mgutt
Moderators
-
Joined
-
Last visited
Everything posted by mgutt
-
Consider this modification:
-
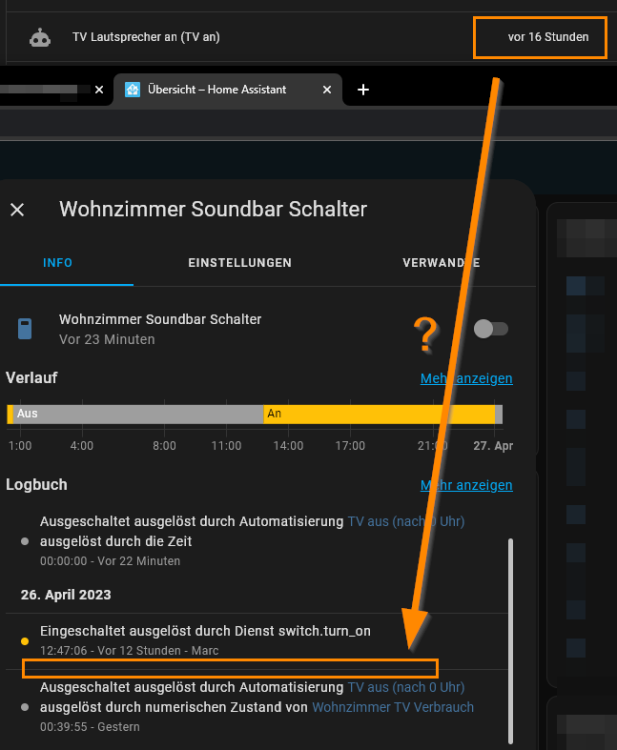
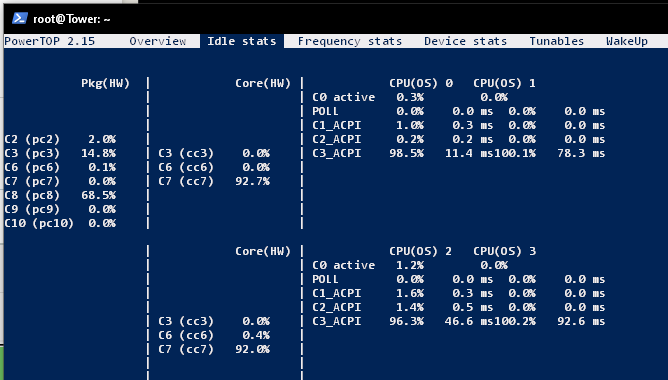
Der Verbrauch schwankt zwischen 9,6 und 12,5W mit 2 NVME in beiden M.2 Slots und 5 SSDs (2 SSDs am Mainboard angeschlossen, 3 SSDs an der ASM1166 Karte): Die C-States schwanken manchmal zwischen C6 und C8, aber C8 sieht man am häufigsten: Auch wenn der Verbrauch gut ist, finde ich es nach wie vor komisch, dass man den PCIe Slot 1 von der CPU nicht benutzen "darf" und er dann direkt auf C2 zurückfällt. Ich mach dazu auch mal eine Support-Anfrage bei Gigabyte auf.
-
Der Bug ist übrigens in Unraid 6.12 gelöst.
-
Nein. Die Disks haben untereinander keinen Einfluss. Man kann alle Dateisysteme wild mischen. A) Backups machen B) ist das nicht schwer. Docker+VM auf Nein stellen, alle Shares Richtung Array stellen und Mover starten.
