 16 days ago. I don't think anyone should be using any other version of this.
-
Has anyone else experienced the scenario where for some reason the database becomes 'read-only' after a few days of running non-stop and all gravity updates or individual additions to the whitelist fail?
-
Thanks I came here to ask this and I am following the exact same video lmao trying to get Authelia to work with Cloudfare Tunnels.
-
Any tip on how to use this with Cloudfare Tunnel? Both the tunnel and the docker container are running on the same network. I keep getting this error in the Cloudfare Tunnel log: 2023-06-18T12:37:55Z ERR Request failed error="Unable to reach the origin service. The service may be down or it may not be responding to traffic from cloudflared: dial tcp xxx.18.0.xx:80: connect: connection refused" connIndex=3 dest=https://qbt.xtu.icu/favicon.ico event=0 ip=198.41.200.43 type=http Heimdall docker works fine with the following (it's the first one): EDIT: Fixed my problem 30 seconds after making this post by adding: :8080 at the end of my service URL in Cloudflare.

-
Can I please get some help in using LuckyBackup container to sync my files to Google Drive? I'm trying to set up a "remote" destination but nothing seems to be working and LuckyBackup is just hanging... I've tried following this too but this is for using SSH with another machine: https://www.spxlabs.com/blog/2022/1/3/backup-unraid-with-luckybackup I'm trying to use Google Drive as the destination.
-
Actually it seems to kill itself any time it does an HTTP challenge: [app ] Duplicate relation "access_list" in a relation expression. You should use "a.[b, c]" instead of "[a.b, a.c]". This will cause an error in objection 2.0 [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf" [app ] } [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf" [app ] } [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf.err [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf.err" [app ] } [app ] [6/1/2023] [11:22:03 PM] [Nginx ] › ℹ info Reloading Nginx [app ] [6/1/2023] [11:24:14 PM] [SSL ] › ℹ info Testing http challenge for xtu.icu [app ] Uncaught SyntaxError: Unexpected end of JSON input [app ] FROM [supervisor ] service 'app' exited (got signal SIGILL). [supervisor ] service 'app' exited, shutting down... [supervisor ] stopping service 'nginx'... [supervisor ] service 'nginx' exited (with status 0). [finish ] executing container finish scripts... [finish ] all container finish scripts executed. ** Press ANY KEY to close this window **
-
I just tried to generate a wildcard cert using Cloudfare API token DNS challenge and the app spontaneously killed itself completely whilst doing it: [cert_cleanup] ---------------------------------------------------------- [cert_cleanup] Let's Encrypt certificates cleanup - 2023/06/01 23:16:59 [cert_cleanup] ---------------------------------------------------------- [cert_cleanup] 0 file(s) kept. [cert_cleanup] 0 file(s) deleted. [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info Current database version: none [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] auth Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] user Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] user_permission Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] proxy_host Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] redirection_host Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] dead_host Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] stream Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] access_list Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] certificate Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] access_list_auth Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [initial-schema] audit_log Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [websockets] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [websockets] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [forward_host] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [forward_host] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [http2_support] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [http2_support] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [http2_support] redirection_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [http2_support] dead_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [forward_scheme] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [forward_scheme] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [disabled] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [disabled] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [disabled] redirection_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [disabled] dead_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [disabled] stream Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [custom_locations] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [custom_locations] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [hsts] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [hsts] proxy_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [hsts] redirection_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [hsts] dead_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [settings] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [settings] setting Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [access_list_client] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [access_list_client] access_list_client