




i-B4se
Members
-
Joined
Everything posted by i-B4se
-
Sind wieder Ferien? Er hat dich doch normal gefragt, da du nirgends deinen Weg angeben hast. Wenn du in deinem Beruf auch so schnell voreilige Schlüsse ziehst, dann Glückwunsch an die Kollegen/Kunden.
-
Prefer und only sind quasi identisch. Aber bei Prefer hat man den Vorteil, dass wenn der Cache voll ist, die Daten ins Array geschoben werden. Sollte dann wieder Platz im Cache sein, dann schieb der Mover die Daten wieder vom Array in den Cache. Bei Only wird nichts mehr geschrieben wenn der Cache voll ist und es entstehen Fehler.
-
Es ging darum, ob deine Appdata etc. teilweise auf dem "HDD-Array" liegen und nicht alles auf dem Cache. Dazu muss unter Freigaben z.b. die "appdata" auf Cache "bevorzugt/prefer" stehen. Sonst kann es sein das die Daten auf dem langsamen Array landen. Aber es läuft ja jetzt, also kann man das vernachlässigen. Kannst meine Beitrag als "gelöst" markieren, evtl. kommt die Frage nochmal und dann findet man es direkt.
-
@Grendo Hast du den "Docker data-root" umgestellt oder warum steht da "Verzeichnis? Ich hab da "btrfs vDisk" Dann nimmst du bei "vDisk Pfad" -> "/mnt/cache/system/docker/docker.img" oder "/mnt/user/system/docker/docker.img" und bei "Standard appdata Speicherpfad:" -> "/mnt/cache/appdata/" oder "/mnt/user/appdata/" jeweils ohne ""