-
Korrekt. Korrekt ZFS ist in Unraid nicht komplizierter als BTRFS. Man gibt ja nichts auf der Konsole ein oder sowas. Das einzige was man einstellt, ist eben welches Dateisystem ein zb neu erstellter Pool haben soll. Du kannst zB ZFS zum neuen Standard machen und wenn du irgendwann mal eine neue Disk dem Array hinzufügt oder du den Cache Pool neu erstellen solltest, zb weil eine SSD kaputt gegangen ist, würden die dann eben in ZFS formatiert. Was ist der Vorteil: ZFS läuft bei einem RAID Pool hoffentlich stabiler als BTRFS und es kann in den Logs anzeigen welche Datei evtl gerade kaputt gegangen ist. BTRFS zeigt nur Sektorennummern in den Logs an, womit man als Nutzer wenig anfangen kann. Letzteres kann auch im Array nützlich sein. Schlussendlich ist es für die meisten User aber schlicht egal welches Dateisystem man nimmt.
-
Es erforderte ein Firmware Update, aber nun konnte ich C8 im unteren PCIe Slot mit einer ASM1166 Karte erreichen: NVMe + ASM1166 PCIe X4 Karte (Slot 2) + SATA SSD ASM1166 Karte wurde erst nach Firmware-Update erkannt 9.5 W C8 Bei der Karte "I156-B00" handelt es sich um die PE-156 von Lycom, die ohne nervige LEDs auskommt. Die gibt es auch als Delock 89042 oder Ableconn PEX-SA156 oder Renkforce RF-4599662 oder Startech 6P6G-PCIE-SATA-CARD oder KALEA-INFORMATIQUE 11261040 🤪 Direkt aus China gibt es ansonsten ASM1166 Karten ab 30 €. Wobei ich hier gerade eine echt günstige M.2 Karte für 18 € gefunden habe.

-
Ok Problem gefunden. Es hat ein paar Stunden gekostet, aber schlussendlich, nachdem ich andere Kabel und den Stick sogar auf RC2 zurückgesetzt hatte und alles nichts half, kam ich mal darauf, statt den Namen "tower", mal die IP vom Server im Browser einzugeben und da gab es keine Wartezeit. Ich hatte dann natürlich direkt die Namensauflösung in Verdacht. Also habe ich in der Fritz!Box unter Netzwerk gesucht und unten bei den "ungenutzten Verbindungen" fand ich noch mal einen Eintrag "tower". Den habe ich gelöscht und jetzt läuft alles gewohnt schnell. Wie kann es nun sein, dass das die Namensauflösung kaputt macht und das nur bei websocket?! Leider kann ich es nicht mehr nachstellen. Naja wie auch immer. Es lag nicht an Unraid.
-
Nicht Prime, sondern Primary. Auf Deutsch: Primärspeicher und Sekundärspeicher. Du entscheidest dann ob eine neue Freigabe als Primärspeicher den SSD Pool oder das HDD Array nutzt. Und dann entscheidest du noch, ob du einen Sekundärspeicher haben will, auf den der Mover die Dateien verschiebt. Du interpretierst da zu viel rein. Es ändert sich ja nichts außer der Name. Tatsächlich braucht es vorher ein Diagramm, was ich ja sogar mal gemalt habe, weil kein Anfänger versteht was Yes/Prefer/Only/No bedeuten soll: https://gutt.it/unraid-cache-erklaerung-yes-no-prefer-only/ Dein aktueller Cache heißt in Zukunft Primärspeicher. Eben weil da die Dateien zuerst landen. An der Funktion, dass die HDDs nicht anlaufen, ändert sich durch die Namensänderung nichts.
-
Ok. An der Hardware liegt es schon mal nicht. Mit gänzlich anderer Hardware habe ich das selbe Problem. Auch mit einem anderen Laptop ist es so. Also bleibt noch Netzwerk oder Unraid als Ursache.
-
So eine Karte konnte ich nun für 100 € von einem China-Händler schießen. Ich bin mal gespannt was die so verbraucht. Ist laut Bildern baugleich zu der: https://www.amazon.de/PCIe-Controller-Karte-CHIPSET-ASM2824/dp/B09N9V3MGG/ Komisch war, dass die Karte von mehr als 5 China-Händlern bei Amazon angeboten wurden (unter verschiedenen ASINs) und nachdem ich sie bei einem gekauft hatte, flog sie bei allen anderen auch raus. Die verkaufen also alle vom selben Lager.

