Leaderboard



Popular Content
Showing content with the highest reputation on 04/19/22 in all areas
-
All utility of such VM aside (yes, there is basically none), I thought it would be an interesting challenge to try and run deck's SteamOS since the real deal will be unobtainable for quite some time. I found a link to the recovery tool with an img file( Steam deck recovery image ), yet I had no luck booting from img and converting it to iso, qcow2, and vmdk for vmware workstation gave similar results. My best attempt resulted in infinite "Booting from Hard Disk..." using SeaBIOS, but it might have just been restricted by my limited KVM experience. So my question to the more KVM advanced friends, do you think it's possible to somehow sideload it into unraid? Did steam use some protection against such attempts or is it just completely incompatible? Let me know what do you think!1 point
-
I'm considering an upgrade to my server. Currently it's just a deconstructed Optiplex (i5-6500) and a couple LSI cards, plus a bunch of various drives. Of course I started cheap, spent a bunch of money on drives, and now want to upgrade. Partly for fun, and partly to just smooth out operation so I can reasonably run some VMs while Plex and the -arrs are doing things. I recently discovered the Huananzhi X99 motherboards they sell on AliExpress. ~$120 for a seemingly competent X99 board. I could slot in a Xeon, and since I have some DDR3 RAM around I was considering an E5-2696v3. I'd probably want to drop a Quadro P600 or P620 into this in this config since I'd lose iGPU. Total cost = ~$450. Does this kind of approach still make sense these days? Most of the hardware related posts I see are either Ryzen 3000-series focused or push for using a 9th-ish gen i7 to retain iGPU stuff. I'm just curious as to what people consider to be the most effective budget config options when buying used parts these days. Edit: Adding links for the aforementioned Huananzhi board and the data page for the E5-2696v3. Huananzhi TF X99:https://www.aliexpress.com/item/4000120773162.html E5-2696v3: https://www.cpu-world.com/CPUs/Xeon/Intel-Xeon E5-2696 v3.html1 point
-
Salut! Si vous aimez Discord, consultez le serveur de @superboki! https://discord.superboki.fr Peut-être que vous pouvez voir un peu de mon mauvais français? 😉1 point
-
One of the main reasons why the Unraid community is so great is due to our many Community Rockstars who go above and beyond to help others out. 🤘 In this blog series, we want to put a spotlight on key community members to get to know them a little better and recognize them for all that they've done for the Unraid community over the years. For this inaugural blog, we begin with two outstanding forum Moderators, @trurl and @JonathanM, who have helped out countless new Unraid users over the years: https://unraid.net/blog/rockstars-trurl-jonathanm If either have helped you out over the years here, please consider buying them a beer or lunch! trurl JonathanM
 1 point
1 point -
This is my first guess /tmp total 0 drwxr-xr-x 3 nobody users 60 Apr 19 12:54 Transcode You have (plex I imagine) transcoding to RAM. No problems with that. My thought is that in the Plex template you've got /transcode mapped to /tmp and within Plex you're telling it to transcode to /transcode/transcode. Shouldn't be an issue per se (that I can think of), but I can see tons of very weird things happening if /tmp ever gets deleted by an App. Your only solution right now is a reboot. Yeah, it's a not very well known feature that even if the GUI crashes during diagnostics collection that the file still gets generated and stored on the flash.1 point
-
