




dgriff
Members
-
Joined
-
Last visited
Everything posted by dgriff
-
Indeed it does, working now, thanks again!
-
Not having any luck with a piece stored on my websever. DNS works fine. Can't figure it out... If I take the same URL and paste it into firefox, it immediately returns the correct chunk of the key Testing path: :http,url='https://www.[removed].com/share/share2.txt': 2:31PM DBG Debug logging enabled 2:31PM DBG Build information git_dirty=no revision=0ac10a054a7fbb2167a048698b053eeb4ace32b4 tag=2025.12.16.0447 2:31PM DBG Read fsState from var.ini fsState=Started 2:31PM DBG var.ini found and readable fsState=Started 2:31PM FTL Failed to execute command error="failed to fetch share: failed to open object: object not found" Result: FAILAny ideas?
-
Having a problem viewing the unRAID terminal with IPMIView 2.22.0 under Windows 11. Identical Issue appears on both of the Supermicro chassis that I have, reverting both to 7.0.1 fixes the issue on both. Works fine in 7.0.1, however in 7.1.0-beta 1, the issue appears to begin moments after this line appears on the display Mar 18 22:41:33 Backup kernel: RAPL PMU: API unit is 2^-32 Joules, 3 fixed counters, 163840 ms ovfl timer I suspect it's actually triggered in here somewhere (not visible on-screen, which is distorted) Mar 18 22:41:33 Backup kernel: mgag200 0000:08:01.0: vgaarb: deactivate vga console Mar 18 22:41:33 Backup kernel: Console: switching to colour dummy device 80x25 Mar 18 22:41:33 Backup kernel: [drm] Initialized mgag200 1.0.0 for 0000:08:01.0 on minor 0 Mar 18 22:41:33 Backup kernel: fbcon: mgag200drmfb (fb0) is primary device Mar 18 22:41:33 Backup kernel: igb 0000:06:00.0: added PHC on eth0 Mar 18 22:41:33 Backup kernel: igb 0000:06:00.0: Intel(R) Gigabit Ethernet Network Connection Mar 18 22:41:33 Backup kernel: igb 0000:06:00.0: eth0: (PCIe:5.0Gb/s:Width x4) 00:25:90:f5:60:b2 Mar 18 22:41:33 Backup kernel: igb 0000:06:00.0: eth0: PBA No: 105900-000 Mar 18 22:41:33 Backup kernel: igb 0000:06:00.0: Using MSI-X interrupts. 8 rx queue(s), 8 tx queue(s) Mar 18 22:41:33 Backup kernel: Console: switching to colour frame buffer device 128x48 Mar 18 22:41:33 Backup kernel: mgag200 0000:08:01.0: [drm] fb0: mgag200drmfb frame buffer device Diagnostic attached. Video link showing the issue Shows: 7.0.1 stable boot-up booting 7.1.0-beta 1 at 3:34 glitching begins at 5:10 (warning, flashing screen, careful if you're sensitive to such things). Would love to get this fixed, the IPMI terminal is too valuable to leave broken. backup-diagnostics-20250318-2244.zip
-
2 systems on Supermicro Xeon motherboards with IBM 1015 SAS adapters. Everything upgraded perfectly!
-
Thanks for the reply! [SOLVED] Update - I had to reinstall sanoid a while ago, and it looks like I messed up the config options on my replication target so it was generating snapshots on the target as well as the source. Of course that will cause issues because it can't have snapshots synced if they're generated on the source and the target. Which one to believe? Disabled and gonna see what happens. Edit: seems fine now even between V7 and V6 (both ZFS file systems were created on V6, so don't need to worry about any compatibility issues there).
-
Grandfathered will continue to get all upgrades free for life. It’s been stated in the vlog.
-
The FUD from unraid competitors and fans of the competition is only just beginning. Look for a huge disinformation campaign.
-
Reddit is a slum now. Don’t care about them at all anymore. I suggest you delete them as well. You’ll be happier.
-
Anyone know what's going on with the changedetection.io docker? Been showing as unavailable for a few days now. I see another option at Linuxserver, not sure if it's better to just switch over?