-
It seems no 600/700 chipset mobo reaches C9/C10. In the meantime I got feedback for multiple B660 and B760 and all of them stuck in C8. Some of them even reach only C3 or C6 🤨
-
I don't think this does really reduce power consumption as a monitor is switched off after 2 minutes or so.
-
You should try it without any disk except a single SSD. As mentioned in the first post, some HDDs have an impact on C-States.
-
Variables like this fully depend on the container. And depending on the container it is sometimes USER, UID, PUID etc and as far as I know maria db doesn't have such an option. Regarding your compose question: Ask in the compose support thread. I'm not supporting this plugin.
-
Not a single step of this is needed. The user is created with the name and password you set while editing the container template. Adminer isn't needed at all. Resetting the root password? It's described on the first page. Another option would be to install a second maria db container with a different name and different path and do an export / import through Adminer / phpmyadmin with the usual user login.
-
The desktop version is perfectly fine as long no monitor is connected. This is the first time I read that Unraid has lower power consumption than Ubuntu. Strange. Especially because of the huge difference.
-
Danke für den Hinweis. Da hab ich ein "M" vergessen. Ist nämlich ein mATX Board 😬
-
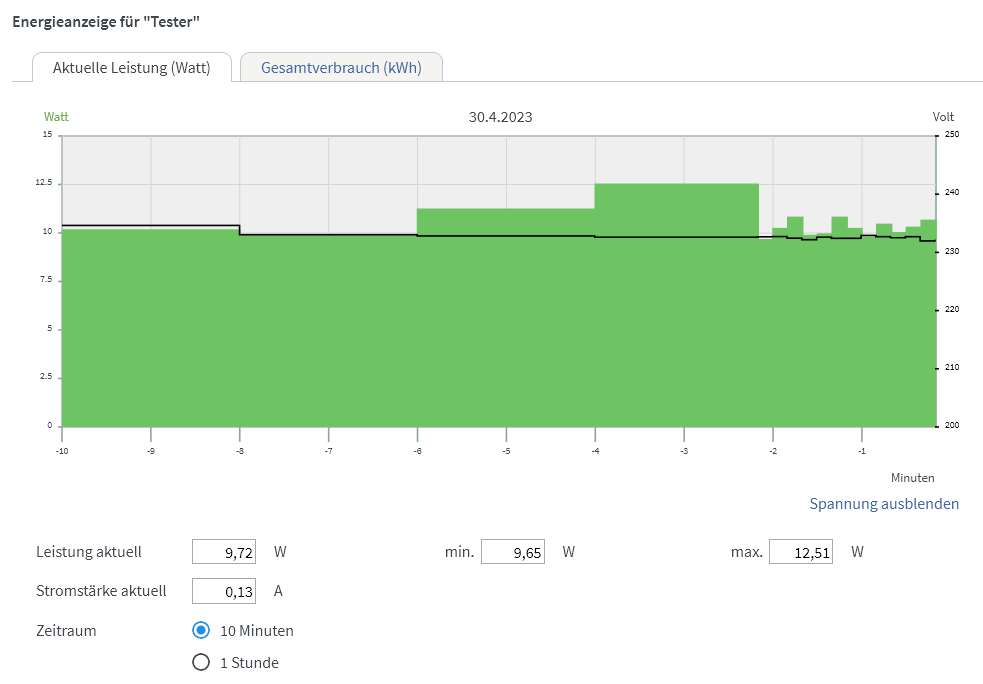
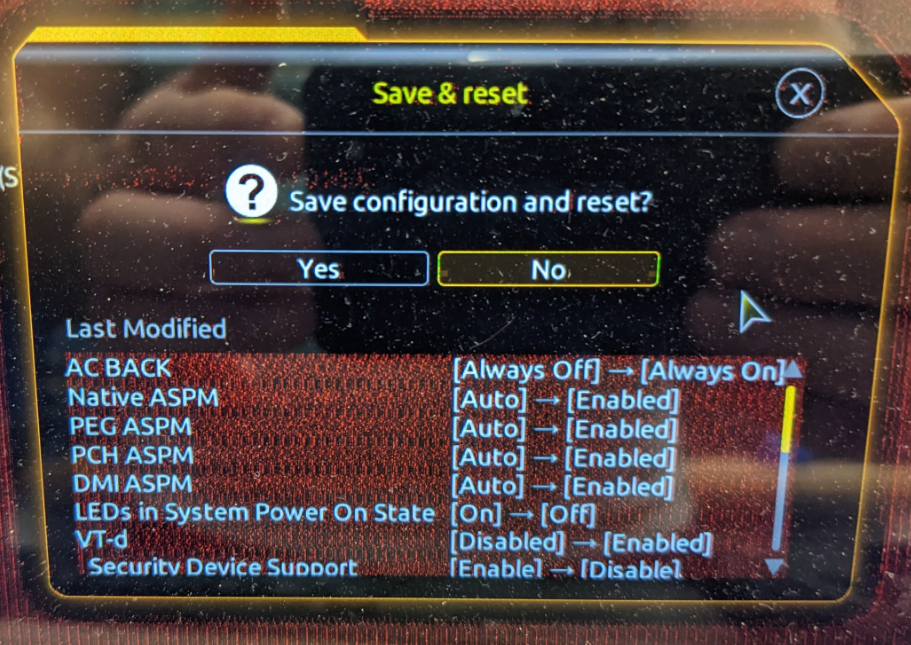
Ich versuche mich gerade an der 13ten Intel Generation. Ziel ist es ein günstiges Board mit 2.5G LAN und 4x SATA mit einer SATA Karte so zu erweiteren, dass das Setup trotzdem noch wenig Strom verbraucht (um überhaupt als Heimserver in Frage zu kommen). Das Ziel wäre ein Leerlaufverbrauch unterhalb von 10W. Hardware: Gigabyte B760M Gaming X DDR4 Intel i7-13700T Samsung 16GB RAM DDR4 Modul Samsung Evo Plus 2TB NVMe Corsair RM550x (2021) Netzteil Swissbit U-56n 4GB USB 3.1 Flash Drive Samsung QVO 8TB SATA SSD diverse SATA Karten zum Testen verfügbar (ASM1166 und JMB585, beide als PCIe und M.2 Karten) BIOS-Anpassungen siehe unten Statt powertop --auto-tune, setze ich die Tweaks manuell als Kommando