Did the diagnostic collection ever complete? Did a file get created on the flash drive (logs folder) of the diagnostics? Upload it if it exists. (It's date & time stamped) Otherwise, your recourse pretty much is a reboot. For that directory "state" or var.ini to not exist really implies that something went through and really trashed the OS folders. I have never seen anything ever do that.1 point
-
Merci beaucoup pour tes explications @ChatNoir Et désolé pour le retard de ma réponse !1 point
-
No it only say this when I start the script in the background: Script location: /tmp/user.scripts/tmpScripts/Custom_unraid_loginscreen/script Now starting the script in the background This is my script: #!/bin/bash TYPE="retro-terminal" THEME="white.css" DOMAIN="thijselblaso.github.io" # If you update the domain after the script has been run, You must disable and re enable JS or the whole theme. ADD_JS="false" JS="custom_text_header.js" DISABLE_THEME="false" echo -e "Variables set:\\n\ THEME = ${THEME}\\n\ DOMAIN = ${DOMAIN}\\n\ ADD_JS = ${ADD_JS}\\n\ JS = ${JS}\\n\ DISABLE_THEME = ${DISABLE_THEME}\\n" IFS='"' set $(cat /etc/unraid-version) UNRAID_VERSION="$2" IFS=$' \t\n' LOGIN_PAGE="/usr/local/emhttp/login.php" # Changing file path to login.php if version >= 6.10 if [[ "${UNRAID_VERSION}" =~ ^6.10.* ]]; then echo "Unraid version: ${UNRAID_VERSION}, changing path to login page" LOGIN_PAGE="/usr/local/emhttp/webGui/include/.login.php" fi # Restore login.php if [ ${DISABLE_THEME} = "true" ]; then echo "Restoring backup of login.php" cp -p ${LOGIN_PAGE}.backup ${LOGIN_PAGE} exit 0 fi # Backup login page if needed. if [ ! -f ${LOGIN_PAGE}.backup ]; then echo "Creating backup of login.php" cp -p ${LOGIN_PAGE} ${LOGIN_PAGE}.backup fi # Use correct domain style case ${DOMAIN} in *"github.io"*) echo "Switching to github.io URL style" DOMAIN="${DOMAIN}\/theme.park" ;; esac # Adding stylesheets if ! grep -q ${DOMAIN} ${LOGIN_PAGE}; then echo "Adding stylesheet" sed -i -e "\@<style>@i\ <link rel='stylesheet' href='https://${DOMAIN}/css/addons/unraid/login-page/${TYPE}/${THEME}'>" ${LOGIN_PAGE} echo 'Stylesheet set to' ${THEME} fi # Adding/Removing javascript if [ ${ADD_JS} = "true" ]; then if ! grep -q ${JS} ${LOGIN_PAGE}; then if grep -q "<script type='text/javascript' src='https://${DOMAIN}/css/addons/unraid/login-page/" ${LOGIN_PAGE}; then echo "Replacing Javascript" sed -i "/<script type='text\/javascript' src='https:\/\/${DOMAIN}\/css\/addons\/unraid\/login-page/c <script type='text/javascript' src='https://${DOMAIN}/css/addons/unraid/login-page/${TYPE}/js/${JS}'></script>" ${LOGIN_PAGE} else echo "Adding javascript" sed -i -e "\@</body>@i\ <script type='text/javascript' src='https://${DOMAIN}/css/addons/unraid/login-page/${TYPE}/js/${JS}'></script>" ${LOGIN_PAGE} fi fi else if grep -q ${JS} ${LOGIN_PAGE}; then echo "Removing javascript.." sed -i "/<script type='text\/javascript' src='https:\/\/${DOMAIN}\/css\/addons\/unraid\/login-page/d" ${LOGIN_PAGE} fi fi # Changing stylesheet if ! grep -q ${TYPE}"/"${THEME} ${LOGIN_PAGE}; then echo "Changing existing custom stylesheet.." sed -i "/<link rel='stylesheet' href='https:\/\/${DOMAIN}\/css\/addons\/unraid\/login-page/c <link rel='stylesheet' href='https://${DOMAIN}/css/addons/unraid/login-page/${TYPE}/${THEME}'>" ${LOGIN_PAGE} echo 'Stylesheet set to' ${THEME} fi This is my white.css that I use: /*_____________________WHITE_THEME______________________*/ /* --body-before:#00ff771a; /* This is the background that creates the crt lines, background uses a transparency of 10% SET TO NONE TO REMOVE CRT EFFECT */ /* --body-after: #00ff7733; /* This is the background that creates the crt lines, background uses a transparency of 20% SET TO NONE TO REMOVE CRT EFFECT */ /* --body-animation: flicker; This is the background that flickers. SET TO NONE TO REMOVE THE FLICKER ANIMATION! */ /* --custom-text-header-animation: textflicker; /* SET TO