



Squid
Administrators
-
Joined
-
Last visited
Everything posted by Squid
-
If you enable notifications within the plugin, then it sends out notifications (Notices) according to how you've specified them in Settings, Notification Settings. IE: Any agent you want.
-
umount not unmount
-
Looks like that's by design. Admittedly not super obvious though...
-
Yeah, you shouldn't ever mount anything into /mnt/user by yourself. unmount command is umount
-
Trying this now. Thanks for reporting
-
This actually looks like it was caused by an error on an older version of Connect when it got updated. Not related at all to 7.0.1. Easiest solution is a reboot and you're good to go
-
Actually, thank you. About two years ago I raised an issue with UD where I couldn't connect to a Mac Share, but it wasn't important to me. With your post I had to try it again and found the solution
-
Try this. Under the sharing options, check off the user for the Mac to store windows creds in a less secure manner but which gives greater compatibility
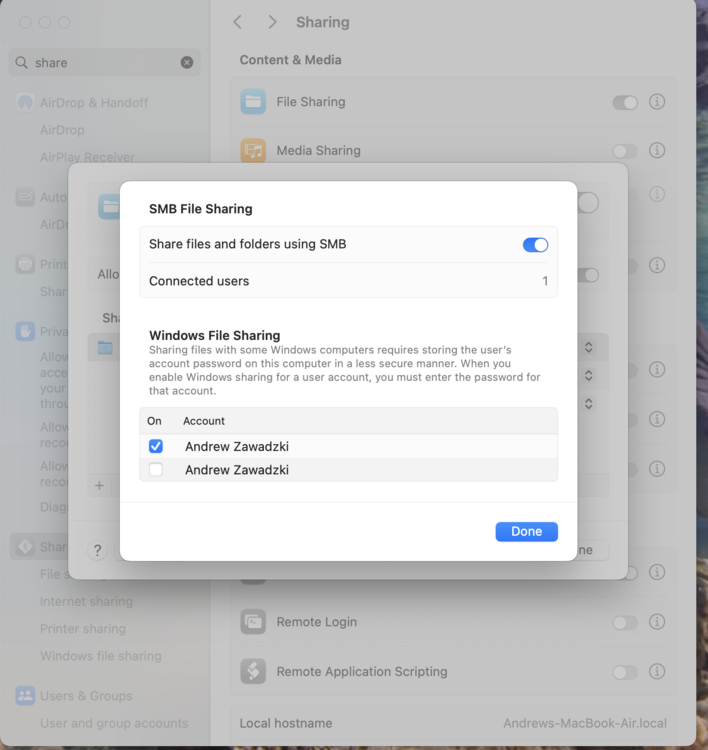
-
The next release (either today or tomorrow) should fix the crashes of inotify and the log size issue etc. These problems should actually have nothing to do with the plugin working or not. What you'd want to do is go to Shares, then browse the files within the share. There should be a ".recycle_bin" folder which will contain your files. Depending upon your settings in recycle bin and global share settings you might have to do this from the WebGUI, as the share might not display over the network as it is a hidden folder
-
Not at all. The coding has been moved to Limetech's repository https://github.com/unraid/recycle.bin and future updates are being published from there. Additionally, the same relocation of repositories also happened with UD, UD+, Preclear, Tips & Tweaks and cache dirs. The set of updates on 2025.02.14 handled this relocation (UD, UD+, Preclear were handled in December) so that the users would not be affected or need to perform any actions in order to continue to receive updates.
-
Not sure how the system would have responded to an update to a container at this point. No further updates will ever be done to this patch plugin...
-
It's a completely harmless message and it comes from the patch plugin, and no issues what so ever are related to that.
-
The mce appeared to me to come from the microcode update. Unlikely it's related to any crash of your system
-
My guess would be that the software needs to communicate at a lower level (hit the actual key's hardware) that won't work just be assigning the flash to the VM. You'd probably need to pass through a physical USB card
-
Then clearing the credentials on Windows in credential manager and reconnecting. I'm assuming that the creds you're using for the shares match the username on Windows.
-
Almost a given that if the batteries are over a year or 2 old they need to be replaced. But not necessarily your issue.
-
Go to shares, and click the B---p share. On it's settings, there's a number within min free space. Change it to 1. (no suffix's or anything just 1). Don't leave the entry blank. Does that fix it? (Possible you might also have to reboot the server)
-
Happened once to me when 7 was in beta. But never reoccurred for me as far as I know. And unfortunately couldn't fix what wasn't broken
-
First thing to check if only to rule it out is a memtest. But, it is also possible that inotify has an issue.
-
The files within this share in particular have their own permissions dictated by the container which creates them, and there isn't an guarantee that those permissions are compatible with exporting to Windows to any random user, and if you do happen to change the permissions within this share to make them compatible you run the risk that the containers will then have problems with accessing thing. The B---p share. What is creating the files within them? Assuming a docker container, many containers have within their settings the ability to set what permissions to use on the files it writes (outside of appdata). Setting it to 0777 would give full access to those files over the network
-
Is it showing as running within Settings, Scheduler, Mover Schedule?
-
Its in seconds, and effectively issues a docker stop command with an additional parameter for docker itself to kill the container if it hasn't stopped within the period you specified. This setting predates when the OS added support to change the docker stop timeout in Settings - Docker instead of always using the default 10 seconds from docker itself. IIRC, if you don't set anything then the plugin will use whatever you've set in settings - docker
-
There's also the mirror to flash option. No additional settings required. Power issues can at times be messed. In a former employment I wound up diagnosing a crash on a system that was basically impossible to crash that would always occur at a certain time of the day. Turned out that it was caused by a sodium light in the parking lot that was failing and causing massive EFI / noise on the circuit when it turned on.
-
try switching one of them (edit the container) and change the repository from lscr.io/linuxserver/blah to instead simply be linuxserver/blah
-
Wouldn't be a bad idea either to run memtest from the boot menu for at least a couple of passes. An unlikely but still possible issue if memtest passes is that you're running two sets of mismatched RAM. (A-Data and Patriot). The highest stability on memory comes from using matched sets and if not possible then ensuring that the CL timings match between the sets


