




mgutt
Moderators
-
Joined
-
Last visited
Everything posted by mgutt
-
Frag am besten in dem Thread. Da sind wie gesagt mehrere mit dem Board. Wobei ich die auch alle @-tten würde.
-
Was willst du hören. Wenn die Kohle locker in der Tasche ist, dann gönn dir die große CPU. Schadet halt nur dem Geldbeutel ^^ Supermicro hat gute Boards. Leider gibt es bei keinem der aktuellen Board wirklich Erfahrungswerte was den Stromverbrauch anbelangt. Du bist eingeladen es uns zu sagen 😁
-
Installiere dir das File Manager Plugin. Konsole ist nicht notwendig. Kannst du den Verbrauch messen? Aber dann mit nur einer SSD und dem Unraid Stick und powertop --auto-tune ausführen.
-
This "must" cost you 8 to 15W power consumption. In the German section power consumption is an important topic ^^ If I would have build your setup I would have relied on two 2TB M.2 NVMe (PCIe Adapter) instead of SATA SSDs. And for the Blu-Ray Drive I would have used an USB adapter (power adapted from Molex to DC). By that the 8 SATA ports would be exclusively avaliable for the backplane of the CS380 case and power consumption would be much lower.
-
Schon mal Adminer probiert? Ansonsten: Hast du auch immer brav den Appdata Ordner des Containers entfernt als du es neu versucht hast? Ansonsten nutzt du ja immer wieder die bereits installierten Daten und installierst ja gar nicht neu. Docker Sehe keine Sicher nicht. Docker Apps laufen direkt auf dem Unraid Host, VMs haben eine Emulationsschicht dazwischen. Jetzt hast du schon so viel neue Hardware und dann willst du dich mit den alten Platten rumschlagen? Wobei ganz ehrlich: Ich hätte 4x 2TB SSDs gekauft und fertig.
-
Du nicht gucken richtig. Es ist alles so wie es sein soll.
-
Das Array muss gestoppt werden, um diesen Wert ändern zu können. Naja warum wohl. Und jetzt auch noch keine iGPU möglich... der Stromverbrauch wird mit dem PIKE auch jenseits von Gut und Böse sein. Da zahlst du langfristig durch die Stromrechnung das, was du jetzt nicht für die Hardware bezahlt hast. Dann lieber irgendein gebrauchtes Consumer-Setup mit 6 SATA Buchsen und da eine ASM1166 Karte rein. Keine PIKE Karte, keine Grafikkarte.. 20 bis 30W gespart. CRC Fehler sind uninteressant, wenn sie nicht steigen. Da war nur irgendwann mal das Kabel oder der Stecker nicht in Ordnung oder nicht richtig verbunden. Leider merkt sich das SMART diese Fehler für immer.
-
Du meinst denke ich E3C246D4U-2L2T. @Hoopster hat es mal mit 40W gemessen, aber wenn ich seine Signatur so lese, hat er komischerweise nur 6 HDDs, aber trotzdem eine HBA Karte verbaut?! In dem Thread sind aber noch andere mit dem Board. Vielleicht erbarmt sich davon einer und misst es mal mit nur einer SSD.
-
Das Asrock Industrial IMB-X1314 mit 2x 2.5G LAN, 2x M.2, 8x SATA und mATX lässt sich übrigens auch über eBay.com kaufen: https://www.ebay.com/itm/204247860660 Mit Versand und Zoll sind das 400 €.
-
Keine Ahnung was bei CTT AG kaputt ist, aber die wollen für das ASRock Rack W680D4U-2L2T über 720 € haben. Hier könnte man es dagegen inkl Versand und Zoll für 660 € bestellen: https://www.ebay.com/itm/195695199075 Ich denke da hilft nur weiter warten bis es im normalen Handel verfügbar ist. Wobei ich mich frage wie Asrock überhaupt nennenswerte Stückzahlen bei den Preisen absetzen will. Stellen die davon nur 100 Stück her oder wie 🤨
-
T-CPUs are underclocked, not untervolted. This is done through a different base clock multiplier and reduced PL1 and PL2. The voltage depends only on the frequency. Here is an example of an older CPU at a similar frequency: i3-8100T http://valid.x86.fr/u1j0ym vs i3-8100 https://valid.x86.fr/tfx7nt I mean, maybe (I still don't believe that) its even a little be less voltage, but finally this saves only 1W in idle and maybe 5% in load scenarios. So there is no real reason to pay more for a T-CPU. I mean yes, at the moment both cost the same, but in the future the K will be much cheaper (for example the i7-12700T costs more than the i7-12700K) and finally you could sell the K CPU or use it in a gaming system... while the T-CPU is only useful in very special scenarios like an OEM system which does not allow to set PL1/PL2 through the BIOS. Note: These are two completely different CPUs. The T-CPU uses Golden Cove cores and the K-CPU Raptor Cove. Only the complete lineup of i7 and i9 uses Raptor Cove cores. So you could maybe decide between an i7-13700K and i7-13700T.