ab (siehe powertop Thread) NVMe 7,4 W Dabei spielt es keine Rolle, ob die NVMe im CPU oder Chipsatz M.2 Slot steckt C8 NVMe + ASM1166 PCIe X1 Karte (Slot 1 oder Slot 2) + SATA SSD Die Karte wird weder im oberen (CPU), noch unteren PCIe Slot (Chipsatz) erkannt 15,4 W C3 NVMe + JMB585 PCIe X4 Karte (Slot 1) + SATA SSD 18,2 W C2 NVMe + JMB585 PCIe X4 Karte (Slot 1) + SATA SSD 13,4 W C3 NVMe + ASM1166 M.2 Karte (Slot 2) + SATA SSD 9,8 W C8 ("med_power_with_dipm" Tweak nur für "/sys/class/scsi_host/host[1-8]", ansonsten verliert die SATA SSD die Verbindung. Ich versuche die Tage ein Firmware-Update zu installieren, was dieses Problem beheben sollte) NVMe + ASM1166 M.2 Karte adaptiert in 1. PCIe Slot + SATA SSD 16,3 W C2 eigentlich hätte ich erwartet, dass die Karte nicht erkannt wird, wie im vorherigen Test mit der X1 Karte NVMe + ASM1166 PCIe X4 Karte (Slot 1) + SATA SSD ASM1166 Karte wurde erst nach Firmware-Update erkannt 16,3 W C2 NVMe + ASM1166 PCIe X4 Karte (Slot 2) + SATA SSD ASM1166 Karte wurde erst nach Firmware-Update erkannt 9.5 W C8 Geänderte BIOS Einstellungen:
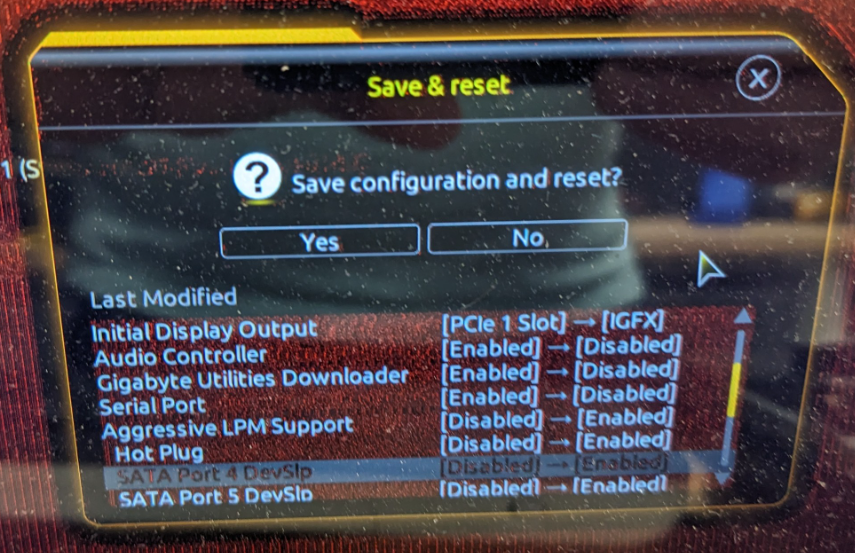
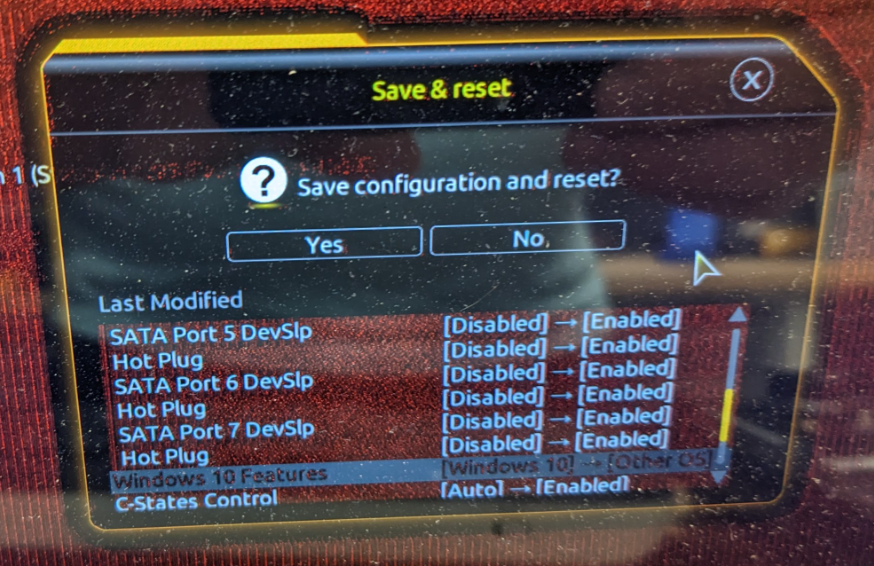
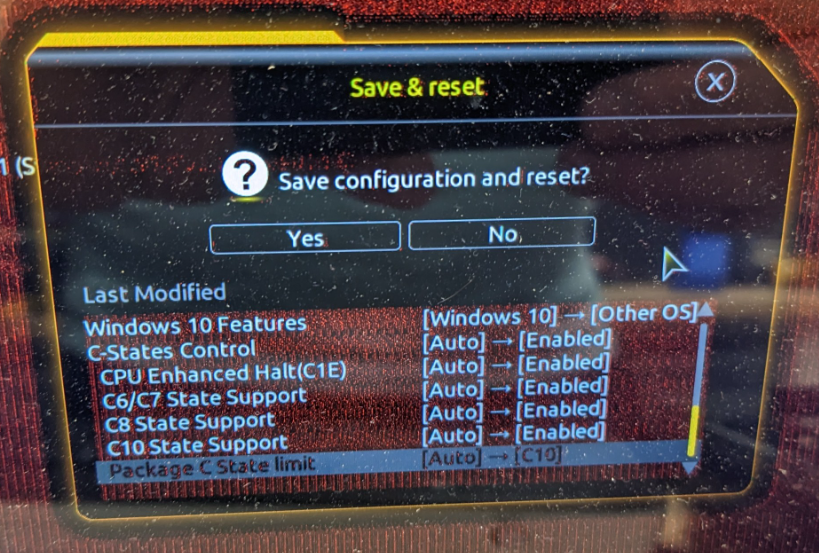


-
Ich habe meine ich seit RC3 das Problem, dass die WebGUI meines Testservers extrem langsam geworden ist. Laut Chrome Entwickleroptionen sind da Websockets auf, die ewig auf Antwort warten: Dann nach 20 Sekunden und mehr fangen Teile der Seite an zu laden: Das kann ich 1:1 in Edge 1:1 reproduzieren, weshalb es ja ein Chromium bezogenes Problem sein muss. Oder ich habe irgendein mir unbekanntes Problem im Netzwerk, was bei Websockets Probleme macht?! In Firefox ist die WebGUI jedenfalls schnell und arbeitet ganz normal. Allerdings sehe ich da im Netzwerkmonitor auch nichts von Websockets🤔 Kann jemand bestätigen, dass er das auch hat bzw gibt es vielleicht schon einen bekannten Bug Report dafür? Ich konnte bisher nichts finden, was ja komisch ist. Ich bin ja schließlich nicht der einzige auf der Welt der die neue Version installiert hat.

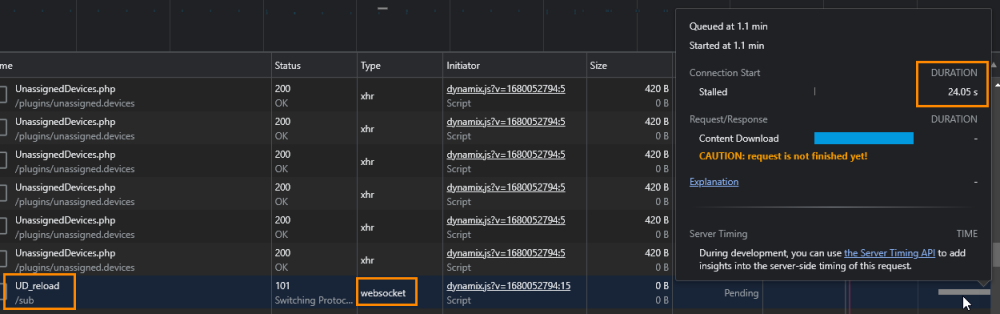
-
Gibt es den Ordner "Neue Filme" eventuell auch auf einen der Disks im Array?