Table created [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [access_list_client] access_list Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [access_list_client_fix] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [access_list_client_fix] access_list Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [pass_auth] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [pass_auth] access_list Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [redirection_scheme] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [redirection_scheme] redirection_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [redirection_status_code] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [redirection_status_code] redirection_host Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [stream_domain] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [stream_domain] stream Table altered [app ] [6/1/2023] [11:16:59 PM] [Migrate ] › ℹ info [stream_domain] Migrating Up... [app ] [6/1/2023] [11:16:59 PM] [Setup ] › ℹ info Creating a new JWT key pair... [supervisor ] all services started. [app ] [6/1/2023] [11:17:01 PM] [Setup ] › ℹ info Wrote JWT key pair to config file: /opt/nginx-proxy-manager/config/production.json [app ] [6/1/2023] [11:17:01 PM] [Setup ] › ℹ info Creating a new user: [email protected] with password: changeme [app ] [6/1/2023] [11:17:02 PM] [Setup ] › ℹ info Initial admin setup completed [app ] [6/1/2023] [11:17:02 PM] [Setup ] › ℹ info Default settings added [app ] [6/1/2023] [11:17:02 PM] [Setup ] › ℹ info Logrotate Timer initialized [app ] [6/1/2023] [11:17:02 PM] [Setup ] › ℹ info Logrotate completed. [app ] [6/1/2023] [11:17:02 PM] [IP Ranges] › ℹ info Fetching IP Ranges from online services... [app ] [6/1/2023] [11:17:02 PM] [IP Ranges] › ℹ info Fetching https://ip-ranges.amazonaws.com/ip-ranges.json [app ] [6/1/2023] [11:17:02 PM] [IP Ranges] › ℹ info Fetching https://www.cloudflare.com/ips-v4 [app ] [6/1/2023] [11:17:02 PM] [IP Ranges] › ℹ info Fetching https://www.cloudflare.com/ips-v6 [app ] [6/1/2023] [11:17:02 PM] [SSL ] › ℹ info Let's Encrypt Renewal Timer initialized [app ] [6/1/2023] [11:17:02 PM] [SSL ] › ℹ info Renewing SSL certs close to expiry... [app ] [6/1/2023] [11:17:02 PM] [IP Ranges] › ℹ info IP Ranges Renewal Timer initialized [app ] [6/1/2023] [11:17:02 PM] [Global ] › ℹ info Backend PID 417 listening on port 3000 ... [app ] [6/1/2023] [11:17:02 PM] [Nginx ] › ℹ info Reloading Nginx [app ] [6/1/2023] [11:17:02 PM] [SSL ] › ℹ info Renew Complete [app ] [6/1/2023] [11:18:01 PM] [SSL ] › ℹ info Testing http challenge for *.xtu.icu [app ] Uncaught SyntaxError: Unexpected end of JSON input [app ] FROM [supervisor ] service 'app' exited (got signal SIGILL). [supervisor ] service 'app' exited, shutting down... [supervisor ] stopping service 'nginx'... [supervisor ] service 'nginx' exited (with status 0). [finish ] executing container finish scripts... [finish ] all container finish scripts executed. ** Press ANY KEY to close this window ** Obviously this is not supposed to happen...
-
I also just tried bypassing using Cloudfare's free SSL, and I tried to make a wildcard via NPM. Instead I now got this error: Error: Command failed: certbot certonly --config "/etc/letsencrypt.ini" --cert-name "npm-6" --agree-tos --email "[email protected]" --domains "*.xtu.icu" --authenticator dns-cloudflare --dns-cloudflare-credentials "/etc/letsencrypt/credentials/credentials-6" usage: certbot [SUBCOMMAND] [options] [-d DOMAIN] [-d DOMAIN] ... Certbot can obtain and install HTTPS/TLS/SSL certificates. By default, it will attempt to use a webserver both for obtaining and installing the certificate. certbot: error: unrecognized arguments: --dns-cloudflare-credentials /etc/letsencrypt/credentials/credentials-6 at ChildProcess.exithandler (node:child_process:402:12) at ChildProcess.emit (node:events:513:28) at maybeClose (node:internal/child_process:1100:16) at Process.ChildProcess._handle.onexit (node:internal/child_process:304:5) Looks like it's running the wrong command. So it seems like this container isn't configured properly.