-
Es gibt für die Backup-Erstellung und auch den Restore eine Anleitung: https://docs.nextcloud.com/server/16/admin_manual/maintenance/update.html#what-does-the-updater-do Aber so wie du vorgehst, kann das eigentlich nur in die Hose gehen. Ich mein du machst kein Backup und dann versuchst du irgendwas zu machen, was jemand in einem Forum schreibt, was du Null verstehst. Wie willst du jemals zurück? Ist deine Nextcloud sonderlich komplex (Plugins, User, Dateien)? Ansonsten würde ich nämlich überlegen die offizielle Nextcloud-Version zu installieren, die User neu erstellen, Dateien in die entsprechenden Ordner kopieren, neu indexieren lassen und fertig. Der offizielle Container aktualisiert die Nextcloud-Version automatisch. Aber so oder so würde ich mal über Backups nachdenken.
-
Dateibasiert kann das jedes Unraid Dateisystem:
-
Da du VMs nur abwechselnd betreiben willst, reicht eigentlich auch ein 6-Kerner. Also ein i5 reicht völlig. Oder willst du eine VM mit mehr als 4 Kernen betreiben?
-
Ich würde vermutlich per Einschreiben eine Mahnung inkl. Fristsetzung zur Überweisung des Betrages versenden. Nach Ablauf der Frist dann ab zum Anwalt und der kann sich dann weiter austoben.
-
Besorg dir einen Xeon mit iGPU: https://en.wikipedia.org/wiki/List_of_Intel_Xeon_processors_(Haswell-based) Das sind LSI HBA Controller. Also 8 bis 15W zusätzlicher Stromverbrauch. Meiner Ansicht nach hast du die gänzlich falsche Hardware gekauft. Stell bei allen Shares und Pools einen Minimum Free Space ein zB 100GB. Dann springt der beim Hochladen fehlerfrei auf das Array. Zum Leeren nutzt man wie gehabt den Mover. Ist davon was SMR? Dann bitte nicht als Parity oder in einem RAID verwenden.
-
Hab das 750W die Tage mal getestet. Ähnlich sparsam wie das RMX wäre es, aber es hat Spulenfiepen. Bin ich echt mega enttäuscht. Habe es nun umsonst in meinem Gaming PC verbaut 😤
-
Check ich nicht. Was hindert dich daran die Dateien aus ShareA nach ShareB zu verschieben? zB mit dem File Manager Plugin?
-
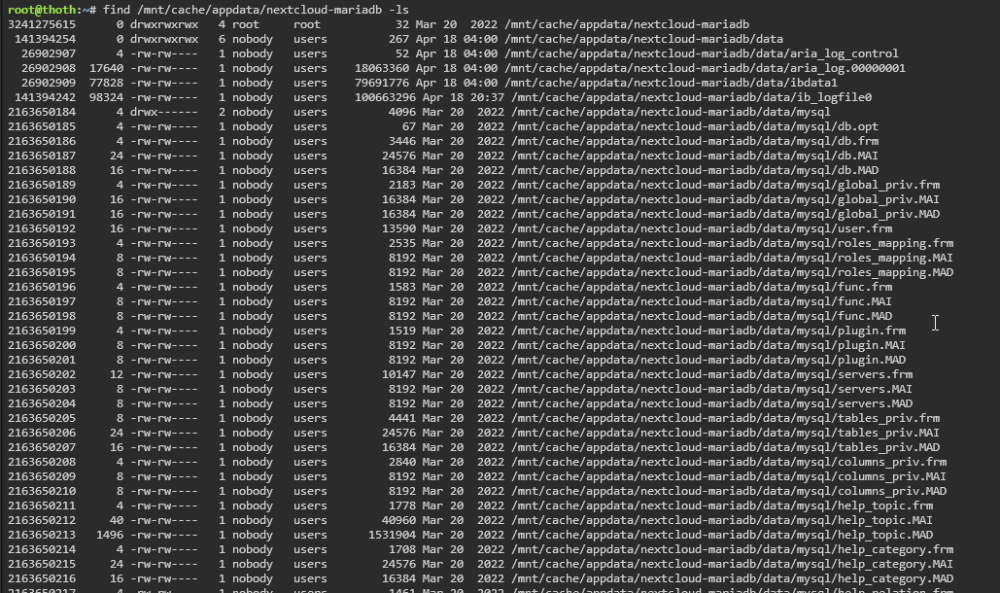
All files in appdata are extremely sensitive regarding user permissions. MariaDB official does not run as root. It runs with unraids default user permissions 99 (nobody) and group 100 (users): Here is an example of one of my installations: And how did you copy them to the UD SSD? And how is it formatted? If its not a Linux filesystem, all file permissions are lost. At first check your permissions: find /mnt/user/appdata/mariadb-official -ls In the next step correct the permissions if needed: chmod 777 /mnt/user/appdata/mariadb-official/config chmod 777 /mnt/user/appdata/mariadb-official/data chown root:root /mnt/user/appdata/mariadb-official/config chown root:root /mnt/user/appdata/mariadb-official/data find /mnt/user/appdata/mariadb-official -mindepth 2 -exec chown -v 99:100 {} \; find /mnt/user/appdata/mariadb-official -mindepth 2 -type d -exec chmod -v 700 {} \; find /mnt/user/appdata/mariadb-official -mindepth 2 -type f -exec chmod -v 660 {} \;

