





Fiservedpi
Members
-
Joined
-
Last visited
Everything posted by Fiservedpi
-
So I got the container pulled down but, having trouble linking it to Sonarr my Sonarr IP and Server IP are the same if that makes any difference I think i got it i was using the wrong bot token but still need help with Sonarr EDIT:: I JUST CHANGED MY SONARR IP and it worked
-
The dev should be fixing soon, they answered on git
-
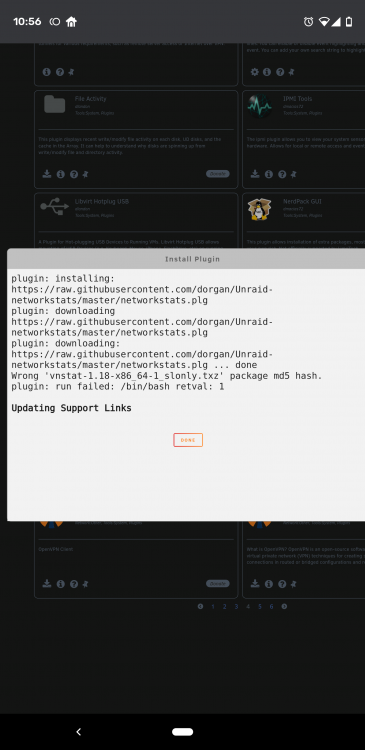
Md5 hash issue is back https://github.com/dorgan/Unraid-networkstats/issues/12
-
Thank you,
-
After installing the container and trying to stop the array I'm now greeted with the server unable to spin down disk 1 anyone know how I can resolve this `````Oct 28 18:19:20 Tower root: umount: /mnt/disk1: target is busy. Oct 28 18:19:20 Tower emhttpd: shcmd (683): exit status: 32 Oct 28 18:19:20 Tower emhttpd: Retry unmounting disk share(s)... Oct 28 18:19:25 Tower emhttpd: Unmounting disks... Oct 28 18:19:25 Tower emhttpd: shcmd (684): umount /mnt/disk1 Oct 28 18:19:25 Tower root: umount: /mnt/disk1: target is busy. Oct 28 18:19:25 Tower emhttpd: shcmd (684): exit status: 32 Oct 28 18:19:25 Tower emhttpd: Retry unmounting disk share```
-
so i've got the plugin up and running WITHIN my network but it doesn't work outside my network i've forwarded the correct port but am lost on how to have this set so i can connect when I'm not on my network
-
thank u @Squid
-
All of a sudden the plug-in is not actually updating the Dockers all my settings are the same but I have to hit the apply update button manually
-
have you made the iso share view able within the vm on mine i have a shared documents folder that syncs between the vm and shares
-
at the end of the docker name you just have to :tag [plex/arm86] .... something along those lines Edit the container and change the :latest tag to the new tag you want, you get the tags from the dockerhub page https://hub.docker.com/r/linuxserver/plex/
-
Is there anything to be concerned about here? Anything I should do SHA256 hash key mismatch (updated), /mnt/disk2/domains/Ubuntu/vdisk1.img was modified SHA256 hash key mismatch (updated), /mnt/disk2/domains/UnR-Win-10/vdisk1.img was modified SHA256 hash key mismatch (updated), /mnt/disk1/back_ups/libvert_back_up/libvirt.img was modified SHA256 hash key mismatch (updated), /mnt/disk1/system/docker/docker.img was modified SHA256 hash key mismatch (updated), /mnt/disk1/system/libvirt/libvirt.img was modified SHA256 hash key mismatch (updated), /mnt/disk1/system/libvirt/libvirt.img was modified
-
having trouble adding my server in my network my server lives at the jrwehuiry893789yuiehy.unraid.net on port 80 when setting up the app do i use the original ip of server? or the unraid SSL one
-
Great job @digiblur
-
Had anyone created a script to email after reboot they could share
-
is there any way to password protect the docker ui? found it http://nodered.org/docs/security.html