-
Was just going through some array maintenance and noted that one of my drives (one of the oldest) was encrypted back in the LUKS1 days, and still had the old header on it. I'm assuming there's no way to upgrade the drive without moving everything off, reformatting, and putting it back (or just adding a new array drive with the more modern encryption and doing a single and a reformat of the old one). Are there any significant reasons to bother with this/worry about it, including security issues, speed, or relaibility? I just used the backup headers option to backup the headers from all of my encrypted drives, and the 1M on the old drive vs. the 16MB for the new ones was the first thing that caught my eye to reveal the difference.
-
Had this problem with RC3 and RC4, where the first reboot after update results in a "stale configuration" when restarted, so the array never starts (only offers reboot and shutdown buttons on the UI). Fortunately on second reboot it seems to work OK.... But why? Had this issue on RC3, but forgot to capture a diagnostic before I rebooted, so when it happened this time, I remembered, and here it is! diagnostics-20220319-1715.zip
-
Great plugin, I ran the extended tests and it found a number of duplicate files on different array drives (probably from mistakenly cancelling an unbalance operation - would be great if the unbalance plugin really had a pop-up warning about duplicates left behind if you cancel, or just an option to clean-up the sources immediately after each move takes place rather than at the end, or leave a script behind you could run to clean-up leftovers automatically). That said, is there any way to schedule an "extended test" to automatically run once a month as opposed to the standard test on a weekly basis?
-
Couldn't make influxdb v2.x connect properly. Running the "influx" command through the docker command prompt never connected to the database, so was unable to create databases for my applications to populate. Doing the same setup process with influx v1.7 worked fine.
-
Hoping someone can point me in the direction of why unifi-poller isn't returning any data. Checked the logs for the unifi-poller docker and it seems to be working properly. Same with Prometheus. Grafana finds the Prometheus database, but doesn't seem to be getting any data. Unifi-poller: 2021/04/12 23:34:05.222977 updateweb.go:193: [INFO] => URL: https://192.168.1.9:8443 (verify SSL: false) 2021/04/12 23:34:05.222991 updateweb.go:193: [INFO] => Version: 6.1.71 (a44c7aa3-f9c0-4d69-9eda-6ae6b9ab3ce6) 2021/04/12 23:34:05.223005 updateweb.go:193: [INFO] => Username: unifipoller (has password: true) 2021/04/12 23:34:05.223018 updateweb.go:193: [INFO] => Hash PII / Poll Sites: false / all 2021/04/12 23:34:05.223041 updateweb.go:193: [INFO] => Save Sites / Save DPI: true / false (metrics) 2021/04/12 23:34:05.223069 updateweb.go:193: [INFO] => Save Events / Save IDS: false / false (logs) 2021/04/12 23:34:05.223086 updateweb.go:193: [INFO] => Save Alarms / Anomalies: false / false (logs) 2021/04/12 23:34:05.223099 updateweb.go:193: [INFO] => Save Rogue APs: false 2021/04/12 23:34:05.223239 logger.go:17: [INFO] InfluxDB config missing (or disabled), InfluxDB output disabled! 2021/04/12 23:34:05.223281 logger.go:17: [INFO] Loki config missing (or disabled), Loki output disabled! 2021/04/12 23:34:05.223378 logger.go:15: [INFO] Internal web server disabled! 