NONE TO REMOVE THE FLICKER ANIMATION! */ @import url(https://thijselblaso.github.io/theme.park.edit/CSS/addons/unraid/login-page/retro-terminal/retro-terminal-base.css); :root { --main-bg-color:black; --body-before:#70d7f61a; --body-after: none; --body-animation: none; --logo: url(https://i.imgur.com/rLGePdW.png) center no-repeat; --text-color: #ffffff; --input-color: #ffffff; --link-color: #ffffff; --link-color-hover: #e68a00; --case-color: #ffffff; --button-text-color: #ffffff; --button-text-color-hover: #000; --button-color: #ffffff; --button-color-hover: #4caf50; --selection-color: #e68a00; --custom-text-header:#ffffff; --custom-text-header-shadow:#ffffff; --custom-text-header-animation: none; --input-font: 'Share Tech Mono', monospace; --text-font: 'Share Tech Mono', monospace; --loginbox-background-color: transparent; --text-shadow: 0 0 8px; --text-shadow-color: #000000; --box-shadow: 0 0 15px; }1 point
-
Agree… no reason you can’t back up /boot and /mnt/use/appdata with borg. I don’t like CA appdata because the backup files are huge and not very friendly with deduplication. I’ve used my borg archive to restore Plex multiple times without issue. With daily backups the risk of corruption on successive backups is limited, especially if you’re using the built-in DB backup capabilities of the various docker containers.1 point
-
Started right up!!! thank you so much!1 point
-
Stop using CA-Backup and use borg exclusively.1 point
-
Du hast in den Container-Einstellungen wahrscheinlich nicht /mnt durchgereicht, sondern /mnt/user... Wenn Du /mnt durchreichst, hast Du auch Zugriff auf remotes1 point
-
Because it's a different problem, you have an actual missing device: Apr 18 18:05:26 NAS emhttpd: /mnt/cache uuid: c0604d95-a95d-4473-b590-5d657cf45624 Apr 18 18:05:26 NAS emhttpd: /mnt/cache found: 2 Apr 18 18:05:26 NAS emhttpd: /mnt/cache extra: 0 Apr 18 18:05:26 NAS emhttpd: /mnt/cache missing: 0 Apr 18 18:05:27 NAS emhttpd: /mnt/cache warning, device 2 is missing Apr 18 18:05:27 NAS emhttpd: /mnt/cache Label: none uuid: c0604d95-a95d-4473-b590-5d657cf45624 Apr 18 18:05:27 NAS emhttpd: /mnt/cache Total devices 3 FS bytes used 429.72GiB Apr 18 18:05:27 NAS emhttpd: /mnt/cache devid 1 size 953.87GiB used 698.03GiB path /dev/nvme0n1p1 Apr 18 18:05:27 NAS emhttpd: /mnt/cache *** Some devices missing Apr 18 18:05:27 NAS emhttpd: /mnt/cache mount error: Invalid pool config No valid btrfs filesystem is being detected on the other NVMe device, and whatever happened it did before the diags posted, since no fs was detected on boot, if the device was wiped with wipefs you should be able to restore it with: btrfs-select-super -s 1 /dev/nvme1n1p1 If the command completes successfully then you need to reset the pool, to do that unassign all cache devices, start array to make Unraid "forget" current cache config, stop array, reassign all cache devices (there can't be an "All existing data on this device will be OVERWRITTEN when array is Started" warning for any cache device), start array, if it still doesn't mount please start a new thread in the general support forum and post new diags.1 point
-
Oh boy. I have 2 parity drives and 6 disks (currently the 1st disk is the only thing with data from the Main screen). My 1st drive (nonparity) went out and is bad. I figure I might as well but a replacement 8tb, preclear it and then replace it. I put it in, but my 6th drive (640mb) wasn't detected and now when I mount it unraid thinks the 640 is a replacement for the 8tb and tosses and error. I guess now I need to remove the 640mb from the array, but then it'll rebuild the parity without it, but the 1st drive (nonparity) is still bad. The preclear software also doesn't see the new 8tb unassigned drive. How can I remove the 640gb, preclear the 8tb, and then rebuild the 1st drive with the new 8tb? Currently it looks like it's data-rebuilding disk 6 with the new 8tb drive (that used to be 640gb). I'm feeling like what I need to do is let it finish, then find a way to remove that 8tb drive from the array (dunno how), and then set it up to replace the 1st disk (the bad one).1 point