-
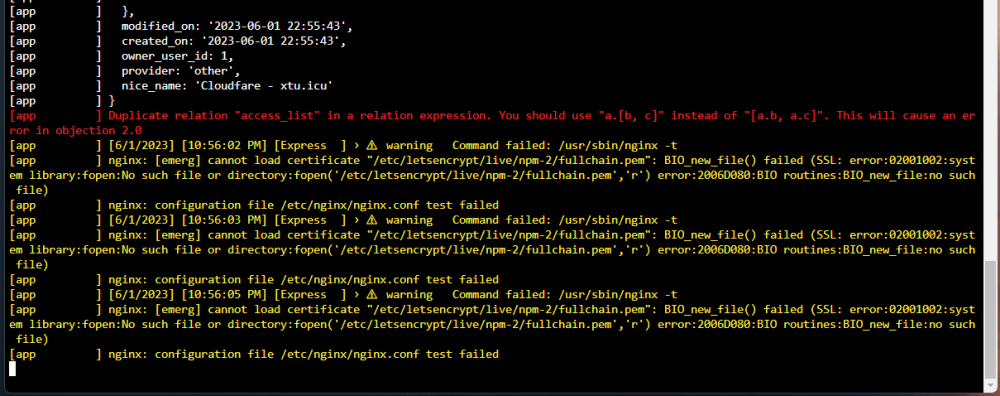
Now onto the real issue. The one which is completely breaking my NginxProxyManager container. Remember this is a fresh installation. I am trying to add this custom cert to NPM. I've done that successfully. You can see here in the logs: [app ] [6/1/2023] [10:55:43 PM] [SSL ] › ℹ info Writing Custom Certificate: { [app ] id: 3, [app ] expires_on: '2038-04-01 15:40:00', [app ] domain_names: [ '"CloudFlare,' ], [app ] meta: { [app ] certificate: '-----BEGIN CERTIFICATE-----\r\n' + [app ] blah blah blah [app ] '-----END CERTIFICATE-----', [app ] certificate_key: '-----BEGIN RSA PRIVATE KEY-----\r\n' + [app ] blah blah blah [app ] '-----END RSA PRIVATE KEY-----' [app ] }, [app ] modified_on: '2023-06-01 22:55:43', [app ] created_on: '2023-06-01 22:55:43', [app ] owner_user_id: 1, [app ] provider: 'other', [app ] nice_name: 'Cloudfare - xtu.icu' [app ] } [app ] Duplicate relation "access_list" in a relation expression. You should use "a.[b, c]" instead of "[a.b, a.c]". This will cause an error in objection 2.0 [app ] [6/1/2023] [10:56:02 PM] [Express ] › ⚠ warning Command failed: /usr/sbin/nginx -t [app ] nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/npm-2/fullchain.pem": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/etc/letsencrypt/live/npm-2/fullchain.pem','r') error:2006D080:BIO routines:BIO_new_file:no such file) [app ] nginx: configuration file /etc/nginx/nginx.conf test failed [app ] [6/1/2023] [10:56:03 PM] [Express ] › ⚠ warning Command failed: /usr/sbin/nginx -t [app ] nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/npm-2/fullchain.pem": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/etc/letsencrypt/live/npm-2/fullchain.pem','r') error:2006D080:BIO routines:BIO_new_file:no such file) [app ] nginx: configuration file /etc/nginx/nginx.conf test failed [app ] [6/1/2023] [10:56:05 PM] [Express ] › ⚠ warning Command failed: /usr/sbin/nginx -t [app ] nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/npm-2/fullchain.pem": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/etc/letsencrypt/live/npm-2/fullchain.pem','r') error:2006D080:BIO routines:BIO_new_file:no such file) [app ] nginx: configuration file /etc/nginx/nginx.conf test failed You can see the errors here in color: This causes my entire container to crash continuously. This happens specifically when I go to a site on my list in NPM and select to use the custom cert I just added. I instead get those errors and this in the GUI: (excuse the blown out HDR screenshot) I have no idea what is causing this at all... Container is using just the normal settings... it seems the problem is that the certs are not being written to: "/etc/letsencrypt/live/npm-2/fullchain.pem" but I have no idea why... that's just my normal \\TOWER\appdata\NginxProxyManager-CrowdSec\letsencrypt folder... except for some reason it's completely empty??? This problem will allow me to start the container but it won't do anything and will just spam the logs with the errors in yellow.