2021/04/12 23:34:05.226000 logger.go:17: [INFO] Prometheus exported at http://0.0.0.0:9031/ - namespace: unifipoller Prometheus: level=info ts=2021-04-14T06:40:48.723Z caller=main.go:423 build_context="(go=go1.16.2, user=root@a67cafebe6d0, date=20210331-11:56:23)" level=info ts=2021-04-14T06:40:48.723Z caller=main.go:424 host_details="(Linux 5.10.28-Unraid #1 SMP Wed Apr 7 08:23:18 PDT 2021 x86_64 f7ef30f14488 (none))" level=info ts=2021-04-14T06:40:48.723Z caller=main.go:425 fd_limits="(soft=40960, hard=40960)" level=info ts=2021-04-14T06:40:48.723Z caller=main.go:426 vm_limits="(soft=unlimited, hard=unlimited)" level=info ts=2021-04-14T06:40:48.732Z caller=web.go:540 component=web msg="Start listening for connections" address=0.0.0.0:9090 level=info ts=2021-04-14T06:40:48.733Z caller=main.go:795 msg="Starting TSDB ..." level=info ts=2021-04-14T06:40:48.737Z caller=tls_config.go:191 component=web msg="TLS is disabled." http2=false level=info ts=2021-04-14T06:40:48.737Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1618293830375 maxt=1618315200000 ulid=01F362TFS260HS5A3H217T57VK level=info ts=2021-04-14T06:40:48.738Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1618315205375 maxt=1618336800000 ulid=01F36QDNGNPE73SFT2E75GSR57 level=info ts=2021-04-14T06:40:48.739Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1618358405375 maxt=1618365600000 ulid=01F37553S58XXY9EA7T0PPH3XG level=info ts=2021-04-14T06:40:48.739Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1618365605375 maxt=1618372800000 ulid=01F37C0V14XS97P35V8V3RDRMW level=info ts=2021-04-14T06:40:48.740Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1618336805375 maxt=1618358400000 ulid=01F37C0V77EETHRZVDG6CSDM1Z level=info ts=2021-04-14T06:40:48.779Z caller=head.go:696 component=tsdb msg="Replaying on-disk memory mappable chunks if any" level=info ts=2021-04-14T06:40:48.782Z caller=head.go:710 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=3.115569ms level=info ts=2021-04-14T06:40:48.782Z caller=head.go:716 component=tsdb msg="Replaying WAL, this may take a while" level=info ts=2021-04-14T06:40:48.791Z caller=head.go:742 component=tsdb msg="WAL checkpoint loaded" level=info ts=2021-04-14T06:40:48.851Z caller=head.go:768 component=tsdb msg="WAL segment loaded" segment=8 maxSegment=12 level=info ts=2021-04-14T06:40:48.898Z caller=head.go:768 component=tsdb msg="WAL segment loaded" segment=9 maxSegment=12 level=info ts=2021-04-14T06:40:48.949Z caller=head.go:768 component=tsdb msg="WAL segment loaded" segment=10 maxSegment=12 level=info ts=2021-04-14T06:40:48.983Z caller=head.go:768 component=tsdb msg="WAL segment loaded" segment=11 maxSegment=12 level=info ts=2021-04-14T06:40:48.985Z caller=head.go:768 component=tsdb msg="WAL segment loaded" segment=12 maxSegment=12 level=info ts=2021-04-14T06:40:48.985Z caller=head.go:773 component=tsdb msg="WAL replay completed" checkpoint_replay_duration=9.422595ms wal_replay_duration=194.019563ms total_replay_duration=206.643012ms level=info ts=2021-04-14T06:40:48.991Z caller=main.go:815 fs_type=65735546 level=info ts=2021-04-14T06:40:48.991Z caller=main.go:818 msg="TSDB started" level=info ts=2021-04-14T06:40:48.991Z caller=main.go:944 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml level=info ts=2021-04-14T06:40:48.993Z caller=main.go:975 msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=2.101765ms remote_storage=5.596µs web_handler=1.603µs query_engine=2.343µs scrape=575.961µs scrape_sd=86.107µs notify=45.668µs notify_sd=66.982µs rules=3.986µs level=info ts=2021-04-14T06:40:48.993Z caller=main.go:767 msg="Server is ready to receive web requests." Any ideas? I have Grafana working properly with PostgreSQL for Teslamate.
-
Well not specifically windows, any network user is the same. Can't do anything with my Mac over the network either as remote connections don't have the permissions. How would I fix it?
-
The issue is that the files created work perfectly fine within the docker, so it's not an issue they need to fix within the docker. The issue exists when viewing/modifying the files outside of the docker in unRAID. The docker user (nobody) has rw permission on all created files. The issue arises when I'm trying to manage the created files from another PC attached through the network that doesn't use the nobody user for access so unraid deny any attempt to rename/move the files until I adjust permissions. I expect that the group bits need write permission to work properly (all unraid accounts are group users afaik).