-
Is hyperthreading enabled in the BIOS configuration?1 point
-
1 point
-
post a screenshot of the makemkv info widow that shows the drive info have you flashed the drive with the MK firmware?1 point
-
Hi, apologies for multi-posting but i have resolved my issue. what did it for me was disabling the CSM in my bios. Then when I rebooted Unraid, then started my screen is already UP. I don't really have a deep know how on this.. but for AMD SR-IOV needs PCIE-ARI to be enabled to work properly so i thought for those who experience the same issue with mine, you might want to check the BIOS settings for those.1 point
-
Current does not equate to RC/beta versions. Current pertains to stable versions. But I have updated that text to reflect that since there seems to be confusion.1 point
-
For anyone looking for this in the future, I had to modify the formatting of the script to be the following. #!/bin/bash nvidia-smi --persistence-mode=1 nvidia-persistenced fuser -v /dev/nvidia* @SimpleDino and @SpaceInvaderOne Can you all confirm on a system on 6.10.0 RC4?1 point
-
This should now be fixed with the latest image.1 point
-
1 point
-
Streams are the active files open to the share. Since you're showing items in there for appdata, I'd surmise that you're also using NFS (I'm not, so mine are always 0 for appdata since generally your containers won't access anything in appdata via SMB)1 point
-
@mastadook Checkmk-Agent ist in der CA App verfügbar.1 point
-
@Ford Prefect & @mastadook Ich hab das Plugin schon fast fertig genau so wie das Docker template...1 point
-
Hey there -- I've recently had huge stability issues with my own system, and they presented in a very similar way. You might try disabling C-States and see if it helps -- it seems to have, on mine. You can do this from a terminal, with a simple one-line command. It uses the Linux kernel's sysfs tree to block c-state transitions. If you use this command, it is not persistant, and will be reset on reboot. If it helps, you can try to disable them in your BIOS instead, or you can set this command to be run on boot. If it doesn't help, just don't run it again. for cpus in $(find /sys/devices/system/cpu -iname disable); do echo 1 > $cpus; done Repercussions of disabling c-states are minor -- potential higher power draw, hotter temperatures, etc -- but should not be significant enough to be of concern for long-term use. YMMV.1 point
-
I finally figured it out. It wasnt an issue with my router or docker networking. My issue was with deluge. I added the wireguard lan (10.253.0.0/24) under Container Variable: LAN_NETWORK and it all works now.1 point
-
Nope, i forked the repository and updated the version. (To use my version) edit your docker and change your repository to flubster/gsdock and it'll pull my updated version You'll need to add the mapping i stated above as i haven't created any UnRAID template, just pushed another docker image. YMMV. Be careful as I started from scratch (after pulling the initial image from the template) so haven't tried any upgrades etc Rubberbandboy1 point
-

From the album: Community Created Banners
1 point -
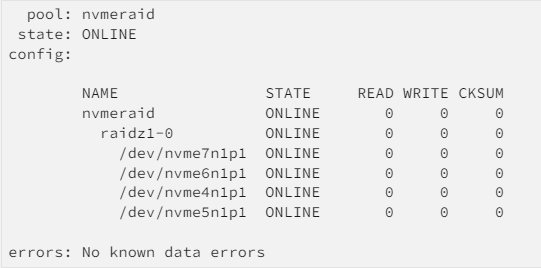