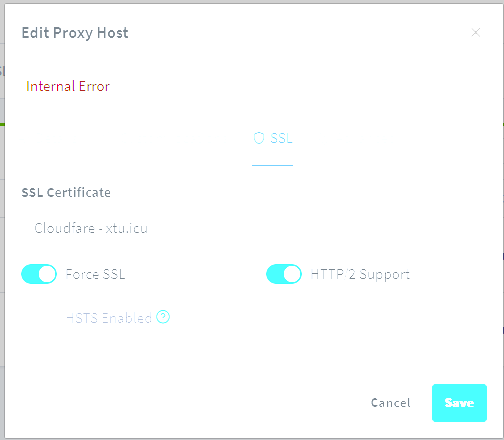
-
I just installed Nginx-Proxy-Manager-Crowdsec and I am getting this in the logs when adding/removing SSL certs: [cert_cleanup] ---------------------------------------------------------- [cert_cleanup] Let's Encrypt certificates cleanup - 2023/06/01 22:44:04 [cert_cleanup] ---------------------------------------------------------- [cert_cleanup] 0 file(s) kept. [cert_cleanup] 0 file(s) deleted. [app ] [6/1/2023] [10:44:04 PM] [Migrate ] › ℹ info Current database version: none [app ] [6/1/2023] [10:44:04 PM] [Setup ] › ℹ info Logrotate Timer initialized [app ] [6/1/2023] [10:44:04 PM] [Setup ] › ℹ info Logrotate completed. [app ] [6/1/2023] [10:44:04 PM] [IP Ranges] › ℹ info Fetching IP Ranges from online services... [app ] [6/1/2023] [10:44:04 PM] [IP Ranges] › ℹ info Fetching https://ip-ranges.amazonaws.com/ip-ranges.json [app ] [6/1/2023] [10:44:04 PM] [IP Ranges] › ℹ info Fetching https://www.cloudflare.com/ips-v4 [app ] [6/1/2023] [10:44:04 PM] [IP Ranges] › ℹ info Fetching https://www.cloudflare.com/ips-v6 [app ] [6/1/2023] [10:44:04 PM] [SSL ] › ℹ info Let's Encrypt Renewal Timer initialized [app ] [6/1/2023] [10:44:04 PM] [SSL ] › ℹ info Renewing SSL certs close to expiry... [app ] [6/1/2023] [10:44:04 PM] [IP Ranges] › ℹ info IP Ranges Renewal Timer initialized [app ] [6/1/2023] [10:44:04 PM] [Global ] › ℹ info Backend PID 451 listening on port 3000 ... [supervisor ] all services started. [app ] [6/1/2023] [10:44:05 PM] [Nginx ] › ℹ info Reloading Nginx [app ] [6/1/2023] [10:44:05 PM] [SSL ] › ℹ info Renew Complete [app ] Duplicate relation "access_list" in a relation expression. You should use "a.[b, c]" instead of "[a.b, a.c]". This will cause an error in objection 2.0 [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf" [app ] } [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf" [app ] } [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Deleting file: /data/nginx/proxy_host/1.conf.err [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ⬤ debug Could not delete file: { [app ] "errno": -2, [app ] "syscall": "unlink", [app ] "code": "ENOENT", [app ] "path": "/data/nginx/proxy_host/1.conf.err" [app ] } [app ] [6/1/2023] [10:44:49 PM] [Nginx ] › ℹ info Reloading Nginx I'm having numerous issues with this container. The above logs pertain to me using my own cert given to me by Cloudfare. I am not sure if it's a problem getting an error that it cannot delete those files.