-
Hi All, The Plex docker is creating files on my system (when creating optimized versions) with correct user/group, but incorrect permissions (0444). Wondering if there's a way to fix the Plex docker to create new files with 0666, or just run docker-safe new perms automatically with user scripts once a week or something? Any ideas?
-
Same deal here - works fine when run manually, but when it tries to run automatically it logs a failed test.
-
Edit: Fixed it Execute bit was not set on /config/Library/Application Support/Plex Media Server/Codecs/EasyAudioEncoder-527-linux-x86_64/EasyAudioEncoder/EasyAudioEncoder for what reason, I have no idea. chmod a+x for the file above fixed it. Dunno if it needed an "a", but since it worked, yay.

-
Getting this error now, not sure why, but seems to be related to downmixing multi-channel audio to fewer tracks? Can't play through web player or mobile devices, but works OK on AppleTV or Roku that support multichannel natively. Any ideas? Running linuxserver/plex:amd64-1.18.7.2457-77cb9455c-ls80
-
Unfortunately it also broke my speedtest with python. In my case, the solution was to uninstall nerdpack, delete the directory from the flash drive/plugins to force a re-download of the packages and reinstall everything. Fixed now.
-
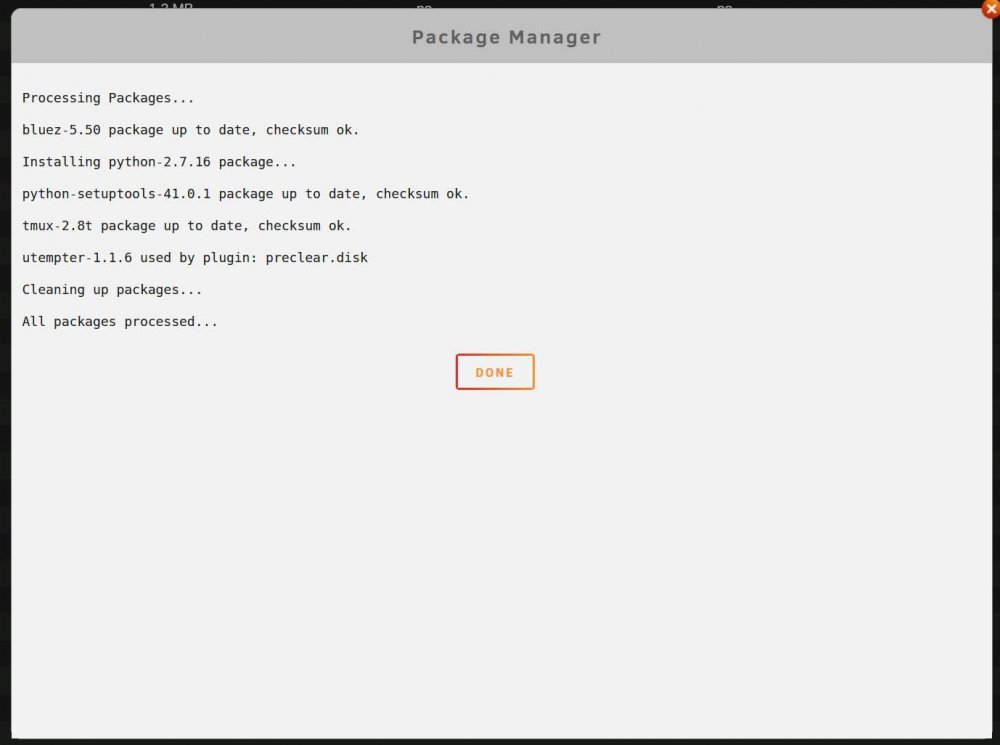
Having a problem where it's showing a Python2 update available, but nothing happens when I try the update. Same for other packages that show updates - nothing actually happens when I try the update. Running unRAID v.6.7.2
-
My wife is annoyed how much I love my unRAID server, but it just works.
-
Great plugin, handy to save from fat fingers when deleting files and such. One request (may be a longshot, but you never know) - rather than adding a list of shares that you don't want enabled, would it be possible to flip it so there's a list of only shares you want active? Or maybe both? Just throwing it out there, I can deal either way. Cheers!
-
Worked here as a fix, thanks a bunch!