-
It can't be the same as no i3 Raptor Cove exists?! Note: Only i5-13600K and i5-13600KF are Raptor Cove. Not sure if you categorize them as "mid-market" ^^ My main hint was: If you want to buy an i3 13th, than you can buy an i3 12th gen instead as those are the same. If you stick to i3, than you could buy the i3-12100 or i3-13100 instead. Every CPU can be throttled to a T-CPU.
-
My next try will be this board: https://www.asrockrack.com/general/productdetail.asp?Model=W680D4ID-2T/G5/X550#Specifications 10G and 8 SATA ports and 2 nvme onboard + one free oculink for a third nvme or asm1166 m.2 adapter + 4 RAM Slots (which is rare for this small form factor). Should be available next month. I think it will be above 500 € 🙈 This is my only option as my rack is too small for mATX. But if it later supports the 48GB dimms.. 192GB RAM! Note: The T-CPU is not really needed. You can change PL1, PL2 and the base multiplicator usually in all BIOS'es, so you can convert a K-CPU easily into a T-CPU. Note2: The 13th gen has only efficient Raptor Cove Cores if you buy an i5 K-CPU or any i7 or i9 CPU. So the i3 or smaller i5s are all 12th gen (with higher clocks). Regarding my research Raptor Cove is at least 17% more efficient than Golden Cove (German): https://www.computerbase.de/forum/threads/intel-core-i5-13500-im-test-der-i5-mit-14-kernen-im-clinch-mit-ryzen-7000.2129425/page-9#post-28048507
-
Here is someone talking about C6 with ASM1166: https://forums.unraid.net/topic/102010-recommended-controllers-for-unraid/?do=findComment&comment=1198808
-
Die Kerne schleifst du 1:1 durch und nur du weißt ja, was du so mit dem PC machst. Beide haben die Grafikkarte oder wie? Auch beim 8700 braucht die VM eine. Eine iGPU kann man nicht durchschleifen. Ok, offensichtlich Single-Haushalt. 😁
-
Das Teil dürfte Strom ohne Ende raushauen und Server CPUs haben auch keine iGPU. Möglich, würde ich aber nicht machen. Die VM braucht dann eine Grafikkarte. Alles von einem Gerät abhängig machen ist aber eh keine gute Idee. Und was ist wenn Pi-Hole nicht läuft? Dann geht bei dir nichts mehr. Naja, reicht dir die CPU Leistung oder nicht. unRAID selbst wird davon nur wenig benötigen. Allerdings würde ich der VM 4 exklusive Kerne geben, wenn du sie als Client verwenden willst. Also 6 Kerne sollte die CPU schon haben.
-
Klingt komisch. Über ssh/FTP nutzt du doch den root von Unraid oder benutzt du eine andere FTP App?