-
Bei einer Parity kann eine Platte ausfallen. Bei zwei Parity Disks können zwei Platten gleichzeitig ausfallen. Poste doch mal die Fehlermeldungen. Hast du mal ein anderen Stromanschluss getestet? Evtl. hat dieser ein wackler und der Strom fällt immer aus.
-
Ja, das ist ein Testserver gewesen. Da gab es quasi kein Array nur ein größerer Pool. Ich hab die Daten gestern einfach gelöscht und dann konnte ich die aus dem Raid0 Verbund schnell rausnehmen.
-
Ich benutze einfach mal den Thread für eine weitere Frage In einem anderen Server, quasi ein Testaufbau, habe ich ein Pool erstellt mit 3 HDDs die als Raid laufen. Diesen möchte ich auflösen und eine Platte soll alleine drin bleiben. Wie kann ich das schnell auflösen? Daten darauf sind völlig unwichtig und werden nicht benötigt. Ich hab das Array gestoppt und die Disks aus dem Pool rausgenommen und eine neue Konfiguration gestartet. Muss ich jetzt per "Balance" die einzelne Disk zurücksetzen? Weil das dauert mir gerade zu lange
-
Moin, danke schon mal für die Antworten. Backups sind vorhanden. Das ist kein Problem. Ich glaube ich werde das mit der USB-Lösung machen. Die Daten der zwei 4 TB per USB auf die 8 TB übertragen dann die Parity und die Platten raus und die neuen Platten rein. Zur Not habe ich noch die Backups, falls etwas schief gehen sollte :)
-
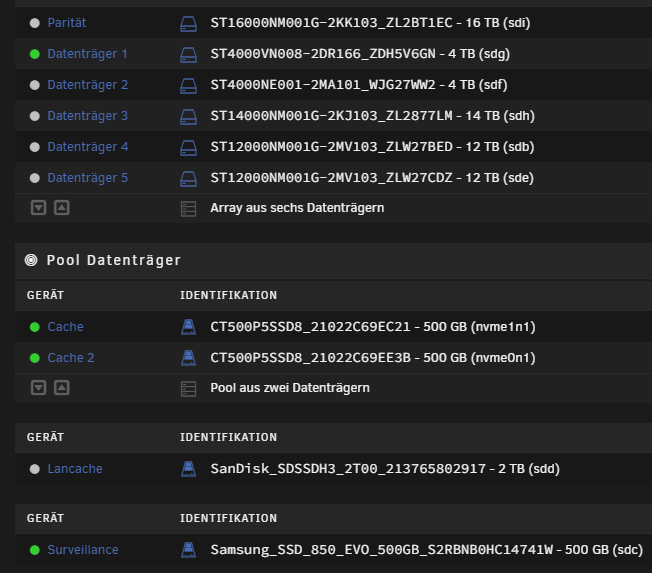
Mahlzeit zusammen, langsam wird es Eng - ich brauche mehr Platz Hier eine kurze Übersicht: Das Problem ist, ich hab keinen freien Sata-Port und eine zusätzlich Sata-Karte möchte ich noch nicht einbauen. Ich wollte jetzt folgendes machen: Die zwei 4 TB raus und eine 8 TB rein, die habe ich noch hier rumliegen. Eine neue 18 TB ist geordert und soll die 16 TB Parity ersetzen. Somit könnte ich den Speicher erweitern und brauche keine zusätzliche Sata-Ports. Aber wie kann ich die Daten auf die andere Platte übertragen ohne freien Port? Parity abklemmen -> 8 TB rein und die Daten der zwei 4 TB HDDs übertragen und dann rausnehmen? Anschießend die neue 18 TB als Parity und die 16 ins Array? Oder würdet ihr das ganz anders machen? Wie sieht es mit den ganzen Laufwerkspfaden aus? Auf der "sdg" liegt Nextcloud? Gibt es nach dem Wechsel da ein Problem. Das die Daten von Nextcloud neu indexiert werden müssen, dass ist mir klar. Besten Dank vorab! Gruß
-
Nur als Randnotiz: https://www.ebay-kleinanzeigen.de/s-bestandsliste.html?userId=22671052&pageNum=1&sortingField=SORTING_DATE Der macht richtig gute Arbeit und der Wechsel vom Sockel kostet nicht die Welt (Sockel 1151 ca. 40€). Ich hab bei dem auch schon ein Board reparieren lassen und im Luxx wird der auch empfohlen.
-
Bei mir ist "Frontend 20230202.0", also etwas aktueller. @Bengon ConBee2
-
Also quasi mind. 172€ pro Monat? Uiuiui, das tut ja weh. Die Preise, egal ob Fest- oder Mobilnetz, sind in DE einfach nur lächerlich. Wie du schon geschrieben hast, ist es in anderen Ländern einfach geil was die für Leitungen haben.
-
Bei der VM läuft die Version (2023.2.1) ohne Problem, aber es gab auch zusätzlich ein Core Update.
-
Jup, ich würde alles ausschalten und erstmal laufen lassen. Evtl. auch mal nach den Bios-Settings schauen. Und sollte der Server ohne abstürze laufen, dann würde ich die Einstellungen nach und nach aktivieren.
-
Das hat bei mir auch geholfen. Ich hatte ständig mal Hänger ohne das wirklich was in den Logs stand. Ohne die Stromspareinstellungen läuft er ohne Probleme durch. Wahrscheinlich habe ich durch die ganzen Neustarts mehr verbraucht wie durch die Laufzeit mit Powersaves.
-
Hallo, evtl. kann man den Thread für die ein oder andere Fehlermeldung nutzen. Ich hab nämlich gerade so einen Fall und ich glaube nicht das es mit Unraid direkt zusammenhängt. Wenn nicht gewünscht, dann kann ich den Titel auch abändern. Der Server hat eine Uptime von 20 Tagen und der Fehler ist jetzt zwei Mal kurz nacheinander aufgetaucht: 22.01. Jan 22 10:26:31 NAS kernel: mce: [Hardware Error]: Machine check events logged Jan 22 10:26:31 NAS kernel: [Hardware Error]: Corrected error, no action required. Jan 22 10:26:31 NAS kernel: [Hardware Error]: CPU:1 (19:21:0) MC17_STATUS[Over|CE|MiscV|AddrV|-|-|CECC|-|Poison|-]: 0xccccccccc35bf3eb Jan 22 10:26:31 NAS kernel: [Hardware Error]: Error Addr: 0x0000000000000000 Jan 22 10:26:31 NAS kernel: [Hardware Error]: IPID: 0x0000000000000000 Jan 22 10:26:31 NAS kernel: [Hardware Error]: Bank 17 is reserved. Jan 22 10:26:31 NAS kernel: [Hardware Error]: cache level: L3/GEN, tx: GEN 24.01. Jan 24 05:51:35 NAS kernel: mce: [Hardware Error]: Machine check events logged Jan 24 05:51:35 NAS kernel: [Hardware Error]: Deferred error, no action required. Jan 24 05:51:35 NAS kernel: [Hardware Error]: CPU:1 (19:21:0) MC13_STATUS[Over|-|-|AddrV|PCC|SyndV|UECC|Deferred|Poison|Scrub]: 0xc765ffc883007f37 Jan 24 05:51:35 NAS kernel: [Hardware Error]: Error Addr: 0x0000000000000000 Jan 24 05:51:35 NAS kernel: [Hardware Error]: IPID: 0x0000000000000000, Syndrome: 0x0000000000000000 Jan 24 05:51:35 NAS kernel: [Hardware Error]: Bank 13 is reserved. Jan 24 05:51:35 NAS kernel: [Hardware Error]: cache level: L3/GEN, tx: DATA Ist da gerade was am sterben oder wurde da etwas vom ECC-Ram korrigiert? Blicke da nicht so ganz durch, aber der Server läuft ohne Einschränkung.
-
50€ für so ein Teil? Und wahrscheinlich noch Cloud gebunden. ESP32 inkl. Cam kostet glaube ich nen 10ner + AI-on-the-edge-device Nutze ich seit 2 Jahren ohne Probleme.
-
Natürlich ist das Netz voll mit Fehlschlägen. Niemand postet das sein restore funktioniert hat. Ich habe schon einige male HA wiederherstellen müssen (neuer Server, vergeigte Einstellung etc.) und bisher ging das ohne Probleme. Ich mache jeden zweiten Tag ein volles Backup von HA und speichere 7 Stück hintereinander. Wenn das letzte Backup nicht läuft, dann wohl eines davor.
-
Warum nutzt ihr nicht die Backupfunktion von HA in der configuration.yaml? Das könnt ihr auch zeitlich begrenzen.
-
Kann ich so nicht bestätigen, aber mein HA läuft auch als VM. Meine Datenbank hat 15GB

-
Das sag ich doch Der stündliche Mover läuft ohne Probleme. Das wurde schon ausprobiert.
-
@mgutt Das hatten wir schon getestet und läuft auch. Aber der Daily Schedule läuft nicht richtig. Und ich vermutete es liegt an der falschen Uhrzeit. Da er dann natürlich zu falschen Zeit kontrolliert und dann nichts in den Logs steht.
-
Stimmt deine Uhrzeit im Bios?
-
Eine Sache die mir gerade auffällt. Deine Uhrzeit stimmt nicht. Dadurch würde der Mover-Schedule zu einer anderen Uhrzeit auslösen als du es eigentlich willst. Bitte die Zeit unter Einstellungen anpassen.
-
Schieb nochmal eine Datei da rein und änder den Mover-Schedule auf "Stündlich" und "jede Stunde" und warte dann mal Irgendwann muss ja was in den Protokolierungen auftauchen. Poste das dann nochmal. Normalerweise muss der Mover dann um 19 Uhr starten.