-
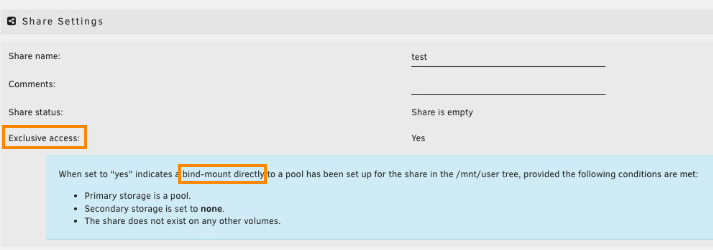
Es gibt eine interessante Neuerung in Unraid. Und zwar verabschiedet man sich von der eigentlich schon immer unlogischen Bezeichnung "Cache" und nennt den Pool, der vor das Array geschaltet wird, nun Primary Storage (Primärspeicher): https://unraid.net/blog/6-12-0-rc4 Man hat diesen Fehler nun eingesehen, nachdem das Dateisystem ZFS wirklich einen Cache besitzt und 2x Cache in der Weboberfläche mit unterschiedlichen Bedeutungen, versteht einfach kein Anwender mehr. Allerdings hat das auch den Nachteil, dass alle bisherigen Forumeinträge für zukünftige Unraid Nutzer verwirrend sein werden und diverse Anleitungen und FAQs umgeschrieben werden müssen 🙈 Als wäre das aber nicht genug, gibt es noch eine große Änderung: Exclusive Shares. Erstellt man einen Pool ohne Secondary Storage (Sekundärspeicher), dann wird dieser Pool nicht mehr mit Unraids typischem FUSE-Dateisystem eingebunden, der bekanntlich viel CPU-Leistung kosten kann, sondern man nutzt den einfachen Bind-Mount, der Datenträger ohne Overhead in das Betriebssystem einbindet: Das entspricht quasi dem früheren "cache only" Share, nur eben ohne den Overhead, der unnötige Last auf der CPU verursacht. Das ist also ideal für docker, appdata, vm und libvirt (Wichtig: Minimum Free Space auf 20 bis 100GB einstellen, sofern der Pool parallel noch als Primary Storage von anderen Shares verwendet wird!). Und da man nun "cache only" losgeworden ist, hat man die Chance gleich genutzt und die Bezeichnungen only, prefer, yes und no alle abgeschafft. Denn bei einem Share kann man nun nur noch wählen in welche RIchtung der Mover Dateien bewegen soll: Demnach: Cache > Array ist das frühere Yes Array > Cache ist das frühere Prefer Doch was ist mit "No" passiert? Auch die Option existiert noch. Nämlich dann wenn man als Primary Storage das Array auswählt. In dem Fall kann kein Secondary Storage ausgewählt werden. Et voila: "Cache No". Jetzt muss sich Limetech nur noch trauen die Split Level zu entfernen, die nicht mal die Hartgesottenen unter uns verstehen und der Array-Zwang muss auch weg, denn manche User betreiben ihren Server "ohne Array" (leeren USB Stick, alle Shares auf Pools).


-
It is simpel: White letters on black background, then it is 2021: Please add them all to the array as disks. Leave the parity slot free, so the array starts without creating a parity. Through Tools > New Config you can delete the array afterwards. Did you close the WebGUI while measuring? Even the Unraid Web Terminal must be closed. This has a huge impact on power consumption. Instead enable SSH and connect through your PCs terminal and "ssh root@tower"
-
Da und bei jedem Share. Wobei ich tatsächlich nicht weiß wann welcher Wert Vorrang hat. Daher empfehle ich überall das selbe einzustellen.
-
ZigBee. Mag ja sein, dass der Aktor wie bei UDP einfach nur "schluckt", aber HA könnte ja im Anschluss den Aktor fragen welchen Zustand er nun hat und dann eben das Kommando wiederholen. Wobei mir gerade einfällt, dass ich die Logs vom Stick vergessen habe zu prüfen. Also vielleicht hat ja der Stick selbst in dem Moment nichts vom HA angenommen. Wobei ja auch dann eine Wiederholung HA's Aufgabe wäre.
-
Ich habe sehr selten das Problem, dass ein Schaltsignal scheinbar nicht bei der Steckdose ankommt oder vielleicht gar nicht abgesendet wurde?! Kann man das irgendwie auf 100% Zuverlässigkeit bekommen? zB in dem der das Kommando 2x absetzt oder prüft, ob der finale Status wirklich erreicht wurde und falls nicht, dann noch mal das Kommando sendet?!