How can I monitor a btrfs or zfs pool for errors? As some may have noticed the GUI errors column for the cache pool is just for show, at least for now, as the error counter remains at zero even when there are some, I've already asked and hope LT will use the info from btrfs dev stats/zpool status in the near future, but for now, anyone using a btrfs or zfs cache or unassigned redundant pool should regularly monitor it for errors since it's fairly common for a device to drop offline, usually from a cable/connection issue, since there's redundancy the user keeps working without noticing and when the device comes back online on the next reboot it will be out of sync. For btrfs a scrub can usually fix it (though note that any NOCOW shares can't be checked or fixed, and worse than that, if you bring online an out of sync device it can easy corrupt the data on the remaining good devices, since btrfs can read from the out of sync device without knowing it contains out of sync/invalid data), but it's good for the user to know there's a problem as soon as possible so it can be corrected, for zfs the missing device will automatically be synced when it's back online. BTRFS Any btrfs device or pool can be checked for errors read/write with btrfs dev stats command, e.g.: btrfs dev stats /mnt/cache It will output something like this: [/dev/sdd1].write_io_errs 0 [/dev/sdd1].read_io_errs 0 [/dev/sdd1].flush_io_errs 0 [/dev/sdd1].corruption_errs 0 [/dev/sdd1].generation_errs 0 [/dev/sde1].write_io_errs 0 [/dev/sde1].read_io_errs 0 [/dev/sde1].flush_io_errs 0 [/dev/sde1].corruption_errs 0 [/dev/sde1].generation_errs 0 All values should always be zero, and to avoid surprises they can be monitored with a script using Squid's great User Scripts plugin, just create a script with the contents below, adjust path and pool name as needed, and I recommend scheduling it to run hourly, if there are any errors you'll get a system notification on the GUI and/or push/email if so configured. #!/bin/bash if mountpoint -q /mnt/cache; then btrfs dev stats -c /mnt/cache if [[ $? -ne 0 ]]; then /usr/local/emhttp/webGui/scripts/notify -i warning -s "ERRORS on cache pool"; fi fi If you get notified you can then check with the dev stats command which device is having issues and take the appropriate steps to fix them, most times when there are read/write errors, especially with SSDs, it's a cable issue, so start by replacing the cables, then and since the stats are for the lifetime of the filesystem, i.e., they don't reset with a reboot, force a reset of the stats with: btrfs dev stats -z /mnt/cache Finally run a scrub, make sure there are no uncorrectable errors and keep working normally, any more issues you'll get a new notification. P.S. you can also monitor a single btrfs device or a non redundant pool, but for those any dropped device is usually quickly apparent. ZFS: For zfs click on the pool and scroll down to the "Scrub Status" section: All values should always be zero, and to avoid surprises they can be monitored with a script using Squid's great User Scripts plugin, @Renegade605created a nice script for that, I recommend scheduling it to run hourly, if there are any errors you'll get a system notification on the GUI and/or push/email if so configured. If you get notified you can then check in the GUI which device is having issues and take the appropriate steps to fix them, most times when there are read/write errors, especially with SSDs, it's a cable issue, so start by replacing the cables, zfs stats clear after an array start/stop or reboot, but if that option is available you can also clear them using the GUI by clicking on "ZPOOL CLEAR" below the pool stats. Then run a scrub, make sure there are no more errors and keep working normally, any more issues you'll get a new notification. P.S. you can also monitor a single zfs device or a non redundant pool, but for those any dropped device is usually quickly apparent. Thanks to @golli53for a script improvement so errors are not reported if the pool is not mounted.
 1 point
1 point





















